Questões de Concurso
Sobre índices em banco de dados
Foram encontradas 194 questões
Ano: 2026
Banca:
FGV
Órgão:
AL-RO
Prova:
FGV - 2026 - AL-RO - Analista Legislativo (Engenharia de Computação) |
Q3882838
Banco de Dados
Um engenheiro de computação está otimizando uma consulta
lenta em um SGBD. Ele percebe que o plano de execução mostra
uma varredura completa da tabela em uma tabela de milhões de
tuplas.
A ação de tunning mais provável para forçar o SGBD a usar um método de busca mais eficiente é
A ação de tunning mais provável para forçar o SGBD a usar um método de busca mais eficiente é
Ano: 2026
Banca:
FGV
Órgão:
AL-GO
Prova:
FGV - 2026 - AL-GO - Analista Legislativo - Analista de Infraestrutura |
Q3881247
Banco de Dados
Os índices são estruturas de dados no banco de dados relacionais
que demandam uma manutenção específica para manter os dados
organizados. No SQL Server, a fragmentação e a densidade da
página estão entre os fatores que os analistas da ALEGO devem
considerar ao decidir se a manutenção do índice deve ser
executada e qual método de manutenção será usado. Com relação
aos conceitos de fragmentação e densidade de página, analise as
alternativas a seguir.
I. Quando a densidade da página for baixa, mais páginas serão necessárias para armazenar uma mesma quantidade de dados. Isso significa que mais operações de E/S serão necessárias para ler e gravar esses dados, assim como mais espaço em memória será necessária para armazenar esses dados em cache. Quando a memória é limitada, menos páginas exigidas por uma consulta serão armazenadas em cache, causando ainda mais operações de E/S em disco. Consequentemente, a densidade de página baixa afeta negativamente o desempenho.
II. O mecanismo de banco de dados modifica os índices automaticamente sempre que são executadas operações de inserção, atualização ou exclusão nos dados subjacentes. Por exemplo, a adição de linhas em uma tabela pode fazer com que as páginas existentes nos índices de columnstore se dividam, liberando espaço para a inserção de novas linhas. Com o decorrer do tempo, essas modificações podem fazer com que os dados do índice sejam fragmentados e dispersados pelo banco de dados.
III. Quando o otimizador de consulta do SQL Server compila um plano de consulta, ele considera o custo das operações de E/S necessárias para ler os dados exigidos pela consulta. Quando a densidade de página baixa, há mais páginas a serem lidas, portanto, o custo das operações de E/S será maior. Isso pode afetar a escolha do plano de consulta. Por exemplo, à medida que a densidade de página diminui ao longo do tempo devido a divisões de página, o otimizador pode compilar um plano diferente para a mesma consulta, com um perfil de consumo de recursos e desempenho diferente.
IV. Para as consultas SQL que leem muitas páginas usando varreduras de índices completas ou de intervalo, índices pouco fragmentados podem prejudicar o desempenho da consulta quando operações de E/S adicionais são necessárias para ler os dados. Em vez de algumas solicitações com poucas operações de E/S, a consulta exigiria muitas solicitações com poucas operações de E/S para ler a mesma quantidade de dados.
Está correto o que se afirma em
I. Quando a densidade da página for baixa, mais páginas serão necessárias para armazenar uma mesma quantidade de dados. Isso significa que mais operações de E/S serão necessárias para ler e gravar esses dados, assim como mais espaço em memória será necessária para armazenar esses dados em cache. Quando a memória é limitada, menos páginas exigidas por uma consulta serão armazenadas em cache, causando ainda mais operações de E/S em disco. Consequentemente, a densidade de página baixa afeta negativamente o desempenho.
II. O mecanismo de banco de dados modifica os índices automaticamente sempre que são executadas operações de inserção, atualização ou exclusão nos dados subjacentes. Por exemplo, a adição de linhas em uma tabela pode fazer com que as páginas existentes nos índices de columnstore se dividam, liberando espaço para a inserção de novas linhas. Com o decorrer do tempo, essas modificações podem fazer com que os dados do índice sejam fragmentados e dispersados pelo banco de dados.
III. Quando o otimizador de consulta do SQL Server compila um plano de consulta, ele considera o custo das operações de E/S necessárias para ler os dados exigidos pela consulta. Quando a densidade de página baixa, há mais páginas a serem lidas, portanto, o custo das operações de E/S será maior. Isso pode afetar a escolha do plano de consulta. Por exemplo, à medida que a densidade de página diminui ao longo do tempo devido a divisões de página, o otimizador pode compilar um plano diferente para a mesma consulta, com um perfil de consumo de recursos e desempenho diferente.
IV. Para as consultas SQL que leem muitas páginas usando varreduras de índices completas ou de intervalo, índices pouco fragmentados podem prejudicar o desempenho da consulta quando operações de E/S adicionais são necessárias para ler os dados. Em vez de algumas solicitações com poucas operações de E/S, a consulta exigiria muitas solicitações com poucas operações de E/S para ler a mesma quantidade de dados.
Está correto o que se afirma em
Ano: 2026
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2026 - IF-SP - Analista de Tecnologia da Informação |
Q3853064
Banco de Dados
No contexto do PostgreSQL 17, qual das alternativas a seguir descreve corretamente uma característica dos índices B-Tree?
Ano: 2026
Banca:
FGV
Órgão:
AMAZUL
Prova:
FGV - 2026 - AMAZUL - Analista de Desenvolvimento de Sistemas |
Q3851188
Banco de Dados
Em um banco de dados MySQL, o otimizador de consultas decide
qual é a melhor forma de executar uma query. Para analisar o
plano de execução e identificar gargalos de performance, assinale
a opção que apresenta o comando SQL que é utilizado, e
informação específica que pode indicar a necessidade de criação
de um índice.
Ano: 2025
Banca:
UNIVALI
Órgão:
Prefeitura de Luiz Alves - SC
Prova:
UNIVALI - 2025 - Prefeitura de Luiz Alves - SC - Técnico em Manutenção e Suporte de Informática - Edital nº 12 |
Q4032553
Banco de Dados
Em Sistemas Gerenciadores de Bancos de Dados
(SGBDs), a indexação é vital para otimizar o
desempenho das consultas. A estrutura de índice mais
utilizada em bancos de dados relacionais para consultas
de intervalo e buscas pontuais é a Árvore B+ (B+-tree).
Essa estrutura é uma árvore de busca balanceada que
difere da Árvore B clássica por armazenar todos os
valores de dados (ou ponteiros para os dados)
exclusivamente nos nós folha, mantendo os nós internos
apenas com chaves de navegação. Qual é a principal
vantagem de manter todos os registros de dados ou
ponteiros apenas nos nós folha em uma Árvore B+?
Ano: 2025
Banca:
Instituto IDEAP
Órgão:
Prefeitura de Monte Alegre de Minas - MG
Prova:
Instituto IDEAP - 2025 - Prefeitura de Monte Alegre de Minas - MG - Técnico em Informática |
Q3802510
Banco de Dados
Durante a implementação de um sistema de
banco de dados relacional em uma instituição pública,
o técnico precisa projetar a estrutura de tabelas,
definir chaves, aplicar normalização e otimizar
consultas.
Sobre os fundamentos e a implementação de bancos de dados, analise as alternativas abaixo e assinale a correta:
Sobre os fundamentos e a implementação de bancos de dados, analise as alternativas abaixo e assinale a correta:
Ano: 2025
Banca:
FGV
Órgão:
CGE-SP
Prova:
FGV - 2025 - CGE-SP - Auditor Estadual de Controle - Tecnologia da Informação - tarde |
Q3781121
Banco de Dados
O pipeline que carrega dados de execução orçamentária do
sistema operacional para o Data Warehouse deve garantir que o
volume de dados seja carregado no ambiente analítico de forma
eficiente, seguindo todas as transformações já aplicadas.
Assinale a opção que apresenta a principal responsabilidade e o desafio da fase Load no processo ETL, especialmente em relação ao design de índice e particionamento da Tabela de Fato.
Assinale a opção que apresenta a principal responsabilidade e o desafio da fase Load no processo ETL, especialmente em relação ao design de índice e particionamento da Tabela de Fato.
Ano: 2025
Banca:
FGV
Órgão:
CGE-SP
Prova:
FGV - 2025 - CGE-SP - Auditor Estadual de Controle - Tecnologia da Informação - tarde |
Q3781117
Banco de Dados
Um DBA está avaliando o desempenho de uma consulta que
frequentemente busca dados na tabela Auditoria (com 500
milhões de registros) usando a coluna DataHora_Acesso na
cláusula WHERE. O DBA decide criar um índice clusterizado nessa
coluna (após remover o índice existente na chave primária
autoincremento, se necessário).
Assinale a opção que apresenta a principal implicação técnica de criar um índice clusterizado na coluna DataHora_Acesso de uma tabela tão grande no MS SQL Server, e a consequência direta para a ordenação física dos dados.
Assinale a opção que apresenta a principal implicação técnica de criar um índice clusterizado na coluna DataHora_Acesso de uma tabela tão grande no MS SQL Server, e a consequência direta para a ordenação física dos dados.
Ano: 2025
Banca:
FGV
Órgão:
CGE-SP
Prova:
FGV - 2025 - CGE-SP - Auditor Estadual de Controle - Tecnologia da Informação - tarde |
Q3781111
Banco de Dados
Uma consulta SQL que realiza múltiplos JOINs e filtros sobre
tabelas grandes está apresentando lentidão.
As opções a seguir apresentam estratégias recomendadas para otimização, à exceção de uma. Assinale-a.
As opções a seguir apresentam estratégias recomendadas para otimização, à exceção de uma. Assinale-a.
Ano: 2025
Banca:
FGV
Órgão:
CGE-SP
Prova:
FGV - 2025 - CGE-SP - Auditor Estadual de Controle - Tecnologia da Informação - tarde |
Q3781109
Banco de Dados
No SQL Server, uma das práticas recomendadas para otimizar o
desempenho de consultas complexas, é o uso de índices
compostos. Considere a seguinte situação:
Uma tabela de vendas (Vendas) contém as colunas data_venda, id_cliente, valor_total. Deseja-se otimizar a consulta que filtra registros por id_cliente e ordena por data_venda.
Assinale a opção que indica a configuração de índice mais adequada.
Uma tabela de vendas (Vendas) contém as colunas data_venda, id_cliente, valor_total. Deseja-se otimizar a consulta que filtra registros por id_cliente e ordena por data_venda.
Assinale a opção que indica a configuração de índice mais adequada.
Ano: 2025
Banca:
IBADE
Órgão:
Prefeitura de Castelo - ES
Prova:
IBADE - 2025 - Prefeitura de Castelo - ES - Analista de Sistemas |
Q3765801
Banco de Dados
Em bancos relacionais, o otimizador escolhe planos a partir
de estimativas e estruturas de acesso. Assinale a
alternativa que representa estratégia consistente para
consulta com predicado por intervalo e ordenação por
duas colunas.
Q3755891
Banco de Dados
Considerando a figura a seguir, que apresenta como exemplo um índice para uma tabela de pinturas em um
banco de dados, o ponteiro de número 4 se refere a qual item da coluna “Painting_Title"?
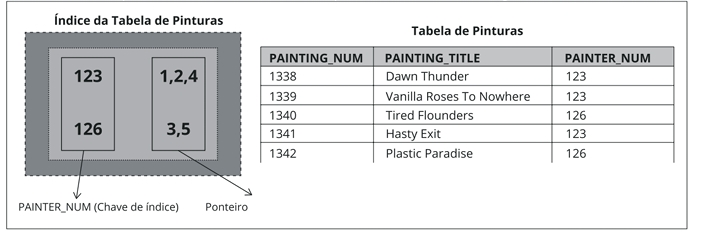
Fonte: adaptado de Rob e Coronel (2011). Disponivel em: https://www.univates.br/revistas/index.php/destaques/article/view/498/490.
Fonte: adaptado de Rob e Coronel (2011). Disponivel em: https://www.univates.br/revistas/index.php/destaques/article/view/498/490.
Ano: 2025
Banca:
FGV
Órgão:
CPRM
Prova:
FGV - 2025 - CPRM - Analista em Geociências - Análise e Desenvolvimento de Sistemas |
Q3755428
Banco de Dados
No contexto de tuning de consultas em bancos de dados
relacionais, certas práticas podem introduzir sobrecarga
desnecessária ou impedir o uso eficiente de índices.
Assinale a opção que corresponde a uma prática que deve ser evitada por resultar, em geral, em pior desempenho.
Assinale a opção que corresponde a uma prática que deve ser evitada por resultar, em geral, em pior desempenho.
Q3753096
Banco de Dados
Considere a seguinte situação hipotética:
Um sistema acadêmico armazena milhões de registros na tabela usuario, e as consultas que filtram pela coluna email estão apresentando lentidão significativa. Para otimizar o desempenho dessas consultas, o desenvolvedor decide criar um índice específico para essa coluna.
Considerando o SGBD PostgreSQL 15, assinale a alternativa que o desenvolvedor deve utilizar para criar CORRETAMENTE o índice:
Um sistema acadêmico armazena milhões de registros na tabela usuario, e as consultas que filtram pela coluna email estão apresentando lentidão significativa. Para otimizar o desempenho dessas consultas, o desenvolvedor decide criar um índice específico para essa coluna.
Considerando o SGBD PostgreSQL 15, assinale a alternativa que o desenvolvedor deve utilizar para criar CORRETAMENTE o índice:
Ano: 2025
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2025 - BRDE - Analista de Sistemas - Subárea Administração de Banco de Dados |
Q3696963
Banco de Dados
Uma query que junta as tabelas Vendas (10.000 linhas) e Clientes (1.000 linhas)
está performando mal. Ambas as tabelas têm índices nas colunas de junção (cliente_id). Analisando
o plano de execução, o DBA verifica que o otimizador escolheu um Nested Loops Join. Em qual cenário
essa escolha é a mais adequada?
Ano: 2025
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2025 - BRDE - Analista de Sistemas - Subárea Administração de Banco de Dados |
Q3696960
Banco de Dados
Ao analisar um plano de execução no PostgreSQL usando EXPLAIN ANALYZE, um DBA
observa uma operação Sequential Scan em uma tabela grande para uma query que deveria usar um
índice. Qual é a causa mais provável para o otimizador ter escolhido o acesso sequencial completo em
vez do índice?
Ano: 2025
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2025 - BRDE - Analista de Sistemas - Subárea Administração de Banco de Dados |
Q3696956
Banco de Dados
Ao analisar o plano de execução de uma query lenta, um DBA observa a operação
TABLE ACCESS FULL sobre uma tabela grande. A query frequentemente filtra resultados usando uma
cláusula WHERE em uma coluna data_cadastro. Não existem índices nesta coluna. Qual seria a ação
mais direta e efetiva para melhorar o desempenho desta query?
Ano: 2025
Banca:
FUNDATEC
Órgão:
BRDE
Prova:
FUNDATEC - 2025 - BRDE - Analista de Sistemas - Subárea Administração de Banco de Dados |
Q3696955
Banco de Dados
Um DBA é chamado para analisar uma query de relatório que está executando
lentamente. A query filtra registros usando a cláusula WHERE em uma coluna status que possui apenas
5 valores distintos ('A', 'I', 'P', 'C', 'X') em uma tabela com 10 milhões de linhas. A distribuição dos
valores é muito desigual: 9.9 milhões têm status 'A' e os outros 100 mil estão distribuídos entre os
demais status. Qual tipo de índice seria mais eficiente para acelerar consultas que buscam por um dos
valores menos frequentes, como WHERE status = 'P'?
Ano: 2025
Banca:
CESPE / CEBRASPE
Órgão:
TCE-RS
Prova:
CESPE / CEBRASPE - 2025 - TCE-RS - Auditor de Controle Externo (ACE )- Especialidade: Tecnologia da Informação |
Q3684262
Banco de Dados
Em relação a ferramentas de busca, indexação e análise de dados, julgue o item subsecutivo.
O Elasticsearch permite a divisão de um índice em subpartes denominadas shards, as quais devem ser remontadas para se tornarem funcionais, uma vez que não podem ser utilizadas isoladamente.
Ano: 2025
Banca:
CESPE / CEBRASPE
Órgão:
TCE-RS
Prova:
CESPE / CEBRASPE - 2025 - TCE-RS - Auditor de Controle Externo (ACE )- Especialidade: Tecnologia da Informação |
Q3684255
Banco de Dados
Acerca de otimização de desempenho de sistemas gerenciadores de banco de dados (SGBD) e de consultas SQL, julgue o item subsequente.
Em um SGBD, o índice de seletividade representa a eficiência de acesso aos dados, sendo a alta seletividade mais eficaz que a baixa seletividade para localizar os dados.