Foram encontradas 22.509 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Os algoritmos de aprendizado supervisionado partem de um conjunto de dados rotulados para fazer previsões sobre novos dados não rotulados. O Python scikit-learn é uma biblioteca de código aberto utilizada para codificações de rotinas em aprendizado de máquina supervisionado; ela oferece ainda uma série de ferramentas utilizadas no ajuste de modelos e no pré-processamento de dados, para a seleção e avaliação de modelos.
Tendo como referência essas informações, julgue o item a seguir.
SVC, NuSCV e LinearSVC são classes do scikit-learn
capazes de realizar classificação binária e multiclasse em um
conjunto de dados.
Os algoritmos de aprendizado supervisionado partem de um conjunto de dados rotulados para fazer previsões sobre novos dados não rotulados. O Python scikit-learn é uma biblioteca de código aberto utilizada para codificações de rotinas em aprendizado de máquina supervisionado; ela oferece ainda uma série de ferramentas utilizadas no ajuste de modelos e no pré-processamento de dados, para a seleção e avaliação de modelos.
Tendo como referência essas informações, julgue o item a seguir.
No código a seguir, 
 é um
classificador que recebe como entrada dois arrays: um array X,
é um
classificador que recebe como entrada dois arrays: um array X,

O ensemble denominado bagging tem como foco principal a redução do viés e não da variância, treinando-se os modelos em sequência, tal que os erros dos primeiros modelos treinados são utilizados para o ajuste nos pesos matemáticos dos próximos modelos.
As máquinas de vetores de suporte (SVMs) são originalmente utilizadas para a classificação de dados em duas classes, ou seja, na geração de dicotomias. Nas SVMs com margens rígidas, conjuntos de treinamento linearmente separáveis podem ser classificados. Acerca das características das SVMs com margens rígidas, julgue o item a seguir.
Um conjunto linearmente separável é composto por
exemplos que podem ser separados por pelo menos um
hiperplano. As SVMs lineares buscam o hiperplano
ótimo segundo a teoria do aprendizado estatístico, definido
como aquele em que a margem de separação entre as classes
presentes nos dados é minimizada.
De acordo com os aspectos construtivos de uma árvore de decisão, julgue o item a seguir.
A entropia de uma árvore de decisão aborda o aspecto da quantidade de informações que está associada às respostas que podem ser obtidas às perguntas formuladas, representando o grau de incerteza associado aos dados.
Uma árvore de decisão representa um determinado número de caminhos possíveis de decisão e os resultados de cada um deles, apresentando muitos pontos positivos, ou seja, são fáceis de entender e interpretar. Elas têm processo de previsão completamente transparente e lidam facilmente com diversos atributos numéricos, assim como atributos categóricos, podendo até mesmo classificar dados sem atributos definidos.
De acordo com os aspectos construtivos de uma árvore de decisão, julgue o item a seguir.
Se o processo adotado para a construção de árvores de
decisão for determinístico, uma forma de obtenção de
árvores aleatórias, que compõem as florestas aleatórias, pode
ser realizada por meio do bootstrap dos dados, em que cada
árvore é treinada com base no resultado de bootstrap_sample
(inputs).
 respectivamente, as médias amostrais das variáveis x e y.
respectivamente, as médias amostrais das variáveis x e y.
Com base nos dados dessa tabela, julgue o próximo item.
Pelo modelo de regressão linear simples, a equação que
expressa o relacionamento ajustado entre a variável y em função de x é 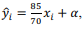 em que α é uma constante.
em que α é uma constante.
respectivamente, as médias amostrais das variáveis x e y.Com base nos dados dessa tabela, julgue o próximo item.
Uma forma de melhorar o modelo de regressão linear para a
situação em questão é utilizar o modelo de regressão
logística, uma vez que a variável dependente se apresenta de
forma quantitativa.
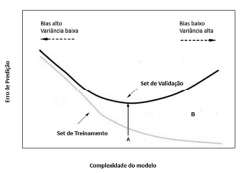
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
Quando se verifica um alto erro no treinamento com valor
próximo ao erro na validação, percebido na região à
esquerda do ponto A, tem-se um clássico problema de
underfitting, caracterizado pelo alto valor do bias.
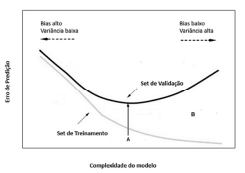
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
Considerando que a variância é um erro de sensibilidade para
pequenas flutuações no conjunto de treinamento, infere-se
que um baixo nível de variância pode fazer que o algoritmo
associado a um modelo de aprendizado de máquina perca as
relações relevantes entre os atributos de entrada e a variável
de saída, caracterizando o erro de overfitting, percebido na
região à direita do ponto A.
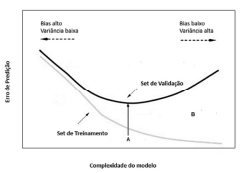
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
O Set de Treinamento é usado para qualificar o desempenho
do modelo, enquanto o Set de Validação é utilizado para
criar o modelo de aprendizado de máquina.
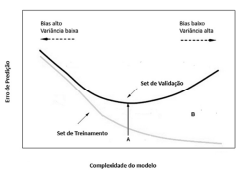
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
A região do gráfico entre as duas curvas, indicada pela letra
B, mostra a região de erro de generalização para o modelo de
aprendizado de máquina.
As métricas de avaliação de desempenho de um modelo de aprendizado de máquina, que é um componente integrante de qualquer projeto de ciência de dados, destinam-se a estimar a precisão da generalização de um modelo sobre os dados futuros (não vistos ou fora da amostra). Dentre as métricas mais conhecidas, estão a matriz de confusão, precisão, recall, pontuação, especificidade e a curva de características operacionais do receptor (ROC).
Acerca das características específicas dessas métricas, julgue o próximo item.
As curvas ROC a seguir mostram a taxa de especificidade
(verdadeiros positivos) versus a taxa de sensibilidade (falsos
positivos) do modelo adotado; a linha tracejada é a linha de
base da métrica de avaliação e define uma adivinhação
aleatória.
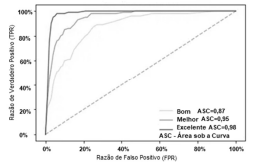
Acerca das características específicas dessas métricas, julgue o próximo item.
A matriz de confusão a seguir apresenta três rótulos de classe; os elementos diagonais representam o número de pontos para os quais o rótulo previsto é igual ao rotulo verdadeiro, enquanto qualquer coisa fora da diagonal teve um rótulo atribuído erroneamente pelo classificador. Quanto menores forem os valores diagonais da matriz de confusão, melhor o modelo adotado.
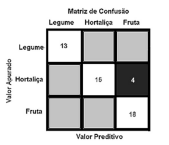
Em um processo em que se utiliza a ciência de dados, o número de variáveis necessárias para a realização da investigação de um fenômeno é direta e simplesmente igual ao número de variáveis utilizadas para mensurar as respectivas características desejadas; entretanto, é diferente o procedimento para determinar o número de variáveis explicativas, cujos dados estejam em escalas qualitativas.
Considerando esse aspecto dos modelos de regressão, julgue o item a seguir.
Para evitar um erro de ponderação arbitrária, deve-se
recorrer ao artifício de uso de variáveis dummy, o que
permitirá a estratificação da amostra da maneira que for
definido um determinado critério, evento ou atributo, para
então serem inseridas no modelo em análise; isso permitirá o
estudo da relação entre o comportamento de determinada
variável explicativa qualitativa e o fenômeno em questão,
representado pela variável dependente.
Julgue o item subsequente a respeito de conceitos, composição, transição e processo produtivo associados à matriz energética.
As fontes de energia renováveis, como a solar e a eólica,
respondem juntas por percentual inferior a 5% da matriz
energética mundial.
Julgue o item subsequente a respeito de conceitos, composição, transição e processo produtivo associados à matriz energética.
Matriz energética e matriz elétrica são conceitos similares
usados para representar o conjunto de fontes disponíveis em
um país, um estado, uma região ou no mundo, para suprir a
demanda de energia.
Julgue o item subsequente a respeito de conceitos, composição, transição e processo produtivo associados à matriz energética.
A transição energética, que envolve mudanças na geração,
no consumo e no reaproveitamento da energia,
caracteriza-se, principalmente, pela descarbonização,
descentralização e digitalização (3 Ds).
Julgue o item subsequente a respeito de conceitos, composição, transição e processo produtivo associados à matriz energética.
A matriz energética mundial tem mais de 4/5 de energia
primária gerada por fontes fósseis, ao passo que, no Brasil, o
seu mix energético gerado por fontes renováveis equivale a
2/5 da matriz energética nacional.
A respeito do uso e das fontes de energia, julgue o seguinte item.
Na área de energia, o termo onshore é empregado para
localizar as bacias sedimentares onde são explorados o
petróleo e o gás natural e refere-se ao processo produtivo
para a extração do petróleo no oceano por equipamentos
submarinos.