Foram encontradas 673 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
I. No modelo Simple Recovery, o banco de dados pode ser recuperado até o ponto de último backup, full ou differential.
II. No modelo Full Recovery, o banco de dados pode ser recuperado até o ponto da falha, ou certo ponto no tempo.
III. O modelo bulk model não requer backup dos logs na recuperação.
Está correto somente o que se afirma em:
R (A, B, C, D, E)
Sobre essas colunas (ou atributos), João levantou as dependências funcionais seguintes.
A -> B B -> C C -> D D -> E D -> A
Dentre os esquemas SQL esboçados por João, o que melhor representa a tabela R, com suas restrições, é:
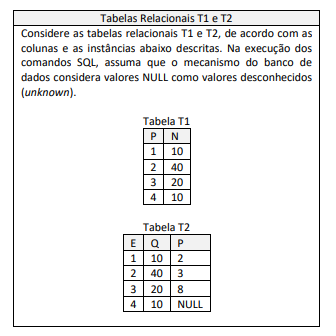
(1) P -> N (2) N -> P (3) E -> Q (4) E -> P (5) Q -> P (6) Q -> E (7) P -> E (8) P -> Q
Dessa lista enumerada, o conjunto completo das únicas dependências funcionais que poderiam ser corretamente depreendidas é:
select * from T1 full outer join T2 on T1.P=T2.P
Além da linha de títulos, a execução desse comando produz um resultado com:
delete from T2 where P not in (select P from T2)
O número de linhas deletadas da tabela T2 pela execução desse comando é:
select case when exists (select * from T2 where T2.E = 2 and T2.P = 3 and exists (select * from T1 where T1.P in (2,3,4) and T2.E in (2,3))) then 1 else 0 end flag
Sobre uma eventual execução desse script, é correto afirmar que:
Observe o seguinte Diagrama de Classes UML.
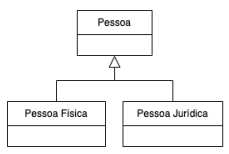
A relação entre as Classes que está representada no diagrama é:
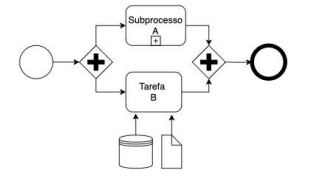
Ao analisar o diagrama elaborado por Júnior, Carlos observou o seguinte erro de notação:
João recorreu ao recurso do Kubernetes:
A classe Acoes, criada por Débora, aplica o conceito do DDD:
Considere o seguinte código em JavaScript com React
import React from 'react';
function Number() {
let x = 5, y = 5;
const [n, setN] = React.useState(x);
React.useEffect(() => {
setN(x => x + n);
setN(y => x + y);
}, [])
return n;
}
Ao se utilizar o componente funcional Number, o valor retornado
por Number após a renderização final será:
À luz da arquitetura hexagonal, ao implementar o repositório da camada de persistência e o teste automatizado, Joana adicionou à ParaibaCerta, respectivamente:
Ana recorreu ao comando do npm:
const num = 1_2_3_4_5+1_0; console.log(num)
Ao ser executado, o código acima exibe o seguinte texto no console:
Para restringir a herança na declaração da classe CGEPrincipal, José utilizou a funcionalidade do Java 17:
Considere o seguinte trecho de código de uma página web:
<div id="opcoes" class="vert">
<div class="item">Contratos</div>
<div class="item">Convênios</div>
<div class="item">Licitações</div>
</div>
E o respectivo código de Cascading Style Sheets:
.vert {
display: flex;
width: max-content;
}
.item {
flex: auto;
width: 110px;
}
Ao ser renderizado por um navegador web padrão, o elemento
com id “opcoes” do código acima exibe três elementos div:
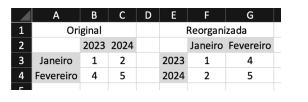
No Excel, para girar os dados de colunas para linhas, ou vice-versa, Maitê deve utilizar a função:
Observe o seguinte código escrito em Python.
import json
x = '{"nome":"Junior", "idade":5,
"brinquedo":["Carro", "Bola", "Trem", "Barco",
"Urso"]}';
y = json.loads(x)
z = len(y)
print(y["brinquedo"][int(z)])
O resultado da execução do código Python apresentado é:
Maria está implementando o Audit-DataMart para apoiar análises sobre a quantidade de auditorias realizadas por cidade e por período. Para isso, Maria elaborou o modelo multidimensional de dados no qual a dimensão tempo se relaciona com a tabela fato duas vezes, uma representando a data de início da auditoria e a outra representando a data do fim da auditoria, conforme ilustrado a seguir.
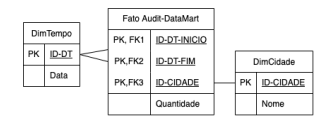
A técnica de modelagem multidimensional de dados utilizada por
Maria para referenciar múltiplas vezes uma única dimensão física
na tabela fato é:
• Produto A (Preço: R$ 50 e Peso: 300g) • Produto B (Preço: R$ 500 e Peso: 1000g)
Além disso, ele observa a presença de outliers nos dados. Nesse sentido, João deverá tratar os dados para garantir que as variáveis tenham uma distribuição normal, isto é, com média igual a zero e desvio padrão igual a um.
Para isso, a técnica de tratamento de dados que João deverá utilizar, levando em consideração a presença de outliers, é: