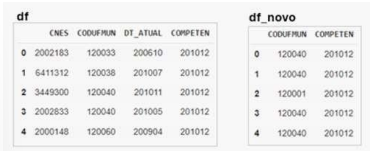
Questões de Concurso
Sobre python em programação
Foram encontradas 852 questões
( ) No Oracle R Enterprise, a execução do R incorporado (ou Embedded R) possibilita a chamada de scripts do R em sessões do R executadas no servidor do Oracle Database.
( ) A interoperabilidade entre Python e R pode ser estabelecida pelo pacote reticulate do R, que possibilita que no código R sejam utilizadas ambas as abordagens, em documentos R Markdown e no IDE RStudio.
( ) Os principais pacotes para manipulação de dados são o dplyr, para o R, e o Scikit-learn, para o Python.
As afirmativas são, respectivamente,
I. Python suporta orientação a objetos, permitindo a criação de classes, herança, encapsulamento e polimorfismo.
II. Python suporta programação funcional, incluindo o uso de funções de alta ordem como map, filter e reduce.
III. Em Python, todas as variáveis declaradas dentro de uma função são automaticamente globais e podem ser acessadas em qualquer parte do código.
IV. O uso de ponto e vírgula (;) ao final de cada linha é obrigatório em Python para indicar o final de uma instrução.
I. Na linguagem Python, por convenção, nomes em caixa-alta são utilizados para indicar que uma variável deve ser tratada como constante, apesar do Python permitir que seus valores sejam modificados.
II. Na linguagem Java, a palavra-chave "const" é utilizada para definir constantes, garantindo que o valor não possa ser alterado.
nomes = [ Ana , Bruno , Carla ]
É correto afirmar que a linha de código
s = a .join(nomes)
irá armazenar na variável s o valor:
Observe a tabela de Operadores Relacionais a seguir.

Observe a tabela de operadores lógicos a seguir.

Com relação aos operadores das linguagens de programação, julgue o item.
Os operadores lógicos apresentados são apenas da Linguagem Python; na Linguagem C, há outros.
Observe a tabela de Operadores Relacionais a seguir.
Observe a tabela de operadores lógicos a seguir.
Com relação aos operadores das linguagens de programação, julgue o item.
Os operadores lógicos são apenas da Linguagem C; na Linguagem Python, há outros.
Observe a tabela de Operadores Relacionais a seguir.
Observe a tabela de operadores lógicos a seguir.
Com relação aos operadores das linguagens de programação, julgue o item.
São operadores apenas da Linguagem Python.
Observe a tabela de Operadores Relacionais a seguir.
Observe a tabela de operadores lógicos a seguir.
Com relação aos operadores das linguagens de programação, julgue o item.
São operadores da Linguagem C e Python.
Com base nas linguagens de programação Python, julgue o próximo item.
Considere o seguinte código em Python: tupla = ('a', ['b', 'c', 'd']) tupla[1].append('e')
O código acima resultará em erro, pois tuplas são imutáveis e não permitem adição de elementos.
Com base nas linguagens de programação Python, julgue o próximo item.
Considere o seguinte código em Python:
lista = [1, 2, 3, 4, 5]
lista1 = lista
lista1[0] = 99
Ao final da execução do código, o conteúdo da variável lista será:
[99, 2, 3, 4, 5]