Questões Militares
Múltipla-escolha
Foram encontradas 135.751 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Q3266534
Estatística
No ajuste de qualquer modelo estatístico, uma das principais tarefas do analista é avaliar se as pressuposições
assumidas por determinada metodologia são satisfeitas,
bem como a qualidade desse ajuste aos dados. Para
isso, fazer uma análise de resíduos se torna imprescindível. Há três tipos de violações das suposições que são
prontamente detectados por meio do uso de gráficos
residuais; são elas: (i) presença de valores discrepantes;
(ii) variância do erro heterogênea; e (iii) especificação do
modelo inadequada.
Diante disso, o gráfico de valores preditos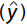 versus resíduos padronizados (ei), que indica uma especificação do
modelo inadequada para a situação em estudo, é:
versus resíduos padronizados (ei), que indica uma especificação do
modelo inadequada para a situação em estudo, é:
Diante disso, o gráfico de valores preditos
versus resíduos padronizados (ei), que indica uma especificação do
modelo inadequada para a situação em estudo, é:
Q3266533
Estatística
Em relação ao coeficiente de correlação de Pearson
populacional e amostral (ρ e r, respectivamente), é correto afirmar:
Q3266532
Estatística
São vários os procedimentos para a busca do “subconjunto ótimo” de variáveis, na ausência da ortogonalidade, para
obter uma equação de estimação adequada que relaciona
uma variável Y a todas ou a um subconjunto de variáveis
independentes. Considere o seguinte procedimento:
PASSO 1: Escolha a variável que fornece a maior soma de quadrados da regressão em regressão linear simples com Y ou, de maneira equivalente, que forneça o maior valor de R2. Chamaremos essa variável inicial de X1.
PASSO 2: Escolha a variável que, quando inserida no modelo, fornece o maior aumento em R2, na presença de X1, sobre o valor de R2 encontrado no passo 1, isto é, a variável Xj para a qual:
R(βj |β1) = R(β1, βj) – R(β1)
é maior. Vamos chamá-la de variável X2. O modelo de regressão com X1 e X2 é, então, ajustado e R2 é observado.
PASSO 3: Escolha a variável Xj que fornece o maior valor de:
R(βj |β1, β2) = R(β1, β2, βj) – R(β1, β2),
resultando novamente em um aumento em R2 sobre aquele dado no PASSO 2. Ao chamar essa variável de X3, agora temos um modelo de regressão que envolve X1, X2 e X3. Esse processo é continuado até que a variável inserida mais recentemente falhe ao produzir um aumento significativo na regressão explicada. Tal aumento pode ser determinado em cada passo, devendo-se usar o teste F (ou t) apropriado.
Por exemplo, no PASSO 2, o valor: pode ser determinado para testar a adequação de X2
no modelo. De maneira similar, no PASSO 3 a razão:
pode ser determinado para testar a adequação de X2
no modelo. De maneira similar, no PASSO 3 a razão:  testa a adequação de X3
no modelo.
testa a adequação de X3
no modelo.
Se f < f(1, n-3; α) no PASSO 2, para um nível de significância preestabelecido, X2 não é incluído e o processo é encerrado, resultando em uma equação linear simples que relaciona Y e X1.
Contudo, se f >f(1, n-3; α) deve-se seguir para o PASSO 3. Novamente, se f < f(1, n-4; α) no PASSO 3, X3 não é incluído e o processo é encerrado com a equação de regressão apropriada que contém as variáveis X1 e X2.
Notações utilizadas:
R2 é o coeficiente de determinação do modelo de regressão;
R(.) é a soma dos quadrados do modelo de regressão em questão;
βj é o coeficiente do modelo de regressão que acompanha a variável Xj;
A notação ‘|’ indica a probabilidade condicional;
 é o quadrado do erro médio para o modelo que
contém as variáveis X1 e X2;
é o quadrado do erro médio para o modelo que
contém as variáveis X1 e X2;
 é o quadrado do erro médio para o modelo que
contém as variáveis X1, X2 e X3.
é o quadrado do erro médio para o modelo que
contém as variáveis X1, X2 e X3.
Essa descrição se refere ao método de seleção de variáveis:
PASSO 1: Escolha a variável que fornece a maior soma de quadrados da regressão em regressão linear simples com Y ou, de maneira equivalente, que forneça o maior valor de R2. Chamaremos essa variável inicial de X1.
PASSO 2: Escolha a variável que, quando inserida no modelo, fornece o maior aumento em R2, na presença de X1, sobre o valor de R2 encontrado no passo 1, isto é, a variável Xj para a qual:
R(βj |β1) = R(β1, βj) – R(β1)
é maior. Vamos chamá-la de variável X2. O modelo de regressão com X1 e X2 é, então, ajustado e R2 é observado.
PASSO 3: Escolha a variável Xj que fornece o maior valor de:
R(βj |β1, β2) = R(β1, β2, βj) – R(β1, β2),
resultando novamente em um aumento em R2 sobre aquele dado no PASSO 2. Ao chamar essa variável de X3, agora temos um modelo de regressão que envolve X1, X2 e X3. Esse processo é continuado até que a variável inserida mais recentemente falhe ao produzir um aumento significativo na regressão explicada. Tal aumento pode ser determinado em cada passo, devendo-se usar o teste F (ou t) apropriado.
Por exemplo, no PASSO 2, o valor:
pode ser determinado para testar a adequação de X2
no modelo. De maneira similar, no PASSO 3 a razão: testa a adequação de X3
no modelo. Se f < f(1, n-3; α) no PASSO 2, para um nível de significância preestabelecido, X2 não é incluído e o processo é encerrado, resultando em uma equação linear simples que relaciona Y e X1.
Contudo, se f >f(1, n-3; α) deve-se seguir para o PASSO 3. Novamente, se f < f(1, n-4; α) no PASSO 3, X3 não é incluído e o processo é encerrado com a equação de regressão apropriada que contém as variáveis X1 e X2.
Notações utilizadas:
R2 é o coeficiente de determinação do modelo de regressão;
R(.) é a soma dos quadrados do modelo de regressão em questão;
βj é o coeficiente do modelo de regressão que acompanha a variável Xj;
A notação ‘|’ indica a probabilidade condicional;
é o quadrado do erro médio para o modelo que
contém as variáveis X1 e X2; é o quadrado do erro médio para o modelo que
contém as variáveis X1, X2 e X3. Essa descrição se refere ao método de seleção de variáveis:
Q3266531
Estatística
Considere a população de crianças, do sexo masculino,
de faixa etária de 6 a 7 anos de uma determinada região.
É de desejo realizar o seguinte teste de hipóteses para
a proporção (p) de crianças com o índice de massa corpórea (IMC) maior que 30 dessa população (que é normalmente distribuída para essa variável): p = 0,6 contra
p > 0,6. Fixando um nível de significância de 5%; considerando pc
o um ponto crítico para a tomada de decisão e
o estimador  da verdadeira proporção de crianças com
o índice de massa corpórea (IMC) maior que 30, p, é correto afirmar que:
da verdadeira proporção de crianças com
o índice de massa corpórea (IMC) maior que 30, p, é correto afirmar que:
da verdadeira proporção de crianças com
o índice de massa corpórea (IMC) maior que 30, p, é correto afirmar que:
Q3266530
Estatística
A abordagem do teste de hipóteses para a inferência estatística é muito próxima à abordagem do intervalo
de confiança. Essa equivalência se estende às diferenças entre duas médias, variâncias, razão de variâncias
e assim por diante. Para o caso de uma única média
populacional µ com variância σ2
conhecida, considerando um nível de significância α e uma amostra aleatória de
tamanho n dessa população, é correto afirmar:
Q3266529
Estatística
Em uma fábrica de ar-condicionado, nove máquinas do mesmo modelo foram selecionadas aleatoriamente a fim
de determinar o efeito da limpeza do filtro de ar no gasto de energia elétrica. Todas as máquinas novas foram
instaladas em um mesmo lado de um prédio, e durante
dois meses (numa mesma estação do ano) foram ligadas
durante o mesmo período por dia, numa mesma temperatura. O gasto médio diário em kW da última semana apresentou um valor de 156. Terminado esse mês, foi realizada
a limpeza do filtro de ar de todas as máquinas e, durante
mais uma semana, elas foram ligadas nas mesmas condições. No final do último dia, calculou-se o consumo médio,
resultando no valor de 140 kW. O desvio-padrão da diferença entre o consumo antes da limpeza menos o consumo depois da limpeza foi de 15 kW. Ao nível de 5%, de
significância, foram testadas as hipóteses: de o consumo
médio antes ser igual ao consumo médio depois da limpeza das máquinas contra o consumo médio antes ser
maior que o consumo médio depois da limpeza. O valor
calculado da estatística de teste e sua conclusão para
esse teste de hipóteses são, respectivamente:
Q3266528
Estatística
Um fabricante de pilhas AAA afirma que a vida útil delas
tem distribuição aproximadamente normal com média
de 0,17 ano e desvio-padrão de 0,3 ano. Uma amostra
aleatória de 37 dessas pilhas apresentou um desvio-
-padrão de 0,4 ano. Considerando a hipótese alternativa
de o desvio-padrão ser maior que 0,3 ano, o resultado
do valor da estatística calculada e a conclusão desse
teste de hipótese ao nível de significância de 0,05 serão
respectivamente:
Q3266527
Estatística
Considere a realização dos seguintes experimentos:
• Experimento I: anota-se a face superior do lançamento de três moedas.
• Experimento II: anota-se a face superior do lançamento de dois dados.
• Experimento III: anota-se a face superior do lançamento de duas moedas e três dados.
Considere que todos os dados utilizados nesses experimentos têm seis faces. O número de elementos do espaço amostral de cada experimento é respectivamente:
• Experimento I: anota-se a face superior do lançamento de três moedas.
• Experimento II: anota-se a face superior do lançamento de dois dados.
• Experimento III: anota-se a face superior do lançamento de duas moedas e três dados.
Considere que todos os dados utilizados nesses experimentos têm seis faces. O número de elementos do espaço amostral de cada experimento é respectivamente:
Q3266526
Estatística
Considere que a função de densidade da variável aleatória contínua uniforme, X, no intervalo [13, 25] modela
razoavelmente um fenômeno de interesse. Dessa forma,
o valor esperado e a variância dessa variável aleatória
serão respectivamente:
Q3266525
Estatística
Arrecadações de objetos novos e usados com a população são ações que o exército costuma realizar para ajudar os necessitados depois de alguma tragédia. Contudo,
objetos usados nem sempre chegam em bom estado e,
por isso, necessitam de algum conserto antes de serem
distribuídos. Um levantamento feito em uma dessas
ações, que arrecadou 900 itens, gerou a seguinte relação
de materiais e a situação desses itens:
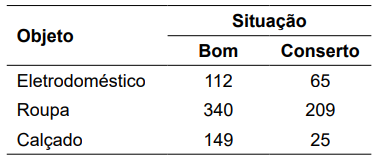
A probabilidade de pegar, ao acaso, uma roupa ou um item que precise de conserto é igual a:
A probabilidade de pegar, ao acaso, uma roupa ou um item que precise de conserto é igual a:
Q3266524
Estatística
Considere X uma variável aleatória discreta, em que X ~ Binomial(n, p).
Sobre essa distribuição, é correto afirmar que
Sobre essa distribuição, é correto afirmar que
Q3266523
Estatística
Considere que um professor de estatística deseja avaliar se a nota obtida pelos alunos pode ser descrita em função do
tempo de estudo deles. Para isso, decidiu realizar o ajuste de um modelo de regressão linear e organizou os dados das
notas dos alunos e do tempo de estudo em dois objetos no ambiente R, nomeados como “nota” e “tempo”, ambos na
mesma ordem de entrada. A sequência de comandos que realiza o ajuste de um modelo de regressão linear e apresenta
o intervalo de confiança (95%) para os coeficientes de regressão é:
Q3266522
Estatística
Em um levantamento para analisar as escolas de um determinado município, foram obtidos dados do número de alunos
matriculados por turma em cada escola, sendo criado um arquivo .RData, nomeado como dado, com as colunas Escola,
Turma e Matriculados. As três primeiras linhas do objeto dado são apresentadas a seguir.

O comando que pode ser empregado para obter a variância por escola para o número de alunos matriculados por turma é:
O comando que pode ser empregado para obter a variância por escola para o número de alunos matriculados por turma é:
Q3266521
Estatística
Em uma pesquisa, realizada em uma determinada cidade, foram coletadas informações das residências por bairro, sendo
obtido um conjunto de dados, nomeado como dado, no seguinte formato:
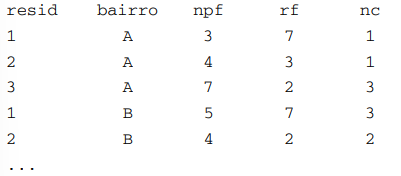
Em que resid representa o número da residência por bairro, bairro representa o bairro da residência, npf representa o número de pessoas que residem na residência, rf representa a renda familiar (em quantidade de salários mínimos) e nc representa o número de pessoas com menos de 10 anos que residem na residência.
Considere que se deseja obter os valores médios das variáveis por bairro. Utilizando o pacote dplyr, os comandos que retornam um novo conjunto com os valores médios por bairro para as variáveis número de pessoas que residem na residência, renda familiar e número de pessoas com menos de 10 anos que residem na residência é apresentado em:
Em que resid representa o número da residência por bairro, bairro representa o bairro da residência, npf representa o número de pessoas que residem na residência, rf representa a renda familiar (em quantidade de salários mínimos) e nc representa o número de pessoas com menos de 10 anos que residem na residência.
Considere que se deseja obter os valores médios das variáveis por bairro. Utilizando o pacote dplyr, os comandos que retornam um novo conjunto com os valores médios por bairro para as variáveis número de pessoas que residem na residência, renda familiar e número de pessoas com menos de 10 anos que residem na residência é apresentado em:
Q3266520
Estatística
Considere a teoria Bayesiana e as famílias conjugadas
de distribuição. Seja F uma família de distribuições para
a verossimilhança p(x|θ) e P uma família de distribuição
para a priori p(θ). Dizemos que F e P são famílias conjugadas de distribuições se:
Q3266519
Estatística
Considere a teoria de decisão Bayesiana. Sobre uma
priori não-informativa, é possível afirmar:
Q3266518
Estatística
Considere uma população de 10 elementos, da qual se deseja obter uma amostra com 4 elementos. Considere
uma amostragem aleatória simples, sem reposição.
A probabilidade de se obter uma amostra particular é:
A probabilidade de se obter uma amostra particular é:
Q3266517
Estatística
Uma decisão importante na utilização da amostragem
estratificada é a forma pela qual o tamanho total da
amostra será alocado ou distribuído nos estratos. Uma
das formas de realizar essa alocação é utilizando a alocação ótima.
Sobre a alocação ótima, pode-se afirmar que
Sobre a alocação ótima, pode-se afirmar que
Q3266516
Estatística
Considere um estudo para investigar o número médio de crianças (menores de 10 anos) por residência em
uma cidade com N = 385 residências, em que se sabe,
de estudos anteriores, que a variância do número de
crianças por residência é 1. Considere o caso de uma
amostragem aleatória simples. Dado: Φ(1,645) = 0,95 e Φ(1,96) = 0,975, sendo φ a função de distribuição acumulada normal padrão.
Considerando o nível de confiança de 95% e a margem de erro máxima de 0,2, o tamanho da amostra necessário é igual a:
Considerando o nível de confiança de 95% e a margem de erro máxima de 0,2, o tamanho da amostra necessário é igual a:
Q3266515
Estatística
Um empreendedor que recentemente investiu em uma
franquia de alimentação gostaria de saber qual a proporção de clientes que está satisfeita com o atendimento, para decidir sobre a manutenção do negócio. Considere o caso de uma amostragem aleatória simples e
o nível de confiança de 95%. Dado: Φ(1,645) = 0,95 e Φ(1,96) = 0,975, sendo Φ a função de distribuição acumulada normal padrão.
O tamanho da amostra que o empreendedor deve utilizar na pesquisa para um erro máximo de 2% é igual a:
O tamanho da amostra que o empreendedor deve utilizar na pesquisa para um erro máximo de 2% é igual a: