Questões de Concurso Sobre banco de dados
Foram encontradas 18.739 questões
I.Uma subconsulta correlacionada em um comando UPDATE pode referenciar colunas da tabela da consulta externa dentro da subconsulta interna.
II.Em subconsultas correlacionadas, a consulta interna é executada uma única vez e seu resultado é reutilizado para todas as linhas da tabela externa.
III.O uso de subconsultas correlacionadas em UPDATE impede a utilização da cláusula WHERE dentro da subconsulta.
É correto o que se afirma em:
Considere o comando: UPDATE tabela SET col1 = col2, col2 = col1;
Aplicado a uma linha onde col1 = 1 e col2 = 2.
Analise as afirmativas a seguir:
I.O resultado final da execução será col1 = 2 e col2 = 1, caracterizando a troca de valores entre as colunas.
II.Durante a execução do UPDATE, as atribuições da cláusula SET são avaliadas sequencialmente, de modo que a segunda atribuição utiliza o valor já atualizado na primeira.
III.A execução do comando resulta em erro devido a uma referência circular entre as colunas.
É correto o que se afirma em:
I.O uso de Prepared Statements (consultas parametrizadas) separa a lógica do comando SQL dos dados fornecidos, evitando que a entrada do usuário seja interpretada como código.
II.O ataque de SQL Injection pode ocorrer em diferentes tipos de comandos SQL, como SELECT, INSERT, UPDATE e DELETE.
III.O uso de ORMs (Object-Relational Mappers) elimina completamente o risco de SQL Injection, independentemente da forma como as consultas são construídas.
É correto o que se afirma em:
Um analista de dados de uma agência reguladora está desenvolvendo um painel para monitorar indicadores de desempenho do setor. Ele está utilizando uma ferramenta de BI que envolve um processo de ETL (Extração, Transformação e Carga) para preparar os dados.
Analise as seguintes proposições sobre as etapas do processo de BI:
I. Extração (Extract): É a fase de coleta de dados de diversas fontes, que podem ser bancos de dados relacionais (SQL Server, Oracle), planilhas (Excel), arquivos de texto (CSV), serviços web (APIs), entre outros.
II. Transformação (Transform): Nesta fase, os dados extraídos são limpos, padronizados, combinados e modelados. Podem ser realizadas operações como remoção de duplicatas, cálculo de novas colunas e criação de hierarquias para preparar os dados para a análise.
III. Carga (Load): Após a transformação, os dados são carregados no modelo de dados da ferramenta de BI (como o Power BI ou Qlik Sense), onde ficarão disponíveis para a criação de relatórios e dashboards interativos.
Está correto o que se afirma em:
Um analista precisa extrair dados de diferentes tabelas do Sistema Integrado de Administração Financeira (SIAFI) para gerar um relatório complexo sobre despesas com pessoal. O relatório deve combinar informações de servidores, lotações, remunerações e descontos. Para isso, ele precisa construir uma consulta SQL avançada que utilize diferentes tipos de junções (JOINs).
Associe os tipos de junções SQL da Coluna A com suas respectivas descrições e resultados na Coluna B, no contexto da consulta ao banco de dados do SIAFI.
Coluna A
1. INNER JOIN
2. LEFT JOIN (ou LEFT OUTER JOIN)
3. FULL OUTER JOIN
4. CROSS JOIN
Coluna B (__) Retorna todos os registros da tabela de servidores (à esquerda) e os registros correspondentes da tabela de remunerações (à direita). Se um servidor não tiver remuneração registrada no período, seus dados ainda aparecerão no resultado, com valores nulos para as colunas de remuneração. (__) Retorna o produto cartesiano entre a tabela de categorias de despesa e a tabela de fontes de recurso, combinando cada categoria com cada fonte, sendo útil para criar um universo de todas as combinações possíveis para análise de cenários orçamentários. (__) Retorna apenas os registros que possuem correspondência em ambas as tabelas, por exemplo, ao combinar a tabela de servidores com a de lotações, o resultado incluirá apenas os servidores que têm uma lotação válida e ativa registrada no sistema. (__) Retorna todos os registros quando há uma correspondência em qualquer uma delas, preenchendo com valores nulos as lacunas onde não houver match. Por exemplo, ao unir a tabela de empenhos e a tabela de pagamentos, o resultado mostraria todos os empenhos (mesmo os não pagos) e todos os pagamentos (mesmo os de empenhos de exercícios anteriores).
A sequência correta de preenchimento dos parênteses, de cima para baixo, é:
O Portal da Transparência do Governo Federal precisa lidar com um volume massivo e crescente de dados heterogêneos, como despesas, receitas, contratos e informações sobre servidores. A arquitetura de dados atual, baseada em um modelo puramente relacional, enfrenta desafios de desempenho e flexibilidade para incorporar novas fontes de dados.
Analise as seguintes proposições sobre a aplicação de bancos de dados NoSQL para solucionar os desafios do Portal da Transparência:
I. Bancos de dados relacionais são inerentemente superiores aos NoSQL para cenários de Big Data e dados heterogêneos, pois a rigidez do esquema e o suporte a transações ACID garantem melhor desempenho em consultas analíticas complexas.
II. A adoção de um banco de dados NoSQL orientado a documentos permitiria armazenar os dados de cada fonte (despesas, contratos, etc.) em seus formatos originais (JSON, por exemplo), facilitando a ingestão e a evolução do modelo de dados sem a necessidade de migrações de esquema complexas.
III. A escalabilidade horizontal, uma característica comum em muitos SGBDs NoSQL, seria um benefício chave, permitindo que a infraestrutura do portal cresça de forma mais elástica e com menor custo para acompanhar o aumento do volume de dados e do número de acessos.
Está correto o que se afirma em:
Para lidar com o grande volume e a complexidade dos dados do Big Data, foram desenvolvidas tecnologias e frameworks específicos, que superam as limitações dos sistemas de bancos de dados tradicionais. Um analista de dados de um órgão de pesquisa precisa processar um grande conjunto de dados não estruturados.
Analise as seguintes proposições sobre as tecnologias de Big Data:
I. O Hadoop é um framework de código aberto que permite o processamento distribuído de grandes conjuntos de dados em clusters de computadores. Seus componentes principais são o HDFS (Hadoop Distributed File System), para armazenamento distribuído, e o MapReduce, para o processamento paralelo.
II. O MapReduce é um modelo de programação onde a tarefa é dividida em duas fases: a fase 'Map', que processa e mapeia os dados de entrada em pares de chave-valor, e a fase 'Reduce', que agrega os resultados intermediários da fase 'Map' para produzir o resultado final.
III. O Spark é outro framework de processamento distribuído que, embora compatível com o ecossistema Hadoop, é conhecido por ser significativamente mais rápido, pois realiza o processamento em memória (in-memory), sendo ideal para aplicações de aprendizado de máquina e processamento de dados em tempo real.
Está correto o que se afirma em:
Em uma instituição de ensino superior, foi necessário criar um banco de dados para controlar os projetos científicos e a participação dos pesquisadores. Para isso, foram criadas as tabelas Pesquisador, Area_Conhecimento e Projeto por meio dos scripts SQL abaixo:
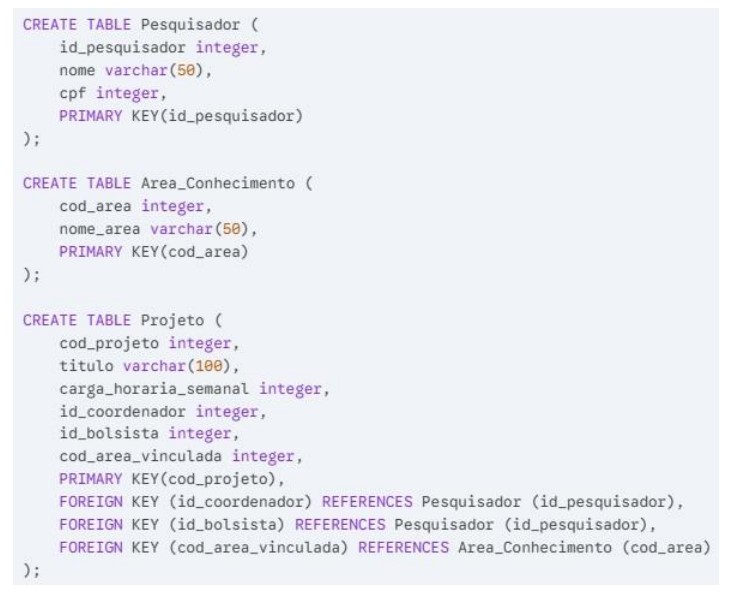
Deseja-se listar o nome dos pesquisadores que atuam como bolsistas, juntamente com a carga horária semanal dos projetos, exibindo apenas registros com correspondência entre as tabelas e ordenando em ordem decrescente de carga horária.
Assinale a alternativa correta:
Em um sistema corporativo de gestão de pessoas, os dados dos colaboradores estão distribuídos em diferentes entidades relacionais, de forma a garantir integridade e evitar redundâncias. Um analista precisa construir uma consulta que permita extrair informações consolidadas para fins gerenciais. Considere as seguintes tabelas:
● TABELA_PESSOAS (ID_PESSOA, NOME, CPF)
● TABELA_CONTRATOS (MATRICULA, ID_PESSOA, SALARIO, COD_SETOR)
● TABELA_SETORES (COD_SETOR, NOME_SETOR)
O analista elaborou a seguinte consulta SQL:

Com base na consulta apresentada e no comportamento dos operadores relacionais em SQL padrão, analise as afirmativas a seguir:
I. A consulta retornará exclusivamente colaboradores que possuam contrato com remuneração superior a 2000 e que estejam vinculados a um setor válido cadastrado, excluindo implicitamente quaisquer registros com ausência de correspondência nas tabelas relacionadas.
II. Caso existam contratos com o campo COD_SETOR nulo ou com valores que não possuam correspondência na tabela de setores, tais registros serão desconsiderados no resultado, ainda que atendam ao critério de remuneração.
III. Ao realizar um RIGHT JOIN entre a TABELA_PESSOAS e a TABELA_CONTRATOS, o SQL Server garantirá que todos os registros de pessoas sejam exibidos no resultado final, mesmo aqueles que não possuem contrato vinculado, preenchendo os campos da tabela de contratos com valores NULL.
IV. A consulta apresentada pode retornar colaboradores que não possuem registro correspondente na TABELA_CONTRATOS, desde que estejam cadastrados na TABELA_PESSOAS e atendam ao critério de salário informado.
Assinale a opção correta:
Sobre a arquitetura de dados e o dicionário de metadados do ecossistema TOTVS RM, analise as afirmativas abaixo, marcando V para as verdadeiras e F para as falsas:
( ) O dicionário de dados que armazena as informações de metadados das tabelas e colunas do sistema é composto, primordialmente, pelas tabelas GTABELA e GCAMPOS.
( ) A tabela GLINKSREL armazena os relacionamentos (Foreign Keys) lógicos entre as tabelas do sistema, sendo essencial para a construção de consultas complexas e relatórios.
( ) Para garantir a integridade referencial e os gatilhos internos (triggers) do framework, a criação de um novo registro de usuário deve ser feita exclusivamente via interface ou APIs (DataServers), sendo a prática de Insert direto na tabela GUSUARIO altamente desencorajada por não garantir a persistência em tabelas satélites de segurança.
( ) A tabela GAUTOINC é responsável por armazenar as definições de chaves primárias e índices de performance (Indexes) das tabelas físicas no banco de dados.
Assinale a alternativa que contém a sequência correta:
Observe as tabelas abaixo:

O código que retornará como resultado um produto cartesiano entre tb_livro e tb_autor é:
1. _____________: A transação deve ser concluída em sua totalidade ou não ocorrer de forma alguma.
2. _____________: A transação deve levar o banco de dados de um estado consistente a outro estado consistente.
3. _____________: As operações de uma transação não devem ser visíveis para outras transações até que estejam completas.
4. _____________: Uma vez que a transação é concluída, suas mudanças persistem, mesmo em caso de falha do sistema.
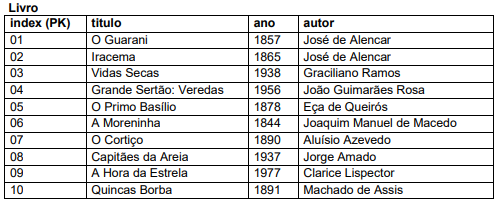
I. O comando "SELECT titulo FROM Livro WHERE ano > 1900;" retornaria os valores Vidas Secas, Grande Sertão: Veredas, Capitães da Areia e A Hora da Estrela.
II. O comando "SELECT titulo FROM Livro WHERE autor IN (SELECT autor FROM Livro GROUP BY autor HAVING COUNT(titulo) > 1);" retornaria os valores O Guarani, Iracema, O Primo Basílio e Quincas Borba.
III. O comando "SELECT ano FROM Livro WHERE ano < 1870;" retornaria os valores O Guarani, Iracema e A Moreninha.
IV. O comando "SELECT titulo FROM Livro WHERE autor >= 'A' AND autor < 'I';" retornaria os valores O Cortiço, A Hora da Estrela, O Primo Basílio e Vidas Secas.
1. Atributo ___________: Pode ser subdividido em outros atributos.
2. Atributo ___________: Pode conter vários valores para uma entidade.
3. Atributo ___________: Valor que pode ser derivado de outros atributos.
I. A análise de cardinalidade em uma coluna consiste em identificar o número de valores distintos presentes, sendo útil para reconhecer possíveis chaves candidatas e detectar colunas com baixa variabilidade que podem indicar problemas de qualidade.
II. O profiling de nulidade verifica a proporção de valores ausentes em cada coluna, fornecendo informações relevantes para decisões sobre estratégias de tratamento, como imputação, exclusão de registros ou criação de indicadores de ausência.
III. A análise de distribuição de frequência permite identificar quais valores ocorrem com maior regularidade em uma coluna e é aplicável exclusivamente a colunas com tipos de dados numéricos, não sendo útil para colunas do tipo texto ou categórico.
IV. O profiling básico, por ser uma análise estática realizada antes da ingestão, elimina a necessidade de validações de qualidade posteriores durante as fases de transformação e carga, desde que o dataset analisado não sofra alterações estruturais.
Estão CORRETAS: