Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 2.117 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2012
Banca:
CESPE / CEBRASPE
Órgão:
Banco da Amazônia
Prova:
CESPE - 2012 - Banco da Amazônia - Técnico Científico - Banco de Dados |
Q256753
Banco de Dados
Assim como nos modelos que o precedem, o modelo relacional de dados precisa de caminhos predefinidos para que os dados sejam acessados.
Ano: 2012
Banca:
CESPE / CEBRASPE
Órgão:
Banco da Amazônia
Prova:
CESPE - 2012 - Banco da Amazônia - Técnico Científico - Banco de Dados |
Q256752
Banco de Dados
A estrutura fundamental do modelo relacional de dados é a relação, na forma de tabela, constituída por um ou mais atributos — os campos —, que traduzem o tipo de dados a armazenar. Cada instância do esquema — linha — é chamada de tupla ou registro.
Ano: 2012
Banca:
CESPE / CEBRASPE
Órgão:
Banco da Amazônia
Prova:
CESPE - 2012 - Banco da Amazônia - Técnico Científico - Banco de Dados |
Q256751
Banco de Dados
Julgue os próximos itens, acerca dos sistemas gerenciadores de banco de dados que implementam o modelo relacional de dados.
O modelo relacional de dados necessita que programas ou sistemas implementem regras para evitar características indesejáveis, tais como repetição de informação, incapacidade de representar parte da informação e perda de informação.
O modelo relacional de dados necessita que programas ou sistemas implementem regras para evitar características indesejáveis, tais como repetição de informação, incapacidade de representar parte da informação e perda de informação.
Ano: 2012
Banca:
CESPE / CEBRASPE
Órgão:
Banco da Amazônia
Prova:
CESPE - 2012 - Banco da Amazônia - Técnico Científico - Banco de Dados |
Q256750
Banco de Dados
A utilização de SGBD permite o gerenciamento do acesso concorrente, ou seja, permite atualizações simultâneas nos dados para aumento do desempenho do sistema como um todo e para melhores tempos de resposta.
Ano: 2012
Banca:
CESPE / CEBRASPE
Órgão:
Banco da Amazônia
Prova:
CESPE - 2012 - Banco da Amazônia - Técnico Científico - Banco de Dados |
Q256749
Banco de Dados
SGBD, que é formado por uma coleção de arquivos e programas inter-relacionados, tem por objetivo garantir que o acesso para consultas e alterações dos dados nos arquivos seja limitado a um único administrador, responsável por efetuar as modificações e atualizações requeridas pelos usuários do sistema.
Ano: 2012
Banca:
CESPE / CEBRASPE
Órgão:
Banco da Amazônia
Prova:
CESPE - 2012 - Banco da Amazônia - Técnico Científico - Banco de Dados |
Q256748
Banco de Dados
Julgue os itens seguintes, no que se refere aos benefícios que pode trazer a utilização de sistema gerenciador de banco de dados (SGBD) em relação a sistemas de processamento de arquivos.
SGBD utiliza o conceito de atomicidade do registro, assegurando que, uma vez detectada uma falha na operação com o registro, os dados sejam salvos em seu último estado consistente, anterior a essa falha.
SGBD utiliza o conceito de atomicidade do registro, assegurando que, uma vez detectada uma falha na operação com o registro, os dados sejam salvos em seu último estado consistente, anterior a essa falha.
Q220630
Banco de Dados
Dada a função em PostGreSQL:
substring('ABCX454545DEF' from 'A[^0-9]*([0-9]{1,3})')
Após a sua execução, o resultado será:
substring('ABCX454545DEF' from 'A[^0-9]*([0-9]{1,3})')
Após a sua execução, o resultado será:
Q220629
Banco de Dados
A função INSERT(), em MySql, é utilizada para
Q220628
Banco de Dados
Procedure, em PL/SQL, é um bloco de comandos
Q220627
Banco de Dados
Em banco de dados, Triggers são
Q220626
Banco de Dados
Dentre as atribuições exclusivas de um administrador de banco de dados Oracle (DBA) consta a atividade de
Q220625
Banco de Dados
O Oracle possui processos em background que auxiliam o acesso e o controle do banco de dados. Dentre eles, destacam-se
Q220624
Banco de Dados
Analise os comandos PL/SQL:
CREATE TABLE Departamentos (Id numeric(10) not null,Descricao varchar(30) not null, CONSTRAINT Dept_pk PRIMARY KEY(Id));
CREATE TABLE Vendedores (Id numeric(10) not null,Nome varchar(30) not null,Departamento numeric(10) not null, CONSTRAINT Vendedores_pk PRIMARY KEY(Id),CONSTRAINT fk_dept FOREIGN KEY(Departamento) REFERENCES Departamentos(Id));
CREATE TABLE Vendas (Vendedor numeric(10) not null,ValordeVenda real not null,CONSTRAINT fk_vendedores FOREIGN KEY(Vendedor) REFERENCES Vendedores(Id));
O comando PL/SQL necessário para listar o nome dos vendedores que obtiveram Valor de Venda superior a 100 e que pertençam ao departamento 1 nas tabelas criadas acima deve ser:
CREATE TABLE Departamentos (Id numeric(10) not null,Descricao varchar(30) not null, CONSTRAINT Dept_pk PRIMARY KEY(Id));
CREATE TABLE Vendedores (Id numeric(10) not null,Nome varchar(30) not null,Departamento numeric(10) not null, CONSTRAINT Vendedores_pk PRIMARY KEY(Id),CONSTRAINT fk_dept FOREIGN KEY(Departamento) REFERENCES Departamentos(Id));
CREATE TABLE Vendas (Vendedor numeric(10) not null,ValordeVenda real not null,CONSTRAINT fk_vendedores FOREIGN KEY(Vendedor) REFERENCES Vendedores(Id));
O comando PL/SQL necessário para listar o nome dos vendedores que obtiveram Valor de Venda superior a 100 e que pertençam ao departamento 1 nas tabelas criadas acima deve ser:
Q220623
Banco de Dados
Quando uma transação A acessa o banco de dados, o SGBD automaticamente bloqueia cada parte do banco que essa transação altera ou requisita. Ao efetuar uma transação B em paralelo, o SGBD também bloqueia partes do banco de dados que essa transação acessa. Tais procedimentos se referem à característica de um SGBD denominada controle de
Q220622
Banco de Dados
Para preservar a consistência e integridade dos dados, um SGBD pode requerer que algumas restrições sejam aplicadas, dentre elas a restrição de integridade referencial, a qual garante que
Q220621
Banco de Dados
É uma característica de um sistema de Business Intelligence:
Q220620
Banco de Dados
Com relação a backup e restore no SQL Server 2008, é INCORRETO afirmar:
Q220619
Banco de Dados
No contexto de restrições de integridade de um SGBD, quando uma restrição define que “um empregado não pode ter um salário maior que seu superior imediato", deve ser classificada como uma restrição de integridade
.
.
Q220618
Banco de Dados
Com relação à implementação de relacionamentos em projetos de SGBDs, considere:
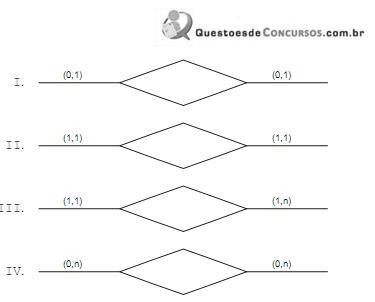
Dependendo do tipo de relacionamento, uma forma básica de tradução (1-tabela própria, 2-colunas adicionais, 3-fusão de tabelas) ou é usada preferencialmente ou é usada alternativamente ou nem deve ser usada.
Nos tipos de relacionamento apresentados acima, a alternativa de implementação de “colunas adicionais" é usada, preferencialmente, APENAS, em:
Dependendo do tipo de relacionamento, uma forma básica de tradução (1-tabela própria, 2-colunas adicionais, 3-fusão de tabelas) ou é usada preferencialmente ou é usada alternativamente ou nem deve ser usada.
Nos tipos de relacionamento apresentados acima, a alternativa de implementação de “colunas adicionais" é usada, preferencialmente, APENAS, em:
Q220617
Banco de Dados
Considere:
I. No Data Warehouse, o dado tem um valor histórico, por referir-se a algum momento específico do tempo, portanto, ele não é atualizável; a cada ocorrência de uma mudança, uma nova entrada é criada para sinalizar esta mudança.
II. O estágio de transformação no processo ETL deve ser capaz de selecionar determinadas colunas (ou nenhuma) para carregar; transformar múltiplas colunas em múltiplas linhas; traduzir e unificar códigos heterogêneos de um mesmo atributo, oriundos de diversas fontes de dados (tabelas).
III. No Snow Flake as subdimensões, por não serem normalizadas, geram aumento significativo no número de registros e, como consequência, aumentam também a quantidade de joins necessários à exibição de uma consulta.
IV. Data Mining é uma ferramenta de mineração de dados que executa a varredura nos dados históricos com o objetivo de desconsiderar o que é genérico sobre algum assunto e valorizar tudo que o for específico dentro do sistema.
Está correto o que consta em
I. No Data Warehouse, o dado tem um valor histórico, por referir-se a algum momento específico do tempo, portanto, ele não é atualizável; a cada ocorrência de uma mudança, uma nova entrada é criada para sinalizar esta mudança.
II. O estágio de transformação no processo ETL deve ser capaz de selecionar determinadas colunas (ou nenhuma) para carregar; transformar múltiplas colunas em múltiplas linhas; traduzir e unificar códigos heterogêneos de um mesmo atributo, oriundos de diversas fontes de dados (tabelas).
III. No Snow Flake as subdimensões, por não serem normalizadas, geram aumento significativo no número de registros e, como consequência, aumentam também a quantidade de joins necessários à exibição de uma consulta.
IV. Data Mining é uma ferramenta de mineração de dados que executa a varredura nos dados históricos com o objetivo de desconsiderar o que é genérico sobre algum assunto e valorizar tudo que o for específico dentro do sistema.
Está correto o que consta em