Questões de Concurso
Foram encontradas 49 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
De acordo com o Decreto nº 2.553, de abril de 1998, art. 1º, § 1º, o caráter sigiloso do pedido de patente, cujo objeto seja de natureza militar, será decidido com base em parecer _________________ emitido pelo Estado-Maior das Forças Armadas, podendo o exame técnico ser delegado aos Ministérios Militares.
O termo que completa corretamente a lacuna da afirmativa é
Considere a figura abaixo de uma janela de manipulação de arquivos e pastas do Microsoft Windows 7, versão português:
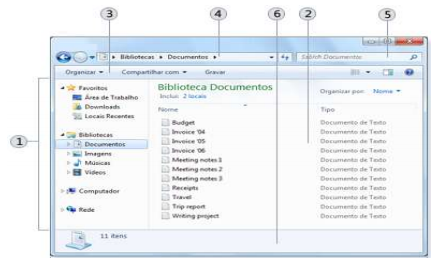
Em relação às partes de uma janela, identificadas por números de 1 a 6, correlacione as colunas a seguir, numerando os parênteses.
Número Parte da Janela
1 ( ) Barra de ferramentas
2 ( ) Caixa de pesquisa
3 ( ) Painel de detalhes
4 ( ) Lista de arquivos
5 ( ) Barra de endereços
6 ( ) Painel de navegação
A sequência CORRETA, de cima para baixo, é:
Internet, julgue os itens subsecutivos.