Questões de Concurso
Comentadas sobre data mining em banco de dados
Foram encontradas 523 questões
Acerca de mineração de dados (data mining), julgue o item a seguir.
A mineração de dados não se limita às técnicas de obtenção
de dados, envolvendo também a observação de padrões nos
dados obtidos.
Acerca de mineração de dados (data mining), julgue o item a seguir.
No procedimento de limpeza de dados (data cleaning),
identifica-se ausência de valores quando um conjunto de
dados apresenta apenas dados agregados em relação a
certo atributo.
A mineração de processos é um ramo da mineração de dados que utiliza inteligência de negócios para prever tendências, ajudando tomadores de decisão a estudarem o impacto de suas decisões no futuro da organização.
Acerca da mineração de dados, julgue o item seguinte.
A mineração de dados é um processo cujos alicerces são
aprendizado de máquina, análises estatísticas e volumes de
dados.
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
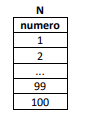
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
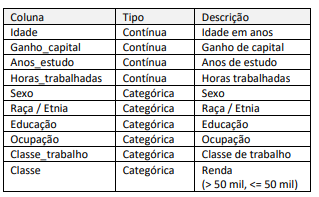
O conjunto de dados PESSOA será usado para a tarefa de aprendizagem supervisionada de classificação com a finalidade de prever se a renda (Classe) de uma pessoa excede 50 mil por ano.
Para isso, a operação de pré-processamento de dados que deve ser executada no conjunto de dados PESSOA é:
No que se refere a data mining, julgue o próximo item.
Na etapa de preparação de dados do modelo CRISP-DM,
ocorre a identificação dos dados existentes, com suas
respectivas características.
No que se refere a data mining, julgue o próximo item.
Na fase de análise de um projeto de data mining, uma das
técnicas utilizadas é a associação, cuja finalidade é
determinar um grau de afinidade entre eventos distintos.
Julgue o item a seguir, a respeito de inteligência artificial (IA) e machine learning.
K-means é um algoritmo de aprendizado não supervisionado,
em que se calcula a distância entre os objetos da base e cada
um dos centroides; em que se atribui cada objeto ao
centroide mais próximo; e em que se classifica cada item
para sua média mais próxima.
A medida de confiança de uma regra de associação é calculada pela frequência com que tal regra aparece em transações individuais na base de dados transacional.
I. Data Mining faz a varredura de uma pequena quantidade de dados de cada vez. II. Business Intelligence atua na parte física de infraestrutura. III. Data Mining também é conhecido como mineração de dados. IV. Business Intelligence passou a ser tratado como uma aplicação de estratégia integrada.
1. Seleção de dados 2. Limpeza de dados 3.Mineração de dados 4. Avaliação
( ) São aplicados algoritmos para extração de características dos dados.
( ) O subconjunto objetivado dos dados e os atributos de interesse são identificados examinando-se o conjunto de dados bruto inteiro.
( ) Os padrões são apresentados para os usuários em uma forma inteligível.
( ) Ruído e exceções são removidos, valores de campo são transformados em unidades comuns e alguns campos são criados pela combinação de campos já existentes para facilitar a análise. Normalmente, os dados são colocados em um formato relacional, e várias tabelas podem ser combinadas em uma etapa de desnormalização.
Assinale a alternativa que apresenta a numeração CORRETA da coluna da direita, de cima para baixo, conforme Raghu e Gehrke (2011, p. 739):
Sendo assim, na primeira abordagem, Carla utilizou como base o algoritmo de machine learning: