Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 3.250 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Engenharia Telecomunicação |
Q2607676
Engenharia de Telecomunicações
As antenas desempenham um papel essencial nos sistemas de
telecomunicações, sendo responsáveis pela emissão e recepção
de sinais eletromagnéticos. Para descrever seu desempenho, são
considerados diversos parâmetros e características, como ganho,
diretividade, largura de feixe, polarização, impedância e VSWR.
Neste contexto, analise as seguintes afirmações sobre antenas:
I. Uma antena isotrópica é aquela que transmite em todas as direções com a mesma potência.
II. VSWR é uma medida da eficiência de transmissão da antena. Um VSWR baixo indica que a maior parte da energia do sinal é transmitida, enquanto um VSWR alto indica refletância, resultando em perdas de energia.
III. A diretividade refere-se à habilidade da antena de concentrar energia em uma direção específica. É relacionada ao ganho, mas considera também o padrão de radiação da antena.
Está correto o que se afirma em:
I. Uma antena isotrópica é aquela que transmite em todas as direções com a mesma potência.
II. VSWR é uma medida da eficiência de transmissão da antena. Um VSWR baixo indica que a maior parte da energia do sinal é transmitida, enquanto um VSWR alto indica refletância, resultando em perdas de energia.
III. A diretividade refere-se à habilidade da antena de concentrar energia em uma direção específica. É relacionada ao ganho, mas considera também o padrão de radiação da antena.
Está correto o que se afirma em:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Engenharia Telecomunicação |
Q2607674
Engenharia de Telecomunicações
No contexto das comunicações sem fio, é fundamental assegurar
que o sinal transmitido seja adequadamente recebido,
especialmente quando se utilizam antenas direcionais.
Considere um enlace de comunicações operando na frequência
central de 1 GHz, com antenas direcionais apresentando um
ganho de 6 dBi cada uma e separadas por uma distância de 100
metros. A potência mínima requerida no receptor é de -30 dBm.
Sabe-se que a equação da atenuação no espaço livre é dada por:
AEL = 92,40 + 20. log10(F) + 20. log10(D) (dB)
em que: F = Frequência em GHz. D = Distância em km.
A potência mínima do transmissor em dBm para garantir que a especificação no receptor seja atendida é de
AEL = 92,40 + 20. log10(F) + 20. log10(D) (dB)
em que: F = Frequência em GHz. D = Distância em km.
A potência mínima do transmissor em dBm para garantir que a especificação no receptor seja atendida é de
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Engenharia Telecomunicação |
Q2607671
Estatística
Seja c uma amostra de uma variável aleatória gaussiana de média
0 e variância 1. A tabela abaixo mostra a probabilidade de c ser
menor que alguns valores V entre 0,0 e 2,1.
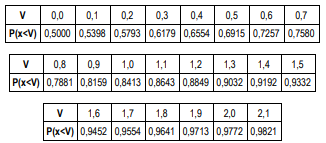
Se somarmos 9 amostras independentes da mesma variável aleatória de x, o valor mais próximo da probabilidade dessa soma ser maior que 1,8, entre as opções apresentadas a seguir, é:
Se somarmos 9 amostras independentes da mesma variável aleatória de x, o valor mais próximo da probabilidade dessa soma ser maior que 1,8, entre as opções apresentadas a seguir, é:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Engenharia Telecomunicação |
Q2607670
Matemática
A relação entre dois parâmetros B e T pode ser representada por
uma reta no gráfico do tipo log-log, como mostra a figura abaixo.
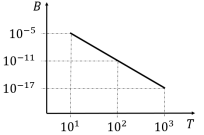
A expressão matemática que melhor representa essa relação é:
A expressão matemática que melhor representa essa relação é:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Engenharia Telecomunicação |
Q2607669
Física
ATENÇÃO: O enunciado a seguir refere-se à próxima questão
Uma partícula realiza um movimento circular uniforme (MCU) no plano xy. Considere que a posição da partícula pode ser descrita por x = 3 cos(3t) e y = −3 cos(3t − π/2), em que t é o tempo em segundos.
O movimento da partícula, em coordenadas polares (r, θ) pode ser descrito como:
Uma partícula realiza um movimento circular uniforme (MCU) no plano xy. Considere que a posição da partícula pode ser descrita por x = 3 cos(3t) e y = −3 cos(3t − π/2), em que t é o tempo em segundos.
O movimento da partícula, em coordenadas polares (r, θ) pode ser descrito como:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Engenharia Telecomunicação |
Q2607668
Física
ATENÇÃO: O enunciado a seguir refere-se à próxima questão
Uma partícula realiza um movimento circular uniforme (MCU) noplano xy. Considere que a posição da partícula pode ser descritapor x = 3 cos(3t) e y = −3 cos(3t − π/2), em que t é o tempoem segundos.
O período do MCU realizado pela partícula, em segundos, é iguala
Uma partícula realiza um movimento circular uniforme (MCU) noplano xy. Considere que a posição da partícula pode ser descritapor x = 3 cos(3t) e y = −3 cos(3t − π/2), em que t é o tempoem segundos.
O período do MCU realizado pela partícula, em segundos, é iguala
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571762
Banco de Dados
Com relação aos conceitos de dado, informação e conhecimento,
avalie as afirmativas a seguir.
I. Os dados são itens elementares, são cadeias de símbolos e não possuem significado. II. São exemplos de conhecimento: tendência de vendas de um produto A em uma região B; relação entre o aumento ou queda do preço de uma ação X, na bolsa de valores, e a variação do câmbio. III. As informações correspondem ao dado processado, com significado e um contexto indefinido.
Está correto o que se afirma em
I. Os dados são itens elementares, são cadeias de símbolos e não possuem significado. II. São exemplos de conhecimento: tendência de vendas de um produto A em uma região B; relação entre o aumento ou queda do preço de uma ação X, na bolsa de valores, e a variação do câmbio. III. As informações correspondem ao dado processado, com significado e um contexto indefinido.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571755
Programação
Considerando os parâmetros (flags) usados na linha de comando
ao executar o framework pytest, aquele utilizado para iniciar o
debugger interativo do Python é
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571754
Programação
Com relação ao framework pytest, da linguagem de programação
Python, avalie as afirmativas a seguir:
I. O comando pytest executa os arquivos no formato test_*.py ou *_test.py no diretório corrente e nos subdiretórios. II. O comando abaixo mostra os 5 testes com maior tempo de duração. >>> pytest -vv --durations=5 III. É possível invocar o framework pytest usando o próprio interpretador do Python por meio do comando abaixo: >>> python -m pytest
Está correto o que se afirma em
I. O comando pytest executa os arquivos no formato test_*.py ou *_test.py no diretório corrente e nos subdiretórios. II. O comando abaixo mostra os 5 testes com maior tempo de duração. >>> pytest -vv --durations=5 III. É possível invocar o framework pytest usando o próprio interpretador do Python por meio do comando abaixo: >>> python -m pytest
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571752
Engenharia de Software
Alguns dos primeiros modelos de linguagem de larga escala
desenvolvidos tendiam a gerar resultados incorretos com excesso
de confiança, caracterizando o que se convencionou chamar de
alucinações dos modelos. Uma estratégia de mitigação das
alucinações é o uso da técnica de Geração Aumentada por
Recuperação, ou Retrieval-Augmented Generation (RAG).
A respeito da RAG, avalie as afirmativas a seguir.
I. Baseia-se na combinação de sistemas de recuperação de informações e de modelos generativos capazes de produzir novos textos. II. Permite aos modelos buscarem informações relevantes em bases de dados mais confiáveis durante o processamento das consultas dos usuários (user queries), viabilizando melhor adequação a contextos e melhor qualidade das respostas. III. Não altera os parâmetros dos modelos generativos, e, portanto, não influencia o treinamento das redes neurais com informações recuperadas de bases de dados externas.
Está correto o que se afirma em
A respeito da RAG, avalie as afirmativas a seguir.
I. Baseia-se na combinação de sistemas de recuperação de informações e de modelos generativos capazes de produzir novos textos. II. Permite aos modelos buscarem informações relevantes em bases de dados mais confiáveis durante o processamento das consultas dos usuários (user queries), viabilizando melhor adequação a contextos e melhor qualidade das respostas. III. Não altera os parâmetros dos modelos generativos, e, portanto, não influencia o treinamento das redes neurais com informações recuperadas de bases de dados externas.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571751
Programação
As arquiteturas de modelos de linguagem de larga escala (Large
Language Models - LLM) surgiram recentemente, revolucionando
a área de inteligência artificial nas áreas de processamento e
geração de texto.
A arquitetura desses modelos baseia-se, majoritariamente, nas redes neurais do tipo transformers. Relacione as arquiteturas a seguir com suas características principais:
1. BERT 2. GPT 3. T5
( ) Utiliza decoders das redes transformer para prever novos tokens a partir de uma sequência, tornando-se ideal para a geração de textos. ( ) Utiliza encoders das redes transformer para "entender" o contexto de frases, tornando-se ideal para classificação de textos. ( ) Utiliza encoders e decoders das redes transformer, sendo adaptável a situações em que seja necessário gerar novos textos ou processar textos para "entender" o contexto das frases. ( ) Em comparação com as outras arquiteturas, tem menor necessidade de fine-tuning para melhora de performance.
A relação correta, na ordem apresentada, é
A arquitetura desses modelos baseia-se, majoritariamente, nas redes neurais do tipo transformers. Relacione as arquiteturas a seguir com suas características principais:
1. BERT 2. GPT 3. T5
( ) Utiliza decoders das redes transformer para prever novos tokens a partir de uma sequência, tornando-se ideal para a geração de textos. ( ) Utiliza encoders das redes transformer para "entender" o contexto de frases, tornando-se ideal para classificação de textos. ( ) Utiliza encoders e decoders das redes transformer, sendo adaptável a situações em que seja necessário gerar novos textos ou processar textos para "entender" o contexto das frases. ( ) Em comparação com as outras arquiteturas, tem menor necessidade de fine-tuning para melhora de performance.
A relação correta, na ordem apresentada, é
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571750
Engenharia de Software
As redes neurais artificiais (Artificial Neural Networks - ANN)
constituem um grupo de algoritmos inspirados nas funções dos
neurônios no cérebro humano. Diversas arquiteturas de redes
neurais são utilizadas para diferentes problemas, conforme suas
funcionalidades.
Existe uma arquitetura de rede neural específica, especialmente apropriada ao reconhecimento de padrões de imagens e vídeos, por possuir as seguintes propriedades:
• As informações fluem apenas em uma direção. • As informações são propagadas em diferentes camadas neurais que filtram características (isto é, as features). • As informações são propagadas em diferentes camadas que reduzem sua dimensionalidade.
Das opções a seguir, as redes que mais aderem às propriedades listadas acima são as redes
Existe uma arquitetura de rede neural específica, especialmente apropriada ao reconhecimento de padrões de imagens e vídeos, por possuir as seguintes propriedades:
• As informações fluem apenas em uma direção. • As informações são propagadas em diferentes camadas neurais que filtram características (isto é, as features). • As informações são propagadas em diferentes camadas que reduzem sua dimensionalidade.
Das opções a seguir, as redes que mais aderem às propriedades listadas acima são as redes
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571748
Engenharia de Software
A análise de componentes principais (Principal Component
Analysis - PCA) é uma técnica de redução de dimensionalidade de
dados utilizada em diversas aplicações, tais como em compressão
de imagens e em processamento de linguagem natural.
Em relação à análise de componentes principais, avalie se as afirmativas a seguir são verdadeiras (V) ou falsas.
( ) Permite a identificação de correlações e de estruturas de menor dimensionalidade na distribuição espacial dos dados, caracterizadas pelas direções onde há maior variância. ( ) Envolve o cálculo de autovalores e autovetores de matrizes de covariâncias, determinando-se as componentes principais das distribuições de dados. ( ) É adequada para identificar correlações não-lineares entre os dados de um conjunto de alta dimensionalidade, projetando estruturas em espaços vetoriais de menores dimensões.
As afirmativas são, respectivamente,
Em relação à análise de componentes principais, avalie se as afirmativas a seguir são verdadeiras (V) ou falsas.
( ) Permite a identificação de correlações e de estruturas de menor dimensionalidade na distribuição espacial dos dados, caracterizadas pelas direções onde há maior variância. ( ) Envolve o cálculo de autovalores e autovetores de matrizes de covariâncias, determinando-se as componentes principais das distribuições de dados. ( ) É adequada para identificar correlações não-lineares entre os dados de um conjunto de alta dimensionalidade, projetando estruturas em espaços vetoriais de menores dimensões.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571747
Engenharia de Software
Alguns algoritmos de aprendizado de máquina servem para
agrupar instâncias de dados em clusters, podendo ser utilizados
para tarefas como segmentação de imagens, ou segmentação
social (por exemplo, para agrupamento de clientes em uma
mesma categoria.
Dois dos mais populares algoritmos são o K-means e o DBSCAN. A respeito desses algoritmos, relacione-os com suas principais características:
1. K-means 2. DBSCAN
( ) Precisa da definição de um número inicial de agrupamentos. ( ) Mais robusto à ocorrência de outliers, por sua provável localização em regiões de baixa densidade de dados. ( ) Precisa da definição do número mínimo de vizinhos e do raio da vizinhança para determinar limites dos agrupamentos. ( ) Determina centróides dos agrupamentos e agrupa as instâncias de dados em função de uma métrica de distância entre as instâncias e os centróides.
Assinale a opção que indica a relação correta, na sequência apresentada.
Dois dos mais populares algoritmos são o K-means e o DBSCAN. A respeito desses algoritmos, relacione-os com suas principais características:
1. K-means 2. DBSCAN
( ) Precisa da definição de um número inicial de agrupamentos. ( ) Mais robusto à ocorrência de outliers, por sua provável localização em regiões de baixa densidade de dados. ( ) Precisa da definição do número mínimo de vizinhos e do raio da vizinhança para determinar limites dos agrupamentos. ( ) Determina centróides dos agrupamentos e agrupa as instâncias de dados em função de uma métrica de distância entre as instâncias e os centróides.
Assinale a opção que indica a relação correta, na sequência apresentada.
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571744
Engenharia de Software
Modelos de aprendizagem de máquina são, em geral, avaliados
com métricas que indicam os quão poderosos e relevantes eles
são. Entre exemplos de métricas de avaliação utilizadas para
modelos de classificação binária, podemos citar:
• Taxa de precisão (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos positivos); • Taxa de sensibilidade (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos negativos, também conhecida por recall); e • Escore F1 (F1-score, também chamado de F-measure), que relaciona as taxas de precisão e de sensibilidade. Suponha a existência de um modelo de classificação binária cuja taxa de precisão é de 90,00% e cuja taxa de sensibilidade é de 75,00%. Utilize aproximação de duas casas decimais.
O escore F1 referente a esse modelo é
• Taxa de precisão (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos positivos); • Taxa de sensibilidade (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos negativos, também conhecida por recall); e • Escore F1 (F1-score, também chamado de F-measure), que relaciona as taxas de precisão e de sensibilidade. Suponha a existência de um modelo de classificação binária cuja taxa de precisão é de 90,00% e cuja taxa de sensibilidade é de 75,00%. Utilize aproximação de duas casas decimais.
O escore F1 referente a esse modelo é
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571742
Banco de Dados
Associe os conceitos a seguir às respectivas características.
1. Data Lake 2. Data Mart
( ) Surgiu como uma alternativa aos armazéns de dados tradicionais, permitindo o armazenamento de grandes volumes de dados de qualquer tipo e tamanho. ( ) São criados para tornar os dados mais facilmente acessíveis para geração de relatórios, além de fornecer um estágio adicional de transformação além das tubulações ETL iniciais. ( ) Tipo de armazenamento de dados frequentemente usado para suportar camadas de apresentação do ambiente de data warehouse. ( ) Fornece um local central de armazenamento para dados brutos, com o mínimo de transformação, se houver.
A associação correta, na ordem dada, é:
1. Data Lake 2. Data Mart
( ) Surgiu como uma alternativa aos armazéns de dados tradicionais, permitindo o armazenamento de grandes volumes de dados de qualquer tipo e tamanho. ( ) São criados para tornar os dados mais facilmente acessíveis para geração de relatórios, além de fornecer um estágio adicional de transformação além das tubulações ETL iniciais. ( ) Tipo de armazenamento de dados frequentemente usado para suportar camadas de apresentação do ambiente de data warehouse. ( ) Fornece um local central de armazenamento para dados brutos, com o mínimo de transformação, se houver.
A associação correta, na ordem dada, é:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571741
Banco de Dados
O conceito de Big Data engloba não apenas o volume de dados,
mas também a variedade e a velocidade com que são produzidos
os chamados 3Vs, os principais desafios ou dimensões do Big
Data.
Posteriormente, de acordo com o DAMA-DBOK, aos 3Vs iniciais foram adicionados outros 3Vs aos principais desafios ou dimensões do Big Data. São eles:
Posteriormente, de acordo com o DAMA-DBOK, aos 3Vs iniciais foram adicionados outros 3Vs aos principais desafios ou dimensões do Big Data. São eles:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571740
Banco de Dados
Analise o trecho a seguir:
É um padrão de transformação de dados em lote que foi introduzido como uma alternativa para lidar com grandes volumes de dados. Consiste em tarefas de mapa que leem blocos de dados individuais espalhados pelos nós, seguidas por uma etapa de shuffle que redistribui os dados de resultado e uma etapa de redução que agrega os dados em cada nó. Seu paradigma foi construído em torno da ideia de que a capacidade e largura de banda do disco magnético eram tão baratas que fazia sentido simplesmente usar uma enorme quantidade de disco para realizar consultas ultrarrápidas.
A tecnologia em questão é:
É um padrão de transformação de dados em lote que foi introduzido como uma alternativa para lidar com grandes volumes de dados. Consiste em tarefas de mapa que leem blocos de dados individuais espalhados pelos nós, seguidas por uma etapa de shuffle que redistribui os dados de resultado e uma etapa de redução que agrega os dados em cada nó. Seu paradigma foi construído em torno da ideia de que a capacidade e largura de banda do disco magnético eram tão baratas que fazia sentido simplesmente usar uma enorme quantidade de disco para realizar consultas ultrarrápidas.
A tecnologia em questão é:
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571739
Banco de Dados
Sobre o processo de ingestão de dados, avalie se as afirmativas a
seguir são verdadeiras (V) ou falsas (F).
( ) Dados não estruturados podem incluir arquivos de texto, logs e outras formas de informação não padronizada. ( ) A ingestão de dados em lote pode ser iniciada mediante agendamento ou quando os dados atingem um limite de tamanho predeterminado. ( ) Apesar de ser mais simples de implementar, a ingestão de dados incremental ou diferencial é ideal para minimizar o tráfego na rede e o uso do storage. ( ) É mais comum adicionar etapas adicionais de transformação e limpeza dos dados em dados estruturados do que em não estruturados.
As afirmativas são, respetivamente,
( ) Dados não estruturados podem incluir arquivos de texto, logs e outras formas de informação não padronizada. ( ) A ingestão de dados em lote pode ser iniciada mediante agendamento ou quando os dados atingem um limite de tamanho predeterminado. ( ) Apesar de ser mais simples de implementar, a ingestão de dados incremental ou diferencial é ideal para minimizar o tráfego na rede e o uso do storage. ( ) É mais comum adicionar etapas adicionais de transformação e limpeza dos dados em dados estruturados do que em não estruturados.
As afirmativas são, respetivamente,
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571738
Governança de TI
O crescimento na quantidade e complexidade dos dados
disponíveis para as empresas torna imprescindível que a
Governança de Dados seja estruturada com documentos que
circulem em vários níveis da empresa de acordo com as suas
respectivas finalidades, contribuindo para colimar os esforços de
todos os membros para obter os resultados esperados.
Com relação aos documentos da Governança de Dados, avalie as afirmativas a seguir.
I. As políticas de dados são regras pormenorizadas do que pode ser feito e o que não pode ser feito, devendo ser conhecidas por todos os profissionais da empresa. II. As normas são documentos que indicam as práticas recomendadas, mas não obrigatórias, que devem ser adotadas pelas pessoas que trabalham com os dados. III. Os procedimentos têm por finalidade orientar as pessoas na execução de tarefas específicas visando atingir determinado objetivo, ou seja, documentos que indicam o “como fazer” determinada tarefa.
Está correto o que se afirma em
Com relação aos documentos da Governança de Dados, avalie as afirmativas a seguir.
I. As políticas de dados são regras pormenorizadas do que pode ser feito e o que não pode ser feito, devendo ser conhecidas por todos os profissionais da empresa. II. As normas são documentos que indicam as práticas recomendadas, mas não obrigatórias, que devem ser adotadas pelas pessoas que trabalham com os dados. III. Os procedimentos têm por finalidade orientar as pessoas na execução de tarefas específicas visando atingir determinado objetivo, ou seja, documentos que indicam o “como fazer” determinada tarefa.
Está correto o que se afirma em