Foram encontradas 12.662 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Julgue o item a seguir.
A média aritmética ponderada de um conjunto de dados
sempre será maior do que a média aritmética simples se
os pesos atribuídos aos valores maiores forem
superiores aos pesos dos valores menores. Por exemplo,
considere os valores 2, 4, e 6, com pesos 1, 2, e 3,
respectivamente. A média aritmética simples é 4
(calculada como (2 + 4 + 6) / 3), enquanto a média
ponderada é 4.67 (calculada como (12 + 24 + 3*6) / (1 + 2
+ 3)), que é maior.
Ao se considerar um modelo linear de dados transformados para encontrar as constantes α e β do modelo de regressão não-linear y = αeβx que melhor se ajusta aos dados (x1, y1),...,(xn, yn), a soma dos quadrados dos resíduos que deve ser minimizada é dada por:
A respeito de um modelo de regressão logística para uma variável resposta Y considerando a função de ligação canônica
associada ao modelo Bernoulli, chamada de logit, é INCORRETO afirmar que:
Seja X uma variável aleatória normalmente distribuída com média μ desconhecida e desvio-padrão σ = 6. Considere um teste da hipótese nula H0: μ = 40 contra a hipótese alternativa de que H1: μ > 40 ao nível de significância α e com base em uma amostra de tamanho n. Com relação ao nível de significância e ao poder desse teste de hipóteses, é INCORRETO afirmar que:
Os dados a seguir representam uma população de 140 indivíduos dividida em cinco conglomerados.
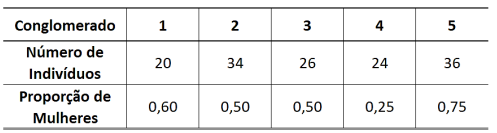
Considere um estudo baseado em uma amostra aleatória simples sem reposição de dois conglomerados desta população.
Com base nesses dados, assinale a afirmativa correta.
Considere que o tempo médio para processar o arquivamento de um processo tem sido de 9,27 segundos em um certo computador. Após uma atualização no seu sistema operacional, coletou-se uma amostra do tempo gasto no arquivamento de dezesseis processos. Com o objetivo de estimar o tempo médio populacional de arquivamento de um processo sob o novo sistema operacional, construiu-se o seguinte intervalo de 90% de confiança baseado na distribuição t-Student: (8,88; 9,18). Com base nos dados fornecidos é INCORRETO afirmar que:
Dados adicionais: P(T15 < 1,34) = 0,90; P(T15 < 1,75) = 0,95; P(T15 < 2,13) = 0,975; P(T15 < 2,95) = 0,995; onde TK denota uma variável aleatória com distribuição t-Student com K graus de liberdade.
Um modelo histórico especifica que as denúncias recebidas por certo Tribunal de Justiça devem ser classificadas em apenas uma de três categorias (A, B e C) com as probabilidades PA = 0,50, PB = 0,40 e PC = 0,10, respectivamente. Dentre 180 denúncias recebidas em determinada semana, obteve-se as seguintes frequências observadas para as três categorias, respectivamente: 0A = 81, 0B = 66 e 0C = 33. Ao se aplicar um teste qui-quadrado de aderência desses dados ao modelo histórico postulado, supondo válidas todas as condições necessárias, é correto afirmar que:
Um estudo foi realizado para comparar o tempo (em minutos) de execução de uma tarefa entre três grupos independentes
de funcionários recém-contratados treinados com métodos distintos. Os dados obtidos são apresentados a seguir.
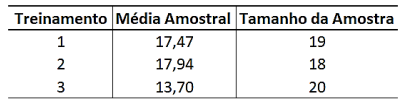
Considerando que os dados são normalmente distribuídos nos três grupos, realizou-se uma análise de variância para verificar se existe diferença significativa entre o tempo médio de realização da tarefa sob os três tipos de treinamento na população de funcionários. A soma de quadrados entre os grupos foi igual a 210 e a soma de quadrados total foi igual a 345. Se Fx,y denota uma variável aleatória com distribuição F de Fisher com x graus de liberdade no numerador e y graus de liberdade no denominador, o p-valor do teste de hipóteses associado é dado por:
Determinado Ministério Público Estadual coletou dados nas 53 comarcas do Estado com o intuito de estudar a relação entre
o tempo médio (Y), em dias, gasto na triagem inicial de denúncias de abuso recebidas pela comarca e duas variáveis
explicativas: o número de servidores lotados no setor responsável por avaliar as denúncias na comarca (X1); e o número de
municípios atendidos pela comarca (X2). Considere o ajuste do modelo de regressão linear múltipla Yi = β0 + β1X1i + β2X2i + ɛi , onde i = 1,..., 53 e ɛ1,..., ɛ53 são erros independentes com ɛi⁓N(0, σ2) para todo i. Os seguintes resultados
foram obtidos pelo método de máxima verossimilhança: 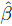 0 = 21, 5, 1 = – 2,8 e 2 = 3,5. Adicionalmente, tem-se que SQRegressão = 346,5 e SQResíduos = 185, 5. Com base nessas informações, é correto afirmar que:
0 = 21, 5, 1 = – 2,8 e 2 = 3,5. Adicionalmente, tem-se que SQRegressão = 346,5 e SQResíduos = 185, 5. Com base nessas informações, é correto afirmar que:
Para obter o controle de qualidade dos produtos da sua empresa, a administradora Raquele sempre observa uma certa
variável X em cada produto. Após uma nova diretriz emitida por determinada agência regulamentadora, a variável que deve
ser observada em cada produto Y = 3/2 X + 2. Considere que µ e σ2 são, respectivamente, a média e variância da variável X.
De acordo com o exposto, quais são, respectivamente, os valores da média e variância da variável Y?
Considere que a variável aleatória Z apresenta a seguinte função densidade de probabilidade:
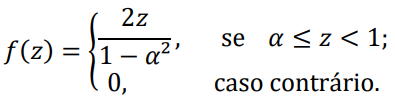
Uma amostra aleatória de 8 valores da variável Z resultou nas seguintes observações: 0,35; 0,24; 0,48; 0,54; 0,36; 0,28; 0,21; e, 0,66. De acordo com os resultados obtidos por essa amostra, qual a estimativa para
Após a condução de um procedimento de amostragem probabilístico, Luciana coletou uma amostra aleatória de 100 processos na instituição em que trabalha. Ela verificou que o tempo médio para o julgamento desses processos é de 20 dias. Adicionalmente, Luciana obteve um valor de 10 dias para o desvio-padrão do tempo de julgamento dos processos. Considerando essas informações, o intervalo de confiança para a média do tempo de julgamento dos processos na instituição, com 96% de confiança é:


Roberta trabalha no setor de processos de uma repartição pública e possui uma planilha com os dados de todas as pessoas que foram denunciadas no seu setor. As quatro primeiras variáveis dessa planilha são:
Variável 1: Número do Cadastro de Pessoa Física (CPF).
Variável 2: Idade, em anos completos.
Variável 3: Município de residência.
Variável 4: Escolaridade (ensino fundamental, ensino médio ou ensino superior).
De acordo com a natureza dessas variáveis, quantas delas são classificadas como qualitativas?
A análise descritiva e exploratória dos dados é recomendada em qualquer estudo amostral. Tal análise é fundamental para a identificação de padrões e orientar como a estatística inferencial deve ser conduzida para a população. Nesse contexto, analise as seguintes afirmativas.
I. Em uma pesquisa, qualquer amostra coletada pode representar, de forma adequada, a população de interesse.
II. O desvio-padrão amostral de uma variável quantitativa é sempre menor que a sua variância amostral.
III. Se a distribuição de uma variável da amostra é unimodal e apresenta assimetria à esquerda, então a média amostral < mediana amostral < moda amostral.
Está correto o que se afirma em