Foram encontradas 13.775 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
A mediana sempre será um valor presente no conjunto de dados original, tornando-a mais confiável do que a média.
Utilizar tanto a média quanto a mediana em análises pode fornecer uma compreensão mais completa da distribuição dos dados ao comparar essas duas medidas.
A média é a medida mais adequada para entender o comportamento geral de gastos dos consumidores, mesmo na presença de valores extremamente altos ou baixos.
A moda é particularmente útil quando se deseja identificar produtos ou serviços mais comuns escolhidos pelos consumidores.
A mediana é preferível à média em distribuições simétricas de dados, pois fornece uma melhor representação do centro do conjunto de dados.
Para tanto, foi selecionado uma amostra de 25 equipamentos, em que se observou que o tempo médio e o desvio padrão dessa amostra foi de, aproximadamente, 700 dias e 20 dias respectivamente.
Levando em consideração a potência do teste, assinale a opção que apresenta a hipótese alternativa mais adequada para a realização do teste.
Supondo que a probabilidade do canal transmitir um 0 é 0,4, assinale a opção que indica a probabilidade de um símbolo escolhido aleatoriamente ser recebido corretamente.
{21, 42, 29, 15, 27, 36, 25, 45}
Considerando o exposto, analise os itens a seguir.
I. A amplitude dos dados é igual àI, II média.
II. A mediana é 28.
III. A moda é 45.
Está correto o que se afirma em
Para verificar se um outlier é influente ou não, o método mais apropriado seria
Assinale a opção que apresenta a técnica mais apropriada para o estudo do pesquisador.
Considere o conjunto de dados a seguir, que apresenta, de forma simplificada, as características de uma amostra de 1600 animais de estimação.
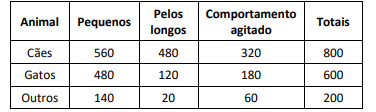
Sejam dois novos animais de estimação identificados por A e B, tais que:
• A é pequeno, com pelos curtos e de comportamento agitado;
• B é grande, com pelos longos e de comportamento agitado.
Aplicando o algoritmo Naïve Bayes, assinale a opção que apresenta as classes mais prováveis dos animais A e B, respectivamente.
Assinale a opção que indica o tipo de gráfico mais adequado para representar essa distribuição de frequência.
Considere o conjunto de dados e a informação a seguir:
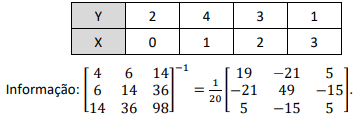
Deseja-se encontrar um modelo de regressão polinomial de 2º grau Y = a0 + a1 X + a2 X2 que melhor se encaixe nesse conjunto de dados.
Estimando-se pelo método dos mínimos quadrados, os valores de a0, a1 e a2 serão dados, respectivamente, por
Entre exemplos de métricas de avaliação utilizadas para modelos de classificação binária, é correto citar
• a taxa de precisão (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos positivos);
• a taxa de sensibilidade (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos negativos, também conhecida por recall); e
• o escore F1 (F1-score, também chamado de F-measure), que relaciona as taxas de precisão e de sensibilidade.
Suponha a existência de um modelo de classificação binária cuja taxa de precisão é de 90,00% e cuja taxa de sensibilidade é de 75,00%. Utilize aproximação de duas casas decimais.
O escore F1 referente a esse modelo é
Durante um experimento de química analítica, um estudante realizou cinco determinações consecutivas da concentração de íons em uma solução padrão, obtendo os seguintes resultados em mol/L: 2,32; 2,41; 2,39; 2,45; 2,59. A equação da reta para esses dados é mostrada a seguir:
y = 0,058x + 2,258
Sabendo que a Soma Total dos Quadrados (SST) é igual a 0,04 e a Soma dos Quadrados dos Erros (SSE) é igual a 0,006, é correto afirmar que o coeficiente de determinação — R2 — é igual a
Foi realizado um levantamento em uma indústria de alto grau de risco, sendo identificado 10 óbitos nos últimos 5 anos, conforme a listagem a seguir:
Ano |
Número de óbitos |
Idade do óbito dos trabalhadores |
2019 |
4 |
22 |
42 | ||
35 | ||
60 | ||
2020 |
0 |
- |
2021 |
4 |
35 |
40 | ||
28 | ||
27 | ||
2022 |
1 |
38 |
2023 |
1 |
55 |
Considerando a idade para aposentadoria de 65 anos, assinale o valor correto para o índice Anos Potenciais Perdidos (APP).
Para resolver as questões 29 e 30, tome o texto seguinte como motivador
Distribuição Normal
A distribuição normal é um modelo bastante útil na estatística, e não seria uma surpresa pois a soma de efeitos independentes (ou efeitos não muito correlacionados) deveriam, se houvesse muitos desses, se distribuir normalmente (sempre sujeito a certos pressupostos).
Nos séculos dezoito e dezenove, alguns matemáticos e físicos desenvolveram uma função densidade de probabilidade que descrevia os erros experimentais obtidos em medidas físicas. De certa forma todo e qualquer processo de mensuração está sujeito a um erro de medida. Esse erro pode ter diferentes fontes, desde a variação de temperatura, tempo, entre inúmeras outras características não identificáveis.
Na época (século dezoito) a sua aplicação inicial era apenas como uma conveniente aproximação da distribuição binomial, mais tarde no século XIX a distribuição normal ganhou importância com os trabalhos de Abraham de Moivre (em The Doctrine of Chances), Pierre Simon Laplace e Carl Friedrich Gauss.
A grande utilidade dessa distribuição (função densidade de probabilidade) está associada ao fato de que aproxima de forma bastante satisfatória as curvas de frequências de medidas físicas, essa curva é conhecida como distribuição normal ou gaussina.
(In: https://www.inf.ufsc.br/~andre.zibetti/probabilidade/normal.html. Adaptado. Acessado em 8/1/2023)
Considerando que numa distribuição normal a curva é simétrica em relação á origem, a relação verdadeira entre os valores da média aritmética (MA), moda (Mo) e mediana (Me) é
Para resolver as questões 29 e 30, tome o texto seguinte como motivador
Distribuição Normal
A distribuição normal é um modelo bastante útil na estatística, e não seria uma surpresa pois a soma de efeitos independentes (ou efeitos não muito correlacionados) deveriam, se houvesse muitos desses, se distribuir normalmente (sempre sujeito a certos pressupostos).
Nos séculos dezoito e dezenove, alguns matemáticos e físicos desenvolveram uma função densidade de probabilidade que descrevia os erros experimentais obtidos em medidas físicas. De certa forma todo e qualquer processo de mensuração está sujeito a um erro de medida. Esse erro pode ter diferentes fontes, desde a variação de temperatura, tempo, entre inúmeras outras características não identificáveis.
Na época (século dezoito) a sua aplicação inicial era apenas como uma conveniente aproximação da distribuição binomial, mais tarde no século XIX a distribuição normal ganhou importância com os trabalhos de Abraham de Moivre (em The Doctrine of Chances), Pierre Simon Laplace e Carl Friedrich Gauss.
A grande utilidade dessa distribuição (função densidade de probabilidade) está associada ao fato de que aproxima de forma bastante satisfatória as curvas de frequências de medidas físicas, essa curva é conhecida como distribuição normal ou gaussina.
(In: https://www.inf.ufsc.br/~andre.zibetti/probabilidade/normal.html. Adaptado. Acessado em 8/1/2023)
Considere que para se normalizar uma certa distribuição, um estatístico tinha a sua disposição uma média amostral de 3 e uma variância amostral de 25. Para utilizar o desvio padrão amostral, o estatístico deve utilizar o valor
Em relação aos sistemas de medidas, noções de estatística e probabilidade, analise as assertivas abaixo e assinale V, se verdadeiras, ou F, se falsas.
( ) Dados analíticos são sempre baseados em valores de “pesos” para descrever as quantidades das substâncias ou objetos.
( ) Peso é uma medida invariável da quantidade de matéria contida em um objeto ou substância.
( ) As medidas sempre contêm erros e incertezas. A precisão indica a proximidade da medida com o valor real ou aceitável.
( ) Três termos são utilizados para descrever a precisão de um conjunto de dados em réplicas: desvio padrão, variância e coeficiente de variação.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é: