Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 3.876 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Engenheiro Mecânico (Gerenciamento de Projetos) |
Q1771485
Engenharia Mecânica
Quando se trata de ensaios destrutivos e não
destrutivos, sempre se deve ter em mente os efeitos
físicos e químicos das interações intermoleculares do
material em questão. O vetor de Burgers b, para o
deslocamento de borda, sempre é:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Engenheiro Mecânico (Gerenciamento de Projetos) |
Q1771484
Segurança e Saúde no Trabalho
A Norma Regulamentadora n° 6 (NR-6) versa
sobre os equipamentos de proteção individual (EPI) e
especifica as responsabilidades do trabalhador.
Conforme preconiza a NR-6, compete ao
trabalhador:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Engenheiro Mecânico (Gerenciamento de Projetos) |
Q1771483
Segurança e Saúde no Trabalho
A Norma Regulamentadora n° 10, que trata da
Segurança em Instalações e Serviços em
Eletricidade, especifica que o estabelecimento deve
constituir e manter um Prontuário de Instalações
Elétricas. Entretanto, esse prontuário é obrigatório
para carga instalada superior a:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Engenheiro Mecânico (Gerenciamento de Projetos) |
Q1771482
Segurança e Saúde no Trabalho
A Norma Regulamentadora n° 6 em seu anexo I
lista os equipamentos de proteção individual. São
EPIs para proteção de cabeça:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Engenheiro Mecânico (Gerenciamento de Projetos) |
Q1771481
Engenharia Mecânica
Na escala 1:75, 2,45 metros na dimensão real
equivalem na escala gráfica, aproximadamente, a:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771450
Banco de Dados
No que diz respeito à mineração de dados, Data
Mining é um processo para explorar grandes
quantidades de dados à procura de padrões
consistentes, visando transformar dados em
informações úteis, e que utiliza diversas técnicas de
análise e mineração de dados, das quais três são
caracterizadas a seguir.
I. É direcionada ao agrupamento de dados, com base em um critério de identificação de dados semelhantes, fundamental para a seleção de grupos e posterior geração de insights. II. São utilizadas com mais frequência nos estágios iniciais do processo de Data Mining que servem para modelar relações entre os dados que entram e saem do processo de mineração. Por meio do uso de algoritmos, podem reconhecer padrões escondidos e correlações em dados brutos, agrupá-los e classificá-los e, com o tempo, aprender e melhorar continuamente. III. É uma ferramenta para ajudar uma pessoa, ou um grupo de pessoas, a tomarem uma decisão ao visualizar as suas ramificações e consequências. É uma ferramenta de suporte bastante útil para orientar discussões e guiar um grupo na resolução de um problema ou, até mesmo, na elaboração de um plano de ação. É de fácil interpretação dos dados e mostra o caminho a ser percorrido para alcançar determinado objetivo.
Essas técnicas em I, II e III, são conhecidas, respectivamente, como:
I. É direcionada ao agrupamento de dados, com base em um critério de identificação de dados semelhantes, fundamental para a seleção de grupos e posterior geração de insights. II. São utilizadas com mais frequência nos estágios iniciais do processo de Data Mining que servem para modelar relações entre os dados que entram e saem do processo de mineração. Por meio do uso de algoritmos, podem reconhecer padrões escondidos e correlações em dados brutos, agrupá-los e classificá-los e, com o tempo, aprender e melhorar continuamente. III. É uma ferramenta para ajudar uma pessoa, ou um grupo de pessoas, a tomarem uma decisão ao visualizar as suas ramificações e consequências. É uma ferramenta de suporte bastante útil para orientar discussões e guiar um grupo na resolução de um problema ou, até mesmo, na elaboração de um plano de ação. É de fácil interpretação dos dados e mostra o caminho a ser percorrido para alcançar determinado objetivo.
Essas técnicas em I, II e III, são conhecidas, respectivamente, como:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771449
Banco de Dados
No que diz respeito à manipulação de dados em
bancos de dados relacionais, Stored Procedure é um
bloco de código PL/SQL armazenado no servidor
com as seguintes características:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771448
Algoritmos e Estrutura de Dados
As figuras mostram em (I) um algoritmo que
gera uma sequência de números, usando a estrutura
de controle para... faca e em (II) o resultado da
execução.
 (I)
(I)
 (II)
(II)
Duas estruturas equivalentes a para ... faca ... fimpara, que geram o mesmo resultado, a primeiro usando repita ... ate que... e a segunda enquanto... faca..., são mostradas, respectivamente, na seguinte opção:
(I) (II) Duas estruturas equivalentes a para ... faca ... fimpara, que geram o mesmo resultado, a primeiro usando repita ... ate que... e a segunda enquanto... faca..., são mostradas, respectivamente, na seguinte opção:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771447
Engenharia de Software
A modelagem de dados e os conceitos classes e
pacotes estão diretamente relacionados na
metodologia UML, uma tecnologia que se presta à
modelagem de estruturas que irão compor uma
aplicação, estando fortemente amparada em
conceitos de Orientação a Objetos. Os diferentes
diagramas que compõem a UML podem ser
agrupados em categorias, levando em consideração
o contexto do sistema em desenvolvimento. Entre os
diagramas, dois são caracterizados a seguir.
I. São diagramas estruturais que fornecem uma visão clara da estrutura hierárquica dos variados elementos UML dentro de um determinado sistema, sendo usados para mostrar a organização e disposição de vários elementos de modelos, onde cada elemento é representado como uma pasta de arquivo dentro do diagrama, e depois organizado hierarquicamente no diagrama. São bastante usados para proporcionar uma organização visual de uma arquitetura em camadas de qualquer classificador UML, por exemplo, um sistema de software. II. São diagramas que permitem a visualização de um conjunto de classes, detalhando atributos e operações, assim como prováveis relacionamentos entre as estruturas, possibilitando ainda as definições de interfaces. Ilustra graficamente como será a estrutura do software, em nível micro ou macro e como cada um dos componentes da sua estrutura estarão interligados.
As ferramentas caracterizadas em I e em II são denominados diagramas de:
I. São diagramas estruturais que fornecem uma visão clara da estrutura hierárquica dos variados elementos UML dentro de um determinado sistema, sendo usados para mostrar a organização e disposição de vários elementos de modelos, onde cada elemento é representado como uma pasta de arquivo dentro do diagrama, e depois organizado hierarquicamente no diagrama. São bastante usados para proporcionar uma organização visual de uma arquitetura em camadas de qualquer classificador UML, por exemplo, um sistema de software. II. São diagramas que permitem a visualização de um conjunto de classes, detalhando atributos e operações, assim como prováveis relacionamentos entre as estruturas, possibilitando ainda as definições de interfaces. Ilustra graficamente como será a estrutura do software, em nível micro ou macro e como cada um dos componentes da sua estrutura estarão interligados.
As ferramentas caracterizadas em I e em II são denominados diagramas de:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771446
Engenharia de Software
O conceito que está diretamente associado ao
termo software livre é:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771445
Banco de Dados
A SQL oferece a possibilidade de uso de uma
cláusula no comando SELECT para eliminar
repetições em consultas, considerando as colunas
informadas na listagem de colunas do comando
SELECT que contenham valores iguais como o
mesmo registro. Considere o caso descrito a seguir.

A figura refere-se a uma tabela AUTO de um banco de dados relacional. Para saber as marcas de automóveis envolvidas nesse caso, foi utilizada uma query SQL, que retorna essas marcas, sem repetição, indicada na
tabela SAIDA - .
.
O comando SQL empregado foi:
A figura refere-se a uma tabela AUTO de um banco de dados relacional. Para saber as marcas de automóveis envolvidas nesse caso, foi utilizada uma query SQL, que retorna essas marcas, sem repetição, indicada na
tabela SAIDA -
. O comando SQL empregado foi:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771444
Banco de Dados
No que concerne à arquitetura de sistemas de
bancos de dados Oracle, existem diversos termos
específicos, siglas e nomes de serviços e aplicações.
Entre estes termos, dois são descritos a seguir.
I. Arquivos físicos de log que permitem a recuperação da instância do banco de dados. Esses arquivos contêm um registro de todas as alterações feitas nos dados nas tabelas e índices do banco, assim como mudanças realizadas na estrutura do banco de dados em si. A instância pode recuperar o banco com as informações contidas nesses arquivos – se os datafiles não forem perdidos. II. Área da SGA que armazena dados como declarações SQL executadas, cópias do dicionário de dados do banco e cache de resultados de consultas SQL e PL/SQL para reuso. Também contém dados das tabelas de sistema, como informações do conjunto de caracteres e informações de segurança.
Os termos descritos em I e em II são denominados, respectivamente:
I. Arquivos físicos de log que permitem a recuperação da instância do banco de dados. Esses arquivos contêm um registro de todas as alterações feitas nos dados nas tabelas e índices do banco, assim como mudanças realizadas na estrutura do banco de dados em si. A instância pode recuperar o banco com as informações contidas nesses arquivos – se os datafiles não forem perdidos. II. Área da SGA que armazena dados como declarações SQL executadas, cópias do dicionário de dados do banco e cache de resultados de consultas SQL e PL/SQL para reuso. Também contém dados das tabelas de sistema, como informações do conjunto de caracteres e informações de segurança.
Os termos descritos em I e em II são denominados, respectivamente:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771443
Banco de Dados
No que diz respeito à análise das informações e
tomada de decisões, um termo possui as
características listadas a seguir.
É um sistema utilizado para armazenar dados, de uma maneira organizada.
Pode guardar informações relativas às atividades de uma organização em bancos de dados, de forma consolidada. O desenho da base de dados favorece os relatórios, a análise de grandes volumes de dados e a obtenção de informações estratégicas que podem facilitar a tomada de decisão.
Centraliza e consolida grandes quantidades de dados de várias fontes. Seus recursos analíticos permitem que as organizações obtenham informações de negócios úteis de seus dados para melhorar a tomada de decisões.
É um sistema utilizado para armazenar dados, de uma maneira organizada.
Pode guardar informações relativas às atividades de uma organização em bancos de dados, de forma consolidada. O desenho da base de dados favorece os relatórios, a análise de grandes volumes de dados e a obtenção de informações estratégicas que podem facilitar a tomada de decisão.
Centraliza e consolida grandes quantidades de dados de várias fontes. Seus recursos analíticos permitem que as organizações obtenham informações de negócios úteis de seus dados para melhorar a tomada de decisões.
Esse termo é conhecido como:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771442
Segurança da Informação
No contexto dos métodos criptográficos, a
assinatura digital permite comprovar dois aspectos
da segurança da informação: a primeira que qualifica
se a informação é documentada ou certificada como
verdadeira ou certa e a segunda que qualifica se uma
informação não foi alterada de forma não autorizada
ou indevida. A assinatura digital baseia-se no fato de
que apenas o dono conhece a chave privada e que,
se ela foi usada para codificar uma informação, então
apenas seu dono poderia ter feito isto. A verificação
da assinatura é feita com o uso da chave pública, pois
se o texto foi codificado com a chave privada,
somente a chave pública correspondente pode
decodificá-lo. Os dois aspectos de segurança da informação
mencionados acima, são, respectivamente:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771441
Banco de Dados
A SQL é conhecida comercialmente como uma
“linguagem de consulta” padrão utilizada para
manipular bases de dados relacionais, possuindo
diversos recursos na definição da estrutura de dados
para modificação de dados no banco de dados e para
a especificação de restrições de segurança. A SQL
integra três sub-linguagens, descritas a seguir.
I. Suporta comandos para manipular dados, como select, insert, update e delete. II. Suporta comandos para supervisionar o acesso aos dados, como grant e revoke. III. Suporta comandos para criação de objetos e administração do banco de dados, como alter e drop.
As sub-linguagens descritas em I, II e III são, respectivamente:
I. Suporta comandos para manipular dados, como select, insert, update e delete. II. Suporta comandos para supervisionar o acesso aos dados, como grant e revoke. III. Suporta comandos para criação de objetos e administração do banco de dados, como alter e drop.
As sub-linguagens descritas em I, II e III são, respectivamente:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771440
Banco de Dados
No contexto dos bancos de dados relacionais
SQL, muitas vezes surge a necessidade de se
realizar uma determinada ação, de acordo com algum
evento que acontecer e é isso que o Trigger viabiliza.
No que diz respeito à sintaxe para criação de um
trigger, observam-se os parâmetros descritos a
seguir.
I. NOME DO TRIGGER – identifica o nome da trigger como objeto do banco de dados, devendo seguir as regras básicas de nomenclatura de objetos. II. NOME DA TABELA – identifica o nome da tabela à qual o trigger estará ligado, para ser disparado mediante ações de insert, update ou delete. III. Opção X/Y/Z – escolhida para definir o momento em que o trigger será disparado, onde X representa o valor padrão e faz com o que o gatilho seja disparado junto da ação, Y faz com que o disparo se dê somente após a ação que o gerou ser concluída, e Z faz com que o trigger seja executado no lugar da ação que o gerou. IV. Opção M/N/P – escolhida entre as instruções DML para indicar e informar ao banco qual ação irá disparar o gatilho.
Os parâmetros que devem substituir X/Y/Z em III e M/N/P em IV são, respectivamente:
I. NOME DO TRIGGER – identifica o nome da trigger como objeto do banco de dados, devendo seguir as regras básicas de nomenclatura de objetos. II. NOME DA TABELA – identifica o nome da tabela à qual o trigger estará ligado, para ser disparado mediante ações de insert, update ou delete. III. Opção X/Y/Z – escolhida para definir o momento em que o trigger será disparado, onde X representa o valor padrão e faz com o que o gatilho seja disparado junto da ação, Y faz com que o disparo se dê somente após a ação que o gerou ser concluída, e Z faz com que o trigger seja executado no lugar da ação que o gerou. IV. Opção M/N/P – escolhida entre as instruções DML para indicar e informar ao banco qual ação irá disparar o gatilho.
Os parâmetros que devem substituir X/Y/Z em III e M/N/P em IV são, respectivamente:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771439
Banco de Dados
A tabela abaixo, faz parte de um banco de dados
relacional PostgreSQL.
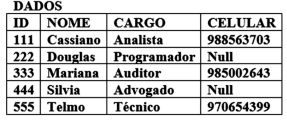
Para obter o nome e cargo de todos os funcionários, ordenando o resultado por celular em ordem alfabética de nome das pessoas que tenham celulares cadastrados, a sintaxe correta para o comando SQL a ser executado é:
Para obter o nome e cargo de todos os funcionários, ordenando o resultado por celular em ordem alfabética de nome das pessoas que tenham celulares cadastrados, a sintaxe correta para o comando SQL a ser executado é:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771438
Banco de Dados
No contexto de bancos de dados, um tipo de
restrição de integridade assegura que valores de uma
coluna em uma tabela são válidos baseados nos
valores em uma outra tabela relacionada. Por
exemplo, se um produto de COD $75DF foi
cadastrado em uma tabela de Vendas, então um
produto com COD $75DF deve existir na tabela de
produtos relacionada. Resumindo, cada valor de uma
chave estrangeira deve corresponder a um valor de
uma chave primária existente, servindo para manter a
consistência entre tuplas de duas relações, existindo
em consequência dos relacionamentos entre
entidades.
O tipo de restrição é denominado integridade:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771437
Banco de Dados
No desenvolvimento de um Banco de Dados, é
realizada, no Projeto Lógico, a seguinte atividade:
Ano: 2021
Banca:
SELECON
Órgão:
EMGEPRON
Prova:
SELECON - 2021 - EMGEPRON - Analista de Sistemas (Auditoria) |
Q1771436
Banco de Dados
A segurança de um banco de dados herda as
mesmas dificuldades que a segurança da informação
enfrenta, que é garantir a integridade, a
disponibilidade e a confidencialidade. Um SGBD
deve fornecer mecanismos que auxiliem nesta tarefa,
sendo três deles descritos a seguir.
I. É todo controle feito por meio de regras de restrição, implementadas nas contas dos usuários. O DBA é o responsável por declarar as regras dentro do SGBD, sendo o responsável por conceder ou remover privilégios, criar ou excluir usuários, e atribuir um nível de segurança aos usuários do sistema, de acordo com a política da empresa. II. É um mecanismo para BD estatísticos, que atua protegendo informações estatísticas de um indivíduo ou de um grupo. Estes tipos de BD são usados principalmente para produzir estatísticas sobre populações, podendo conter informações confidenciais. Os usuários têm permissão apenas para recuperar informações estatísticas sobre populações e não para recuperar dados individuais, como, por exemplo, a renda de uma pessoa específica. III. É um mecanismo que previne que as informações fluam por canais secretos e violem a política de segurança ao alcançarem usuários não autorizados. Ele regula tráfego de dados entre um objeto ALFA para outro BETA, que ocorre quando um programa lê valores de ALFA e escreve valores em BETA.
Os três mecanismos descritos em I, II e III são denominados, respectivamente, controle de:
I. É todo controle feito por meio de regras de restrição, implementadas nas contas dos usuários. O DBA é o responsável por declarar as regras dentro do SGBD, sendo o responsável por conceder ou remover privilégios, criar ou excluir usuários, e atribuir um nível de segurança aos usuários do sistema, de acordo com a política da empresa. II. É um mecanismo para BD estatísticos, que atua protegendo informações estatísticas de um indivíduo ou de um grupo. Estes tipos de BD são usados principalmente para produzir estatísticas sobre populações, podendo conter informações confidenciais. Os usuários têm permissão apenas para recuperar informações estatísticas sobre populações e não para recuperar dados individuais, como, por exemplo, a renda de uma pessoa específica. III. É um mecanismo que previne que as informações fluam por canais secretos e violem a política de segurança ao alcançarem usuários não autorizados. Ele regula tráfego de dados entre um objeto ALFA para outro BETA, que ocorre quando um programa lê valores de ALFA e escreve valores em BETA.
Os três mecanismos descritos em I, II e III são denominados, respectivamente, controle de: