Foram encontradas 13.945 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
I. A variável X, que representa o número mensal de suicídios no país A, tem distribuição de Poisson com média mensal 2. II. A variável Y, que representa o número mensal de suicídios no país B, tem distribuição de Poisson com média mensal 4. III. As variáveis X e Y são independentes.
Nessas condições, a probabilidade de em determinado mês ocorrerem menos de 2 suicídios no país A e exatamente 2 no país B é igual a
Dados: e−1 = 0,37 e−2 = 0,135 e−4 = 0,018
l. Os testes não paramétricos somente são utilizados quando as variáveis de estudo não possuem distribuição normal. II. Para se utilizar os testes não paramétricos as variáveis de estudo devem ser do tipo quantitativo. III. O teste não paramétrico de Wilcoxon − Mann-Whitney é baseado nos postos dos valores das variáveis de estudo envolvidas. IV. O teste de KrusKal-Wallis é uma generalização do Teste de Friedman para populações normais.
Está correto o que se afirma APENAS em

Seja X a variável aleatória que representa o número de tentativas até a obtenção do primeiro sucesso. Baseado nessa amostra, o valor observado da estatística qui-quadrado apropriado para testar se X se comporta com uma distribuição geométrica de média igual a 5 é dado por
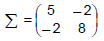
O auto vetor normalizado correspondente à primeira componente principal da matriz Σ é dado por:
I. Se X e Y têm distribuição qui-quadrado com graus de liberdade dados, respectivamente por 2 e 3, então a variável W = (3X/2Y) tem distribuição F (Snedecor) com 2 e 3 graus de liberdade, respectivamente. II. Sendo X uma variável com distribuição normal padrão e Y uma variável com distribuição qui-quadrado com 1 grau de liberdade, então a variável W = (X/√Y ) tem distribuição t de Student com 1 grau de liberdade. III. A distribuição exponencial é um caso particular da distribuição gama. IV. Se X tem distribuição gama com parâmetros a e b, com a ≥ 1 e b > 0, então a variância de X é igual ao produto de a por b.
Está correto o que se afirma em
Dados: e−0,5 = 0,61 e−0,75 = 0,47 e−0,8 = 0,45 e−1 = 0,37 e−1,2 = 0,30
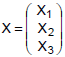 tem distribuição normal multivariada com vetor de médias, dado por
tem distribuição normal multivariada com vetor de médias, dado por 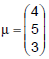 matriz de covariâncias dada por
matriz de covariâncias dada por 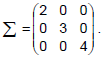 Os dados do vetor μ estão em dias e os da matriz Σ em (dias)². Quatro funcionários são selecionados ao acaso e com reposição
dentre todos os funcionários da empresa. Nessas condições, a probabilidade do tempo médio, para a realização da tarefa,
desses 4 funcionários ser de pelo menos 15 dias é igual a
Os dados do vetor μ estão em dias e os da matriz Σ em (dias)². Quatro funcionários são selecionados ao acaso e com reposição
dentre todos os funcionários da empresa. Nessas condições, a probabilidade do tempo médio, para a realização da tarefa,
desses 4 funcionários ser de pelo menos 15 dias é igual a A porcentagem do orçamento gasto com educação nos municípios de certo estado é uma variável aleatória X com distribuição normal com média μ(%) e variância 4(%)2.
Um gasto em educação superior a 10% tem probabilidade de 4%. Nessas condições, o valor de μ é igual a
A porcentagem do orçamento gasto com educação nos municípios de certo estado é uma variável aleatória X com distribuição normal com média μ(%) e variância 4(%)2.
Uma amostra aleatória, com reposição, de tamanho n, X₁, X₂,..., Xn, é selecionada da distribuição de X. Sendo
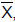 a média ,
amostral dessa amostra, o valor de n para que
a média ,
amostral dessa amostra, o valor de n para que 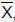 não se distancie de sua média por mais do que 0,41% com probabilidade de
96% é igual a
não se distancie de sua média por mais do que 0,41% com probabilidade de
96% é igual a Um determinado órgão público recebe mensalmente processos que devem ser analisados por 2 analistas: A e B. Sabe-se que esses dois analistas recebem a mesma proporção de processos para a análise. Sabe-se que 20% de todos os processos encaminhados para A são analisados no mês de recebimento e que 10% são indeferidos. Sabe-se também que 40% dos processos encaminhados para B são analisados no mês de recebimento e que 20% são indeferidos.
Sabe-se que um processo analisado no mês de recebimento foi indeferido. A probabilidade de ele ter sido encaminhado para A é igual a
Um determinado órgão público recebe mensalmente processos que devem ser analisados por 2 analistas: A e B. Sabe-se que esses dois analistas recebem a mesma proporção de processos para a análise. Sabe-se que 20% de todos os processos encaminhados para A são analisados no mês de recebimento e que 10% são indeferidos. Sabe-se também que 40% dos processos encaminhados para B são analisados no mês de recebimento e que 20% são indeferidos.
Cinco processos são selecionados ao acaso e com reposição em um determinado mês. A probabilidade de exatamente 2 não serem analisados no mês de recebimento é igual a
Atenção: Considere o enunciado abaixo para responder à questão.
Um determinado órgão público recebe mensalmente processos que devem ser analisados por 2 analistas: A e B. Sabe-se que esses dois analistas recebem a mesma proporção de processos para a análise. Sabe-se que 20% de todos os processos encaminhados para A são analisados no mês de recebimento e que 10% são indeferidos. Sabe-se também que 40% dos processos encaminhados para B são analisados no mês de recebimento e que 20% são indeferidos.
Um processo recebido em determinado mês é selecionado ao acaso. A probabilidade de ele ser deferido naquele mesmo mês é
igual a
Opção A: entrada, prato principal e sobremesa. Opção B: entrada e prato principal.
Sabe-se que 30% dos clientes do sexo feminino preferem a opção A, 40% dos clientes do sexo masculino preferem a opção B e que 60% dos clientes são do sexo feminino. Sejam H e M os eventos que representam que o cliente é do sexo masculino e feminino, respectivamente. Sejam A e B os eventos que representam o cliente optar por refeição do tipo A e B, respectivamente. Nessas condições, P(AUH) é igual a
Sobre intervalo de confiança, analise as afirmativas abaixo e assinale a alternativa correta:
I. Um intervalo de confiança de 95% significa que, para um dado intervalo calculado a partir de dados, há uma probabilidade de 95% do parâmetro da população de encontrar-se dentro do intervalo e que existe uma probabilidade de 95% do parâmetro da população abranger o intervalo.
II. Um intervalo de confiança de 95% não significa que 95% dos dados de amostra encontram-se dentro do intervalo.
III. Um intervalo de confiança particular de 95% calculada a partir de uma experiência não significa que existe uma probabilidade de 95% de uma média de amostras de uma repetição da experiência caindo dentro deste intervalo.
Um pesquisador estimou o seguinte modelo econométrico relacionando as variáveis quantidade consumida (q), rendimento (y) e preço (p) para diferentes indivíduos i.
ln(yi) = α0 + α1 ln(yi) + α2 ln(pi) + ϵi .
A estimação feita por mínimos quadrados utilizou 31 observações e obteve os seguintes resultados.
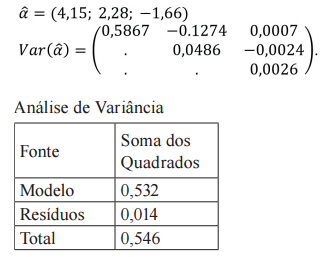
O vetor 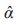 representa as estimativas para α = (α0, α1, α2) e Var ( ̂) é estimativa da matriz de α
variância-covariância de . Os resíduos ϵ são não correlacionados e têm distribuição normal
com média zero e variância σ2
.
representa as estimativas para α = (α0, α1, α2) e Var ( ̂) é estimativa da matriz de α
variância-covariância de . Os resíduos ϵ são não correlacionados e têm distribuição normal
com média zero e variância σ2
.
Um pesquisador estimou o seguinte modelo econométrico relacionando as variáveis quantidade consumida (q), rendimento (y) e preço (p) para diferentes indivíduos i.
ln(yi) = α0 + α1 ln(yi) + α2 ln(pi) + ϵi .
A estimação feita por mínimos quadrados utilizou 31 observações e obteve os seguintes resultados.
O vetor representa as estimativas para α = (α0, α1, α2) e Var ( ̂) é estimativa da matriz de α
variância-covariância de . Os resíduos ϵ são não correlacionados e têm distribuição normal
com média zero e variância σ2
.
Um pesquisador estimou o seguinte modelo econométrico relacionando as variáveis quantidade consumida (q), rendimento (y) e preço (p) para diferentes indivíduos i.
ln(yi) = α0 + α1 ln(yi) + α2 ln(pi) + ϵi .
A estimação feita por mínimos quadrados utilizou 31 observações e obteve os seguintes resultados.
O vetor representa as estimativas para α = (α0, α1, α2) e Var ( ̂) é estimativa da matriz de α
variância-covariância de . Os resíduos ϵ são não correlacionados e têm distribuição normal
com média zero e variância σ2
.