Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 13.775 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
Itame
Órgão:
Prefeitura de Paraúna - GO
Prova:
Itame - 2024 - Prefeitura de Paraúna - GO - Assistente de Creche |
Q3376273
Estatística
Um professor quer analisar as notas de 7 alunos em
uma prova. As notas são as seguintes: 85, 90, 75, 90,
95, 70, 85. Qual é a média, a mediana e a moda dessas
notas?
Ano: 2024
Banca:
Nosso Rumo
Órgão:
IPRESB - SP
Prova:
Nosso Rumo - 2024 - IPRESB - SP - Analista Previdenciário – Economista |
Q3368831
Estatística
De acordo com o Censo 2022, realizado pelo IBGE, observe a Pirâmide Etária abaixo:
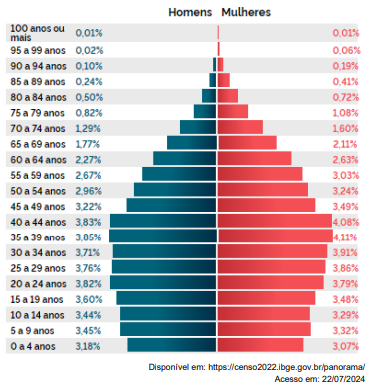
Diante do exposto, é INCORRETO afirmar que:
Ano: 2024
Banca:
OBJETIVA
Órgão:
Câmara de Nova Ramada - RS
Provas:
OBJETIVA - 2024 - Câmara de Nova Ramada - RS - Contador
|
OBJETIVA - 2024 - Câmara de Nova Ramada - RS - Oficial Legislativo |
Q3357652
Estatística
Uma companhia aérea resolveu marcar um novo voo, no mesmo estado, entre a região metropolitana e o interior. Por algum motivo, há pequenas diferenças de distância em cada voo, então, para controle, nos primeiros três meses, a companhia registrou a distância percorrida.
Os dados registrados foram: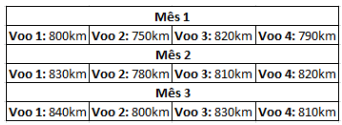
Com base no quadro, assinalar a alternativa CORRETA.
Os dados registrados foram:
Com base no quadro, assinalar a alternativa CORRETA.
Ano: 2024
Banca:
FGV
Órgão:
EBSERH
Prova:
FGV - 2024 - EBSERH - Residência Multi e Uniprofissional - Ciências Biológicas |
Q3347624
Estatística
Joaquim tem um conjunto de dados sobre a variação do
hematócrito em pacientes acometidos por quatro doenças
hematológicas distintas.
Com o objetivo de comparar os dados de hematócrito entre os pacientes portadores de cada uma das doenças, ele pretende utilizar o teste t com as comparações sendo repetidas dois a dois, da seguinte maneira: doença 1 vs. doença 2; doença 1 vs. doença 3; doença 1 vs. doença 4; doença 2 vs. doença 3; doença 2 vs. doença 4; doença 3 vs. doença 4.
Sobre essa proposta de comparação estatística dos dados, foi sugerido a Joaquim utilizar a análise de variância (ANOVA) ao invés do teste t.
De acordo com essa sugestão, a ANOVA é o teste mais recomendado porque, ao realizar múltiplos testes t, ocorre o aumento da
Com o objetivo de comparar os dados de hematócrito entre os pacientes portadores de cada uma das doenças, ele pretende utilizar o teste t com as comparações sendo repetidas dois a dois, da seguinte maneira: doença 1 vs. doença 2; doença 1 vs. doença 3; doença 1 vs. doença 4; doença 2 vs. doença 3; doença 2 vs. doença 4; doença 3 vs. doença 4.
Sobre essa proposta de comparação estatística dos dados, foi sugerido a Joaquim utilizar a análise de variância (ANOVA) ao invés do teste t.
De acordo com essa sugestão, a ANOVA é o teste mais recomendado porque, ao realizar múltiplos testes t, ocorre o aumento da
Ano: 2024
Banca:
FGV
Órgão:
EBSERH
Prova:
FGV - 2024 - EBSERH - Residência Multi e Uniprofissional - Ciências Biológicas |
Q3347614
Estatística
O acompanhamento da glicemia (mg/dL) durante um período de
cinco meses consecutivos para os pacientes Jair, Luiz, Marina e
Tarcísio é exibido na tabela a seguir.
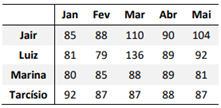
Com base na Tabela, considerando as medidas de tendência central e variabilidade, assinale a afirmativa correta.
Com base na Tabela, considerando as medidas de tendência central e variabilidade, assinale a afirmativa correta.
Ano: 2024
Banca:
IDCAP
Órgão:
Prefeitura de Serra - ES
Prova:
IDCAP - 2024 - Prefeitura de Serra - ES - Agente Municipal de Trânsito |
Q3347302
Estatística
Em estatística, as medidas de tendência central e as
medidas de dispersão são fundamentais para entender a
natureza e a distribuição dos dados. Acerca destes
conhecimentos julgue afirmações a seguir:
I. A média é a medida de tendência central que é calculada somando todos os valores de um conjunto de dados e dividindo o total pelo número de valores.
II. A mediana é sempre igual à média em qualquer distribuição de dados.
III. O desvio-padrão é uma medida de dispersão que mostra quão dispersos estão os dados em relação à média.
IV. A amplitude é calculada como a diferença entre o maior e o menor valor de um conjunto de dados.
Assinale a alternativa correta:
I. A média é a medida de tendência central que é calculada somando todos os valores de um conjunto de dados e dividindo o total pelo número de valores.
II. A mediana é sempre igual à média em qualquer distribuição de dados.
III. O desvio-padrão é uma medida de dispersão que mostra quão dispersos estão os dados em relação à média.
IV. A amplitude é calculada como a diferença entre o maior e o menor valor de um conjunto de dados.
Assinale a alternativa correta:
Ano: 2024
Banca:
FGV
Órgão:
EBSERH
Prova:
FGV - 2024 - EBSERH - Residência Multi e Uniprofissional - Biomedicina |
Q3346364
Estatística
Em um estudo clínico, pesquisadores estão avaliando a eficácia
de quatro diferentes tratamentos para hipertensão. Eles medem
a pressão arterial dos pacientes após o tratamento e desejam
determinar se há uma diferença significativa nas médias das
pressões arteriais entre os quatro grupos de tratamento.
Assinale a opção que indica o método estatístico mais apropriado para essa análise.
Assinale a opção que indica o método estatístico mais apropriado para essa análise.
Ano: 2024
Banca:
FUMARC
Órgão:
Prefeitura de Betim - MG
Prova:
FUMARC - 2024 - Prefeitura de Betim - MG - Epidemiólogo |
Q3345782
Estatística
Os dados da tabela 3 referem-se à taxa de colesterol (mg/dL) de uma turma de 50
adultos jovens entre 29 e 49 anos do município de Betim.
Complete a tabela a seguir e julgue as afirmativas a seguir, identificando-as com V ou F, conforme sejam verdadeiras ou falsas:
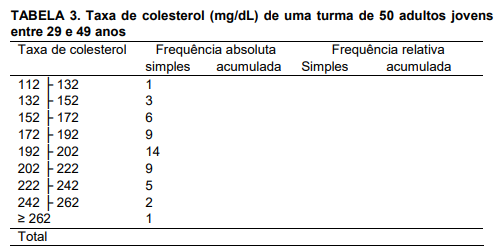
( ) A frequência relativa simples de adultos jovens com taxa de colesterol entre 112 mg/dL e 131 mg/dL é de 2%, bem como a frequência relativa acumulada.
( ) A frequência absoluta acumulada de adultos jovens com taxa de colesterol entre 112 mg/dL e 201 mg/dL é de 33, o que corresponde a uma frequência relativa acumulada de 70%.
( ) Trinta e oito por cento dos adultos jovens apresentaram taxa de colesterol entre 112 mg/dL e 191 mg/dL.
( ) Cem por cento dos adultos jovens apresentaram taxa de colesterol até 261 mg/dL.
A sequência CORRETA, de cima para baixo, é:
Complete a tabela a seguir e julgue as afirmativas a seguir, identificando-as com V ou F, conforme sejam verdadeiras ou falsas:
( ) A frequência relativa simples de adultos jovens com taxa de colesterol entre 112 mg/dL e 131 mg/dL é de 2%, bem como a frequência relativa acumulada.
( ) A frequência absoluta acumulada de adultos jovens com taxa de colesterol entre 112 mg/dL e 201 mg/dL é de 33, o que corresponde a uma frequência relativa acumulada de 70%.
( ) Trinta e oito por cento dos adultos jovens apresentaram taxa de colesterol entre 112 mg/dL e 191 mg/dL.
( ) Cem por cento dos adultos jovens apresentaram taxa de colesterol até 261 mg/dL.
A sequência CORRETA, de cima para baixo, é:
Ano: 2024
Banca:
VUNESP
Órgão:
HCFMUSP
Prova:
VUNESP - 2024 - HCFMUSP - Residência Multiprofisisonal - Farmácia Transacional |
Q3342270
Estatística
O coeficiente de correlação que pode ser utilizado quando os dados apresentam distribuição normal é o coeficiente de
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Análise, desenvolvimento e validação de metodologias para o controle físico-químico de produtos sujeitos à vigilância sanitária |
Q3341041
Estatística
O coeficiente de correlação (R2) entre a concentração
das soluções de MR de 2,3´-DHF e as absorbâncias encontradas foi de 0,99986. O valor do R2 é um dos parâmetros
utilizados para avaliar se a análise foi adequada. Sobre
esse valor pode-se dizer que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Vigilância em Saúde |
Q3341013
Estatística
Para que o modelo de regressão linear seja confiável
e válido, os seguintes pressupostos devem ser satisfeitos,
EXCETO:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Controle de Qualidade de insumos e medicamentos |
Q3339202
Estatística
A linearidade é a capacidade de um método de gerar
respostas analíticas diretamente proporcionais à concentração de um analito em uma amostra. De acordo com a
RDC nº 166/17, sobre a avaliação estatística da linearidade,
avalie as afirmativas abaixo:
I. O coeficiente de correlação (r²) deve estar acima de 0,990.
II. O coeficiente angular deve ser igual a zero.
III. Nos testes estatísticos, deve ser utilizado um nível de significância de 5%.
IV. É esperado que o coeficiente linear seja estatisticamente diferente de zero.
V. Para avaliar se os dados são homocedásticos ou não, é recomendado aplicar o teste F da Anova.
Sobre as afirmativas acima, pode-se dizer que:
I. O coeficiente de correlação (r²) deve estar acima de 0,990.
II. O coeficiente angular deve ser igual a zero.
III. Nos testes estatísticos, deve ser utilizado um nível de significância de 5%.
IV. É esperado que o coeficiente linear seja estatisticamente diferente de zero.
V. Para avaliar se os dados são homocedásticos ou não, é recomendado aplicar o teste F da Anova.
Sobre as afirmativas acima, pode-se dizer que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Taxonomia e sistemá ca de insetos vetores, com ênfase em simulídeos, ceraptopogonídeos e triatomíneos e curadoria de coleções entomológicas |
Q3337599
Estatística
Na inferência bayesiana, as incertezas associadas aos
parâmetros do modelo são tratadas de forma:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Gestão de Equipamentos e Metrologia Física, Química e Biológica |
Q3335976
Estatística
Considerando dois conjuntos (A e B) de resultados de
um mesmo material com desvio padrão diferentes: 0,29
para o conjunto A e 0,34 para o conjunto B, podemos
afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Gestão de Equipamentos e Metrologia Física, Química e Biológica |
Q3335944
Estatística
A avaliação tipo B da incerteza é aplicada quando o
analista que realiza os ensaios não tem condições de gerar
os resultados de determinadas fontes, como por exemplo,
de calibração de equipamentos, de massas moleculares
etc. Nestes casos, os dados são fornecidos por certificados,
manuais ou literatura científica, e não podem ser alterados
pelo analista. Com base nas informações disponíveis sobre
as componentes da fonte de incerteza avaliada, deve-se
considerar a distribuição de probabilidade mais adequada
aos dados. Os tipos de distribuição de probabilidade geralmente utilizados são: retangular (ou uniforme), triangular
e normal (ou Gaussiana). (Fonte: Incerteza de medição
em ensaios físico-químicos: uma abordagem prática /
Oliveira, Camila Cardoso de ... [et al.]. - São Paulo: SESSP, 2015.140p)
Em relação aos tipos de distribuição de probabilidade, pode-se afirmar que:
I. A distribuição de probabilidade normal é expressa por um gráfico simétrico que possui a forma de sino, também chamado de curva Gaussiana.
II. Assume-se que os dados provêm de uma distribuição retangular quando há conhecimento específico dos possíveis valores da grandeza de entrada.
III. Em geral, aplica-se a distribuição triangular em medições realizadas em instrumentos de indicação digital.
Sobre as afirmativas acima, pode-se dizer que:
Em relação aos tipos de distribuição de probabilidade, pode-se afirmar que:
I. A distribuição de probabilidade normal é expressa por um gráfico simétrico que possui a forma de sino, também chamado de curva Gaussiana.
II. Assume-se que os dados provêm de uma distribuição retangular quando há conhecimento específico dos possíveis valores da grandeza de entrada.
III. Em geral, aplica-se a distribuição triangular em medições realizadas em instrumentos de indicação digital.
Sobre as afirmativas acima, pode-se dizer que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Controle de qualidade toxicológico |
Q3334283
Estatística
Sobre a Precisão e a Exatidão, de acordo com a RDC
Nº 27, DE 17 DE MAIO DE 2012, é correto afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Controle sanitário e genético de Animais de Laboratório |
Q3332694
Estatística
Em uma colônia contendo pelo menos 100 animais
da mesma linhagem, e mantidos em gaiolas abertas sob
procedimentos convencionais de manuseio, a chamada
‘fórmula ILAR’ pode ser usada para estimar o tamanho da
amostra necessária para a avaliação do status microbiológico. É correto afirmar que segue corretamente a fórmula
ILAR na estimativa do número amostral para avaliação do
status microbiológico:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Jornalista Web |
Q3332251
Estatística
Histogramas têm sido um dos recursos usados para
visualização de dados. Eles são diferentes de gráficos de
barras porque:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Citometria de fluxo |
Q3331594
Estatística
A análise que pode ser realizada para se calcular a
imprecisão de um resultado laboratorial é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331509
Estatística
Considere a seguinte implementação de um modelo de
regressão linear múltipla utilizando NumPy e scikit-learn,
usado para prever o financiamento de projetos com base
em características de projetos e pesquisadores. O código
abaixo foi executado e algumas métricas de desempenho
foram obtidas.
import numpy as np from sklearn.model_selection import train_ test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
X = np.array([[1, 50], [2, 60], [3, 70], [4, 80], [5, 90], [1, 55], [2, 65], [3, 75], [4, 85], [5, 95]]) y = np.array([100000, 120000, 150000, 200000, 250000, 110000, 130000, 170000, 230000, 290000]) X_train, X_test, y_train, y_test = train_ test_split(X, y, test_size=0.2, random_ state=0)
model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test)
r2 = r2_score(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test, y_pred)
print(f”R-Quadrado: {r2}, MSE: {mse}, RMSE: {rmse}, MAE: {mae}”)
Após executar o código, foram obtidas as seguintes métricas de desempenho:
R-Quadrado: 0.9020746527777778 , MSE: 156680555.5555556, R M S E : 1 2 5 1 7 . 2 1 0 3 7 4 3 4 2 8 2 3 , M A E : 10083.333333333343
Com base nessas informações, analise as observações abaixo.
I. O valor de R-Quadrado próximo de 1 indica que o modelo explica uma grande proporção da variância dos dados de financiamento. Isso sugere que o modelo tem um bom ajuste aos dados, sendo capaz de capturar uma grande parte da relação entre as variáveis independentes e a variável dependente.
II. Um valor de MSE de aproximadamente 156 milhões sugere que, em média, o quadrado dos erros das previsões do modelo em relação aos valores reais é significativo. Isso indica que o modelo tem um bom ajuste de acordo e não existem erros consideráveis nas previsões.
III. Um MAE de aproximadamente 10083 sugere que, em média, as previsões do modelo desviam cerca de 10083 unidades dos valores reais. Comparado ao RMSE, o MAE não dá um peso tão grande a erros maiores, o que sugere que o modelo pode ter um número relativamente consistente de pequenos a moderados erros de previsão.
IV.A diferença entre o RMSE e o MAE sugere que o modelo pode estar lidando com alguns outliers ou previsões particularmente imprecisas que afetam mais o RMSE, pois o RMSE penaliza mais erros maiores do que erros menores.
Sobre as afirmativas acima, pode-se dizer que:
import numpy as np from sklearn.model_selection import train_ test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
X = np.array([[1, 50], [2, 60], [3, 70], [4, 80], [5, 90], [1, 55], [2, 65], [3, 75], [4, 85], [5, 95]]) y = np.array([100000, 120000, 150000, 200000, 250000, 110000, 130000, 170000, 230000, 290000]) X_train, X_test, y_train, y_test = train_ test_split(X, y, test_size=0.2, random_ state=0)
model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test)
r2 = r2_score(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test, y_pred)
print(f”R-Quadrado: {r2}, MSE: {mse}, RMSE: {rmse}, MAE: {mae}”)
Após executar o código, foram obtidas as seguintes métricas de desempenho:
R-Quadrado: 0.9020746527777778 , MSE: 156680555.5555556, R M S E : 1 2 5 1 7 . 2 1 0 3 7 4 3 4 2 8 2 3 , M A E : 10083.333333333343
Com base nessas informações, analise as observações abaixo.
I. O valor de R-Quadrado próximo de 1 indica que o modelo explica uma grande proporção da variância dos dados de financiamento. Isso sugere que o modelo tem um bom ajuste aos dados, sendo capaz de capturar uma grande parte da relação entre as variáveis independentes e a variável dependente.
II. Um valor de MSE de aproximadamente 156 milhões sugere que, em média, o quadrado dos erros das previsões do modelo em relação aos valores reais é significativo. Isso indica que o modelo tem um bom ajuste de acordo e não existem erros consideráveis nas previsões.
III. Um MAE de aproximadamente 10083 sugere que, em média, as previsões do modelo desviam cerca de 10083 unidades dos valores reais. Comparado ao RMSE, o MAE não dá um peso tão grande a erros maiores, o que sugere que o modelo pode ter um número relativamente consistente de pequenos a moderados erros de previsão.
IV.A diferença entre o RMSE e o MAE sugere que o modelo pode estar lidando com alguns outliers ou previsões particularmente imprecisas que afetam mais o RMSE, pois o RMSE penaliza mais erros maiores do que erros menores.
Sobre as afirmativas acima, pode-se dizer que: