Foram encontradas 5.213 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Julgue o próximo item, relativo à normalização de dados, à modelagem de dados NoSQL e ao DataMesh.
A primeira forma normal (1FN) será satisfeita quando todos os atributos tiverem domínio atômico, ou seja, quando não houver valores compostos ou repetitivos.
Julgue o próximo item, relativo à normalização de dados, à modelagem de dados NoSQL e ao DataMesh.
O DataMesh adota um modelo centralizado de governança e integração de dados, priorizando a consistência sobre a escalabilidade.
Julgue o próximo item, relativo à normalização de dados, à modelagem de dados NoSQL e ao DataMesh.
No DataMesh, os dados são tratados como produtos, e cada domínio é responsável por fornecer, manter e documentar seus próprios dados.
Julgue o próximo item, relativo a manipulação, tratamento e visualização de dados, ETL e ELT, e MLOps.
No tratamento de valores ausentes em conjuntos de dados, a imputação baseada em modelos como KNN ou regressão geralmente preserva melhor as relações estatísticas entre variáveis do que métodos simples como substituição pela média ou mediana, especialmente quando os dados não estão ausentes completamente ao acaso (MCAR).
Julgue o próximo item, relativo a manipulação, tratamento e visualização de dados, ETL e ELT, e MLOps.
A principal vantagem da transição de ETL para ELT é a redução do tempo de processamento, já que a transformação dos dados ocorre antes do carregamento no data warehouse, otimizando o uso de recursos computacionais.
Julgue o próximo item, relativo a manipulação, tratamento e visualização de dados, ETL e ELT, e MLOps.
Na implementação de MLOps, o monitoramento de modelos em produção deve centrar-se nas métricas de desempenho técnico como a latência, sendo a detecção de viés algorítmico uma preocupação restrita à fase de desenvolvimento do modelo.
Acerca de inteligência artificial (IA), julgue o seguinte item.
Nos modelos generativos baseados em difusão, como o stable diffusion, o processo de geração de imagens ocorre por meio da aplicação sequencial de ruído gaussiano em uma imagem inicial em branco, consoante o mesmo procedimento do treinamento, mas em escala reduzida, para otimizar o tempo de processamento.
Acerca de inteligência artificial (IA), julgue o seguinte item.
Em redes neurais artificiais, as funções de ativação não lineares são essenciais para que o modelo possa aprender representações complexas, uma vez que múltiplas camadas de transformações lineares equivaleriam a uma única transformação linear.
Acerca de inteligência artificial (IA), julgue o seguinte item.
No processamento de linguagem natural, os modelos baseados em arquitetura transformer superaram as RNN e LSTM principalmente pela capacidade de tais modelos processarem sequências mais longas com menor custo computacional.
Acerca de inteligência artificial (IA), julgue o seguinte item.
As redes neurais convolucionais (CNN) são fundamentais para tarefas de visão computacional porque implementam operações de convolução que permitem a extração hierárquica de características visuais, desde bordas e texturas em camadas iniciais, até estruturas mais complexas em camadas profundas.
A respeito de aprendizagem de máquina, julgue o item que se segue.
Em validação cruzada k-fold, cada instância do conjunto de dados é utilizada uma única vez para teste, o que garante avaliação equilibrada.
A respeito de aprendizagem de máquina, julgue o item que se segue.
A aplicação de PCA (análise de componentes principais) em contexto não supervisionado independe de rótulos para extrair componentes de maior variância.
A respeito de aprendizagem de máquina, julgue o item que se segue.
A regularização L2 (ridge) reduz a magnitude dos coeficientes sem anulá-los completamente, o que pode mitigar o overfitting, mas não realiza seleção automática de variáveis.
A respeito de aprendizagem de máquina, julgue o item que se segue.
No agrupamento hierárquico, ao contrário do k-means, não se exige especificação prévia do número de clusters.
A respeito de aprendizagem de máquina, julgue o item que se segue.
O modelo de aprendizado supervisionado ajusta uma função de mapeamento a partir de exemplos rotulados para generalizar dados ainda não vistos.
A respeito de aprendizagem de máquina, julgue o item que se segue.
No algoritmo Apriori, utilizado para mineração de regras de associação, o princípio da monotonicidade estabelece que, se um itemset for frequente, então todos os seus superconjuntos também serão frequentes, o que permite uma poda eficiente do espaço de busca.
Em estudo conduzido acerca da consonância dos preços praticados pelas seguradoras com a estrutura atuarial de risco, um analista concluiu que a distribuição de probabilidade dos prêmios (em R$) cobrados para veículos de perfil de baixo risco pode ser representada por uma variável aleatória contínua X, cuja função de densidade de probabilidade é representada por
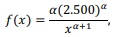
em que x ≥ R$ 2.500, e α é o parâmetro de forma conhecido como índice de Pareto.
Com base nessas informações, julgue o próximo item.
O estimador de máxima verossimilhança para o índice de Pareto α é dado em função da média dos valores dos prêmios observados em uma amostra aleatória simples.
Em estudo conduzido acerca da consonância dos preços praticados pelas seguradoras com a estrutura atuarial de risco, um analista concluiu que a distribuição de probabilidade dos prêmios (em R$) cobrados para veículos de perfil de baixo risco pode ser representada por uma variável aleatória contínua X, cuja função de densidade de probabilidade é representada por
em que x ≥ R$ 2.500, e α é o parâmetro de forma conhecido como índice de Pareto.
Com base nessas informações, julgue o próximo item.
Caso um analista selecione uma amostra aleatória simples de
apólices desse tipo de seguro cuja distribuição de
probabilidade seja descrita pela variável aleatória X, então,
se a média amostral dos prêmios for igual a R$ 3.125, 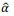 = 5
representa uma estimativa de momentos para o
índice de Pareto.
= 5
representa uma estimativa de momentos para o
índice de Pareto.
Em estudo conduzido acerca da consonância dos preços praticados pelas seguradoras com a estrutura atuarial de risco, um analista concluiu que a distribuição de probabilidade dos prêmios (em R$) cobrados para veículos de perfil de baixo risco pode ser representada por uma variável aleatória contínua X, cuja função de densidade de probabilidade é representada por
em que x ≥ R$ 2.500, e α é o parâmetro de forma conhecido como índice de Pareto.
Com base nessas informações, julgue o próximo item.
Se α = 1, obtém-se a probabilidade P(X = R$ 5.000) igual a 0,0001.
Em estudo conduzido acerca da consonância dos preços praticados pelas seguradoras com a estrutura atuarial de risco, um analista concluiu que a distribuição de probabilidade dos prêmios (em R$) cobrados para veículos de perfil de baixo risco pode ser representada por uma variável aleatória contínua X, cuja função de densidade de probabilidade é representada por
em que x ≥ R$ 2.500, e α é o parâmetro de forma conhecido como índice de Pareto.
Com base nessas informações, julgue o próximo item.
O erro padrão teórico do estimador de máxima
verossimilhança de é igual a α/√n, em que n representa
um tamanho de amostra suficientemente grande.