Questões de Concurso
Para estatística
Foram encontradas 13.777 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Um estudo acerca do tempo (x, em anos) de guarda de
autos findos em determinada seção judiciária considerou uma
amostragem aleatória estratificada. A população consiste de uma
listagem de autos findos, que foi segmentada em quatro estratos,
segundo a classe de cada processo (as classes foram estabelecidas
por resolução de autoridade judiciária). A tabela a seguir mostra os
tamanhos populacionais (N) e amostrais (n), a média amostral
 e a variância amostral dos tempos (s2
) correspondentes a cada
estrato.
e a variância amostral dos tempos (s2
) correspondentes a cada
estrato.

Considerando que o objetivo do estudo seja estimar o tempo médio populacional (em anos) de guarda dos autos findos, julgue o item a seguir.
A estimativa do tempo médio populacional da guarda dos autos
findos é maior ou igual a 12 anos.
Um estudo acerca do tempo (x, em anos) de guarda de
autos findos em determinada seção judiciária considerou uma
amostragem aleatória estratificada. A população consiste de uma
listagem de autos findos, que foi segmentada em quatro estratos,
segundo a classe de cada processo (as classes foram estabelecidas
por resolução de autoridade judiciária). A tabela a seguir mostra os
tamanhos populacionais (N) e amostrais (n), a média amostral
e a variância amostral dos tempos (s2
) correspondentes a cada
estrato.
Considerando que o objetivo do estudo seja estimar o tempo médio populacional (em anos) de guarda dos autos findos, julgue o item a seguir.
A fração amostral utilizada no estudo em tela foi igual ou
superior a 10%.
Um estudo acerca do tempo (x, em anos) de guarda de
autos findos em determinada seção judiciária considerou uma
amostragem aleatória estratificada. A população consiste de uma
listagem de autos findos, que foi segmentada em quatro estratos,
segundo a classe de cada processo (as classes foram estabelecidas
por resolução de autoridade judiciária). A tabela a seguir mostra os
tamanhos populacionais (N) e amostrais (n), a média amostral
e a variância amostral dos tempos (s2
) correspondentes a cada
estrato.
Considerando que o objetivo do estudo seja estimar o tempo médio populacional (em anos) de guarda dos autos findos, julgue o item a seguir.
No estudo em questão foi aplicada uma amostragem aleatória
estratificada com alocação proporcional ao tamanho dos
estratos.
Uma amostra aleatória simples Y1, Y2, ..., Yn, retirada de uma população Bernoulli, é tal que

para y = 0 ou 1, 0 < θ < 1 e k = 1, 2, ..., n. O objetivo é efetuar
inferências acerca do parâmetro θ mediante aplicação de métodos
computacionais.
Considerando que para r ≥ 0, 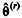 represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
O método HPD (high probability density) é um algoritmo que
proporciona um intervalo de confiança clássico (frequentista)
para o parâmetro θ.
Uma amostra aleatória simples Y1, Y2, ..., Yn, retirada de uma população Bernoulli, é tal que
para y = 0 ou 1, 0 < θ < 1 e k = 1, 2, ..., n. O objetivo é efetuar
inferências acerca do parâmetro θ mediante aplicação de métodos
computacionais.
Considerando que para r ≥ 0, 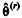 represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
O amostrador de Gibbs, um algoritmo sequencial de Monte
Carlo, permite simular a distribuição a priori do parâmetro θ,
desde que a forma funcional da sua função de densidade, ƒ(θ),
seja conhecida.
Uma amostra aleatória simples Y1, Y2, ..., Yn, retirada de uma população Bernoulli, é tal que
para y = 0 ou 1, 0 < θ < 1 e k = 1, 2, ..., n. O objetivo é efetuar
inferências acerca do parâmetro θ mediante aplicação de métodos
computacionais.
Considerando que para r ≥ 0, 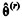 represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
represente a estimativa de θ obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
No algoritmo de Metropolis-Hastings tem-se a forma iterativa 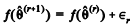 , na qual ƒ representa a função de
densidade a priori de θ, e ∈, > 0 representa um incremento
aleatório. Nesse algoritmo, a probabilidade de aceitação do
valor proposto
, na qual ƒ representa a função de
densidade a priori de θ, e ∈, > 0 representa um incremento
aleatório. Nesse algoritmo, a probabilidade de aceitação do
valor proposto 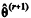 como uma estimativa viável para o
parâmetro de interesse é constante.
como uma estimativa viável para o
parâmetro de interesse é constante.
Uma amostra aleatória simples Y1, Y2, ..., Yn, retirada de uma população Bernoulli, é tal que
para y = 0 ou 1, 0 < θ < 1 e k = 1, 2, ..., n. O objetivo é efetuar
inferências acerca do parâmetro θ mediante aplicação de métodos
computacionais.
Considerando que para r ≥ 0, 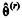 represente a estimativa de θ
obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
represente a estimativa de θ
obtida na r-ésima iteração de um algoritmo de estimação, julgue o seguinte item.
O método de Monte Carlo via cadeia de Markov (MCMC)
pertence à classe de algoritmos de estimação não sequencial,
em que 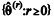 forma um conjunto de valores mutuamente
independentes. Excluindo-se o valor inicial
forma um conjunto de valores mutuamente
independentes. Excluindo-se o valor inicial 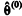 , uma
estimativa do parâmetro θ é dada por
, uma
estimativa do parâmetro θ é dada por 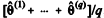 , na
qual q representa um valor suficientemente grande.
, na
qual q representa um valor suficientemente grande.
Considerando que Y, U e Q sejam mutuamente independentes, julgue o próximo item.
Caso W seja uma realização retirada de uma distribuição
normal com média nula e variância k, será correto afirmar que
o produto 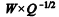 é realização de uma distribuição t de
Student com k graus de liberdade.
é realização de uma distribuição t de
Student com k graus de liberdade.
Considerando que Y, U e Q sejam mutuamente independentes, julgue o próximo item.
A transformação 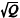 proporciona uma realização da
distribuição normal padrão.
proporciona uma realização da
distribuição normal padrão.
Considerando que Y, U e Q sejam mutuamente independentes, julgue o próximo item.
Realizações G de uma distribuição gama com média 2m podem
ser obtidas com base na transformação G = Y - m × ln(U).
Considerando que Y, U e Q sejam mutuamente independentes, julgue o próximo item.
O produto 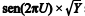 segue uma distribuição normal com
média nula.
segue uma distribuição normal com
média nula.
Considerando que Y, U e Q sejam mutuamente independentes, julgue os próximos item.
Suponha que Y1, Y2, ..., Yn sejam n realizações independentes
retiradas de uma distribuição exponencial com média m. Nessa
situação, a média 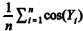 representa uma estimativa da
integral
representa uma estimativa da
integral 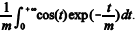
Diversos processos buscam reparação financeira por danos morais. A tabela seguinte mostra os valores, em reais, buscados em 10 processos — numerados de 1 a 10 — de reparação por danos morais, selecionados aleatoriamente em um tribunal.

A partir dessas informações e sabendo que os dados seguem uma distribuição normal, julgue o item subsequente.
Na situação em questão, em que os dados seguem uma distribuição normal, o teste não paramétrico de Wilcoxon é menos poderoso que o teste t de Student.
Diversos processos buscam reparação financeira por danos morais. A tabela seguinte mostra os valores, em reais, buscados em 10 processos — numerados de 1 a 10 — de reparação por danos morais, selecionados aleatoriamente em um tribunal.
A partir dessas informações e sabendo que os dados seguem uma distribuição normal, julgue o item subsequente.
Nessa situação, se for possível usar o teste t de Student, então esse teste teria 9 graus de liberdade.
Diversos processos buscam reparação financeira por danos morais. A tabela seguinte mostra os valores, em reais, buscados em 10 processos — numerados de 1 a 10 — de reparação por danos morais, selecionados aleatoriamente em um tribunal.
A partir dessas informações e sabendo que os dados seguem uma distribuição normal, julgue o item subsequente.
Caso seja de interesse testar, por exemplo, se a média dos valores é diferente de 3.500, para calcular o p-valor do teste no referido estudo é suficiente multiplicar a
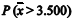 por 2,
em que
por 2,
em que 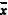 é a média amostral.
é a média amostral. Diversos processos buscam reparação financeira por danos morais. A tabela seguinte mostra os valores, em reais, buscados em 10 processos — numerados de 1 a 10 — de reparação por danos morais, selecionados aleatoriamente em um tribunal.
A partir dessas informações e sabendo que os dados seguem uma distribuição normal, julgue o item subsequente.
Uma forma de verificar a normalidade dos dados seria pelo
teste de Kolmogorov-Smirnov, calculando-se o valor crítico,
para n pequeno (n < 10), pela aproximação 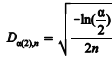 , em que α é o nível de significância do
teste.
, em que α é o nível de significância do
teste.
Diversos processos buscam reparação financeira por danos morais. A tabela seguinte mostra os valores, em reais, buscados em 10 processos — numerados de 1 a 10 — de reparação por danos morais, selecionados aleatoriamente em um tribunal.
A partir dessas informações e sabendo que os dados seguem uma distribuição normal, julgue o item subsequente.
Se µ = estimativa pontual para a média dos valores buscados
como reparação por danos morais no referido tribunal, então
3.000 < µ < 3.300.
A tabela a seguir foi usada para verificar se existe alguma relação entre a variável p = quantidade de páginas de um processo e a variável t = tempo necessário para a conclusão desse processo.

Considerando que Xj2 denota a distribuição qui-quadrado com j graus de liberdade e que P( X12> 3,84) = 0,05, P(X22> 5,99) = 0,05, P( X32 > 7,81) = 0,05, P(X12 > 2,71) = 0,10, P( X22 > 4,60) = 0,10, P(X32 > 6,25) = 0,10, julgue o item que se segue, tendo como referência as informações na tabela.
Se, a partir do teste de independência entre as referidas
variáveis, o valor calculado da estatística qui-quadrado for
superior a 60, então será correto concluir com 95% de
confiança que existe associação entre essas variáveis.
A tabela a seguir foi usada para verificar se existe alguma relação entre a variável p = quantidade de páginas de um processo e a variável t = tempo necessário para a conclusão desse processo.
Considerando que Xj2 denota a distribuição qui-quadrado com j graus de liberdade e que P( X12> 3,84) = 0,05, P(X22> 5,99) = 0,05, P( X32 > 7,81) = 0,05, P(X12 > 2,71) = 0,10, P( X22 > 4,60) = 0,10, P(X32 > 6,25) = 0,10, julgue o item que se segue, tendo como referência as informações na tabela.
Se for utilizado o teste qui-quadrado para verificar se existe
associação entre as variáveis referidas, então o grau de
liberdade do referido teste será igual a 2.
A tabela a seguir foi usada para verificar se existe alguma relação entre a variável p = quantidade de páginas de um processo e a variável t = tempo necessário para a conclusão desse processo.
Considerando que Xj2 denota a distribuição qui-quadrado com j graus de liberdade e que P( X12> 3,84) = 0,05, P(X22> 5,99) = 0,05, P( X32 > 7,81) = 0,05, P(X12 > 2,71) = 0,10, P( X22 > 4,60) = 0,10, P(X32 > 6,25) = 0,10, julgue o item que se segue, tendo como referência as informações na tabela.
A amostra utilizada para o estudo contém mais de
290 processos.