Questões de Concurso
Certo ou errado
Foram encontradas 418.306 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Em relação ao princípio de funcionamento de sistemas de aterramento e aos procedimentos de implantação desses sistemas, julgue o item a seguir.
O equipamento de medição da resistência de aterramento, utilizado no método de queda de potencial, é o megômetro.
Com relação à automação industrial, julgue o item subsecutivo.
Nos sistemas de controle de malha aberta, a saída do sistema interfere na ação de controle.
Com relação à automação industrial, julgue o item subsecutivo.
O protocolo CANBus tem alta taxa de transferência em tempo real.
Julgue o item subsequente, que versa a respeito de eletrônica de potência.
Os retificadores controlados de silício (SCR), quando instalados em polarização direta, conduzem corrente elétrica apenas se receberem um comando por corrente no terminal de gatilho.
Julgue o item subsequente, que versa a respeito de eletrônica de potência.
O circuito a seguir é um retificador monofásico controlado de meia onda.
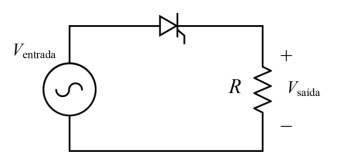
No que se refere à iluminação industrial, julgue o próximo item.
Os conceitos de iluminância e de intensidade luminosa são sinônimos.
No que se refere à iluminação industrial, julgue o próximo item.
Lâmpadas a vapor metálico, se comparadas com as de vapor de mercúrio, têm maior vida útil e maior eficiência luminosa.
Acerca de nobreaks, de instalações elétricas de baixa tensão e da proteção de sistemas elétricos industriais, julgue o item a seguir.
Um motor de indução deve ser protegido com um disjuntor tipo B para acomodar corretamente a curva de partida do motor.
Acerca de nobreaks, de instalações elétricas de baixa tensão e da proteção de sistemas elétricos industriais, julgue o item a seguir.
Em um nobreak do tipo online, a carga é alimentada pela rede elétrica diretamente.
Acerca de nobreaks, de instalações elétricas de baixa tensão e da proteção de sistemas elétricos industriais, julgue o item a seguir.
No esquema de aterramento TN-C-S, parte da instalação possui a função de neutro e de proteção combinadas em um único condutor.
Acerca de nobreaks, de instalações elétricas de baixa tensão e da proteção de sistemas elétricos industriais, julgue o item a seguir.
Com relação às baterias utilizadas em nobreaks, as baterias estacionárias têm normalmente uma vida útil maior que as de chumbo-ácido seladas e são projetadas para ciclos profundos de carga e descarga.
Considerando conceitos e características de dispositivos e famílias de circuitos integrados de eletrônica digital, julgue o próximo item.
Em circuitos integrados da família TTL, o nível lógico alto mínimo (VIH) é maior que a tensão de alimentação (Vcc).
Considerando conceitos e características de dispositivos e famílias de circuitos integrados de eletrônica digital, julgue o próximo item.
Os circuitos integrados da família TTL apresentam menor consumo de potência estática que os circuitos integrados equivalentes da família CMOS.
Considerando conceitos e características de dispositivos e famílias de circuitos integrados de eletrônica digital, julgue o próximo item.
Portas lógicas não-e (NAND) e não-ou (NOR) são consideradas portas lógicas universais.
Considerando conceitos e características de dispositivos e famílias de circuitos integrados de eletrônica digital, julgue o próximo item.
Contadores digitais são exemplos de circuitos digitais sequenciais.
Julgue o item a seguir, relativo a conceitos e características de dispositivos em eletrônica analógica.
O capacitor de filtro, utilizado em uma fonte retificadora, tem a função principal de reduzir a ondulação da tensão de saída.
Julgue o item a seguir, relativo a conceitos e características de dispositivos em eletrônica analógica.
O aumento da temperatura ambiente aumenta a tensão de limiar de condução de um diodo de silício.
Julgue o item a seguir, relativo a conceitos e características de dispositivos em eletrônica analógica.
A resistência de saída de um transistor bipolar de junção real é finita devido ao efeito Early.
Julgue o item a seguir, relativo a conceitos e características de dispositivos em eletrônica analógica.
O amplificador operacional em malha aberta é normalmente utilizado em aplicações lineares.
No que se refere a acionamentos e controles elétricos, julgue o item subsequente.
Se o conjugado resistente da carga for sempre maior que o conjugado do motor, o sistema entrará em regime permanente.