Questões de Concurso
Sobre algoritmos em algoritmos e estrutura de dados
Foram encontradas 2.316 questões
Para grandes volumes de dados, um algoritmo com complexidade de tempo O(n) (linear) é considerado menos eficiente que um algoritmo com complexidade de tempo O(n log n), uma vez que o crescimento linear é mais acentuado que o crescimento logarítmico.

Em relação à matriz de distância gerada, assinale a alternativa correta.
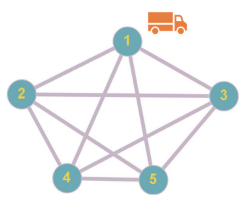
Assinale a alternativa que apresenta a categoria de análise espacial na qual esse problema se encaixa.
Considere dois algoritmos que resolvem o mesmo problema.
Entretanto, o algoritmo A tem complexidade O(n2), enquanto o algoritmo B, tem complexidade O(n log n), em que n representa o tamanho da entrada.
Em termos de desempenho assintótico, acerca desses algoritmos, ¢ correto afirmar que
Observe o código Python a seguir.

A partir do código apresentado, que implementa um algoritmo de ordenação, a função metodo_ordenacao que implementa o algoritmo é
Observe o algoritmo da figura.

A execução desse algoritmo irá gerar como saída a matriz indicada na seguinte opção:
Considere o seguinte trecho de código em Python construído por um desenvolvedor:
def soma_parcial(lista):
total = 0
for i in range(len(lista)):
if lista[i] % 2 == 0:
total += lista[i]
return total
Sabendo que lista é não vazia e contém n inteiros, assinale a alternativa que apresenta a Complexidade do Algoritmo no melhor e no pior caso, respectivamente.
Considere o seguinte trecho de código em Python construído por um desenvolvedor:
def busca(lista, alvo):
for i in range(len(lista)):
if lista[i] == alvo:
return i
return -1
Diante do exposto, assinale a alternativa que apresenta a Complexidade do Algoritmo no melhor e no pior caso, respectivamente.

Após a execução, será gerada, como resultado, a seguinte sequência de números:
I Essa categoria de algoritmos da análise supervisionada realiza a classificação dos dados em um número limitado de classes, de modo a utilizar apenas os valores das variáveis de entrada como base.
II As árvores de decisão são mais apropriadas para dados categóricos e intervalares, portanto, o uso de variáveis contínuas em árvores de decisão requer a discretização, que consiste na transformação de variáveis numéricas contínuas em intervalos ou categorias.
III O algoritmo Random Forest utiliza o método bagging para a criação de múltiplas árvores de decisão independentes e combina as previsões para melhorar a precisão e reduzir o risco de overfitting.
Assinale a opção correta.

O algoritmo de busca binária apresentado anteriormente possui
A respeito do CMMI 2.0 e do MPS.BR Referência Guia Geral MPS Software 2023, julgue o item subsequente.
No CMMI, os níveis de capacidade estão estruturados do nível 0 ao nível 4 e indicam o grau de maturidade de áreas de processo individuais no modelo por estágio.
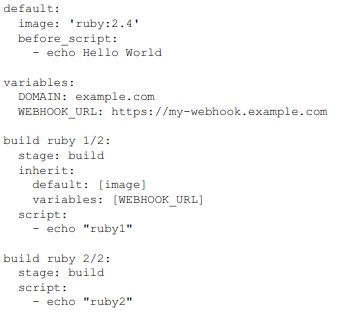
Considerando o trecho de código precedente, extraído do arquivo .gitlab-ci.yml, julgue o próximo item.
O job build ruby 1/2 herda automaticamente a image e o before_script definidos no bloco default, bem como a variável WEBHOOK_URL definida no bloco variables.
Considerando o trecho de código precedente, extraído do arquivo .gitlab-ci.yml, julgue o próximo item.
Os jobs build ruby 1/2 e build ruby 2/2 são, por padrão, executados em paralelo no GitLab CI, a menos que haja dependências explícitas configuradas entre eles
A respeito da arquitetura de sistemas web, julgue o item que se segue.
O padrão Cache-Aside (Lazy Loading) pode sofrer race conditions em cenários de alta concorrência, a menos que sejam adotadas técnicas de sincronização.
valor = 1 Enquanto valor < 20 faça Início valor = valor + 1 escreva (valor) Fim;
A codificação que gera o mesmo resultado da estrutura acima e que utiliza a estrutura PARA, corresponde à seguinte opção: