Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 1.266 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517674
Estatística
Um analista investiga, mediante um modelo de regressão linear
clássico, a relação entre a rentabilidade y de ofertas públicas
disponíveis no mercado e um indicador de risco associado ao
emissor, representado pela variável explicativa x. Considera-se
que o termo de erro do modelo siga distribuição Normal. Foi
utilizada uma amostra aleatória simples de 20 pares (x,y) de
observações mensais. O modelo estimado está apresentado a
seguir (erros padrão entre parênteses).
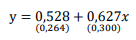
O intervalo de 95% de confiança associado ao impacto de x sobre y é (considere apenas 3 casas decimais):
O intervalo de 95% de confiança associado ao impacto de x sobre y é (considere apenas 3 casas decimais):
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517668
Estatística
Uma agência reguladora recebe, em média, uma denúncia a cada
15 minutos.
Se o número de denúncias em um período qualquer segue distribuição de Poisson, a probabilidade de que, no intervalo de 1 hora, cheguem pelo menos 2 denúncias, sabendo-se que pelo menos uma denúncia terá chegado, é de:
Se o número de denúncias em um período qualquer segue distribuição de Poisson, a probabilidade de que, no intervalo de 1 hora, cheguem pelo menos 2 denúncias, sabendo-se que pelo menos uma denúncia terá chegado, é de:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517664
Estatística
Um analista estuda discrepâncias salariais entre os seguintes
setores: manufatura, serviços financeiros e tecnologia. A figura a
seguir apresenta os box-plots dos salários desses setores, em
reais.
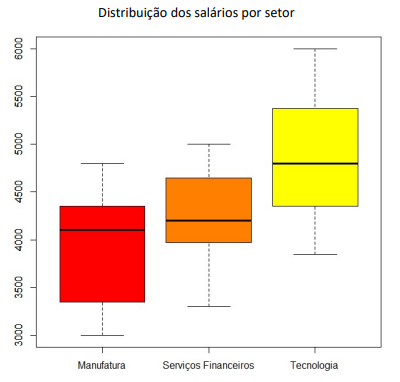
Dentre as afirmativas a seguir, a única correta é:
Dentre as afirmativas a seguir, a única correta é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517662
Banco de Dados
Observe o script SQL a seguir.

O resultado JSON da execução do script apresentado é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517661
Banco de Dados
Observe o script SQL a seguir.

Para analisar quais auditores estão realizando auditoria em quais auditados, é necessária a execução de uma consulta SQL que apresente o seguinte resultado:

Para obter o resultado apresentado, deve-se executar a consulta
SQL:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517659
Programação
Uma das principais atividades de implementação de um ambiente
analítico é a limpeza dos conjuntos de dados origem. A biblioteca
Pandas do Python é utilizada para analisar e também para limpar
conjuntos de dados. Observe o trecho de código Python a seguir,
que utiliza a biblioteca Pandas.
import pandas as pd df = pd.read_csv('data.csv') df.dropna(inplace = True)
O resultado da execução do código apresentado é a alteração do conjunto original de dados com o(a):
import pandas as pd df = pd.read_csv('data.csv') df.dropna(inplace = True)
O resultado da execução do código apresentado é a alteração do conjunto original de dados com o(a):
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517658
Banco de Dados
As demandas de dados pelos analistas e cientistas de dados da
CVM estão aumentando a cada dia. Para atendê-las com
agilidade, é necessário obter dados de diversas fontes
heterogêneas no seu formato original para posterior seleção e
processamento sob demanda.
Para armazenar dados estruturados, não estruturados e semiestruturados, deve-se implementar um(a):
Para armazenar dados estruturados, não estruturados e semiestruturados, deve-se implementar um(a):
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517657
Banco de Dados
O dado no formato JSON – padrão utilizado para armazenar e
transportar dados – deve ser de algum tipo.
O dado que representa o tipo de dado JSON Array é o:
O dado que representa o tipo de dado JSON Array é o:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517656
Banco de Dados
O ambiente analítico da CVM armazena dados no formato
multidimensional, implementa um cubo de dados e disponibiliza
uma ferramenta OLAP para apoiar os analistas no desempenho
de suas funções. Diante da grande quantidade de dados
disponíveis, eles precisam reduzir o seu domínio de análise.
Para isso, a operação OLAP, que extrai um subcubo da seleção de duas ou mais dimensões de um cubo de dados, é a:
Para isso, a operação OLAP, que extrai um subcubo da seleção de duas ou mais dimensões de um cubo de dados, é a:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517655
Banco de Dados
As transações financeiras da CVM são realizadas sobre ativos
nacionais, utilizando a moeda real (R$), e ativos internacionais,
utilizando a moeda dólar americano (US$).
Para implementar um Data Mart Financeiro da CVM, permitindo análises dos ativos nas duas moedas, deve-se:
Para implementar um Data Mart Financeiro da CVM, permitindo análises dos ativos nas duas moedas, deve-se:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517654
Banco de Dados
Para apoiar análises sobre os fundadores de empresas ao longo
do tempo, elaborou-se, inicialmente, o seguinte modelo
multidimensional de dados, no qual a tabela FATO FUNDAÇÃO
EMPRESAS se relaciona com múltiplos valores da tabela
DIMENSÃO FUNDADOR.
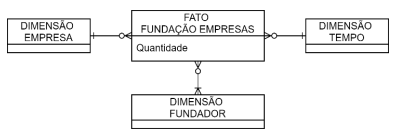
No caso apresentado, a implementação de uma dimensão multivalorada deve ser realizada por meio da aplicação da técnica de modelagem multidimensional:
No caso apresentado, a implementação de uma dimensão multivalorada deve ser realizada por meio da aplicação da técnica de modelagem multidimensional:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517653
Banco de Dados
O analista Gabriel fez um levantamento das bases de dados
existentes na CVM e percebeu que havia Data Marts distintos,
criados para atender a requisitos analíticos específicos de cada
Superintendência, como: Relações Institucionais, Auditoria e
Registro de Valores Imobiliários. Cada Data Mart foi construído
de forma independente, o que dificultava análises integradas
para relacionar dados das diferentes Superintendências. Gabriel
observou que havia várias dimensões em comum nos Data Marts.
Para permitir análises integradas padronizando e compartilhando
as dimensões em comum dos Data Marts da CVM, Gabriel
implementou um(a):
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517652
Banco de Dados
Janine é a responsável pela administração dos bancos de dados
gerenciados pelo PostgreSQL de uma autarquia federal. Durante
a criação de um banco de dados, Janine especificou a criação de
um tablespace diferente do tablespace default.
O tablespace criado por Janine:
O tablespace criado por Janine:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517651
Banco de Dados
Diante de várias reclamações de performance em resposta a
consultas a dados por meio de um dos sistemas estruturantes de
uma autarquia federal, a equipe de tecnologia identificou que o
motivo estava na lentidão para recuperação de registros na base
de dados utilizada pelo sistema. Para agilizar a recuperação de
registros em resposta a uma pesquisa que utiliza um campo que
comporta valores repetidos, a equipe de tecnologia criou índices.
Considerando que já existe um índice primário para o conjunto de dados em questão, a equipe criou um índice:
Considerando que já existe um índice primário para o conjunto de dados em questão, a equipe criou um índice:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517650
Banco de Dados
Os Sistemas Gerenciadores de Banco de Dados (SGBD) comerciais
implementam internamente técnicas para processar, otimizar e
executar consultas de alto nível.
Uma estratégia eficiente utilizada pelo otimizador de consultas do SGBD considera o uso de:
Uma estratégia eficiente utilizada pelo otimizador de consultas do SGBD considera o uso de:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517649
Banco de Dados
As transações em banco de dados possuem propriedades que
buscam proteger dados contra perdas ou danos.
A propriedade durabilidade tem relação com:
A propriedade durabilidade tem relação com:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517648
Banco de Dados
O modelo relacional representa o banco de dados como uma
coleção de relações. Considere a relação COLABORADOR
apresentada a seguir, cuja chave primária é Matricula.
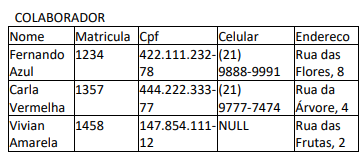
Na relação COLABORADOR, o(a):
Na relação COLABORADOR, o(a):
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517647
Banco de Dados
Observe o Modelo de Entidades e Relacionamentos a seguir.
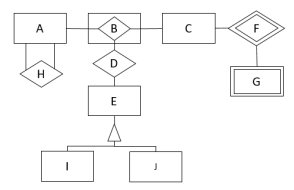
Com base nos relacionamentos apresentados, está explícito que:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517646
Banco de Dados
Documentos do Jupyter Notebook são salvos com a extensão
.ipynb, mas internamente eles são documentos do tipo:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517645
Programação
Igor, analista de dados da CVM, escreveu e rodou o código a
seguir.
from nltk.corpus import stopwords from nltk.tokenize import word_tokenize
texto = "Eu sou um analista de dados da CVM!"
stop_words = set(stopwords.words('portuguese')) tokens = word_tokenize(texto)
tokens_processados = [w for w in tokens if not w in stop_words]
print(tokens_processados)
Considerando que o código foi executado sem erros e sabendo que Igor está usando Python 3.10.12 e NLTK 3.8.1, a saída do terminal foi:
from nltk.corpus import stopwords from nltk.tokenize import word_tokenize
texto = "Eu sou um analista de dados da CVM!"
stop_words = set(stopwords.words('portuguese')) tokens = word_tokenize(texto)
tokens_processados = [w for w in tokens if not w in stop_words]
print(tokens_processados)
Considerando que o código foi executado sem erros e sabendo que Igor está usando Python 3.10.12 e NLTK 3.8.1, a saída do terminal foi: