Questões de Concurso
Foram encontradas 13.789 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
I. Para garantir a confiabilidade dos dados, o desenvolvedor de bancos de dados em laboratórios deve utilizar exclusivamente dados ofline.
II. Deve ser estabelecido um procedimento para backup regular.
III. Os dados brutos de ensaios e calibrações devem ser armazenados em servidores públicos.
Sobre as afirmativas acima, pode-se dizer que:
Analise o trecho de código a seguir em Linguagem SQL e responda a questão.
inserir nos valores do projeto (1, "ABC", "Belo Horizonte"),
(2, "ABE", "Rio de Janeiro"),
(3, "ABF", "São Paulo"),
(4, "ABG", "Curitiba"),
(5, "ABH", "Juiz de Fora");
inserir nos valores do departamento (100, "Marketing", "MK"),
(101, "Vendas", "VD"),
(102, "Tecnologia da Informação", "TI"),
(103, "Recursos Humanos", "RH"),
(104, "Contabilidade", "CT"),
(105, "Estoque", "ES");
inserir nos valores de funcionamentoio (1, "Alice", '2011-11-01', "[email protected]", 1, 100),
(2, "Mohamed", '2015-09-06', "[email protected]",1, 101),
(3, "Bob", '2018-05-02', "[email protected]", 3.103),
(4, "Maria", '2017-10-07', "[email protected]", 4, 104),
(5, "João", '01-04-2012', "[email protected]", 1, 101);
SELECIONE f.* DE função f ESQUERDA JUNTE projeto p
ON f.cod_proj = p.cod onde f.cod_proj não é nulo;
SELECIONE f.* DE funcionario f DIREITA JUNTE-SE departamento
d ON f.cod_dep = d.id onde f.cod_dep não é nulo;
Ao executar, de forma independente, cada código SQL retornará uma certa quantidade de linhas. Marque uma alternativa CORRETA.
Considere o esquema de tabelas para responder à questão

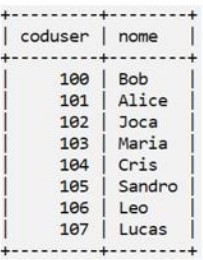
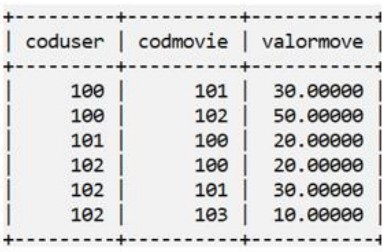
SELECT u.coduser, COUNT(u.coduser) AS TOTAL
FROM user u
LEFT JOIN user_movie cm
ON u.coduser = cm.coduser
RIGHT JOIN movie m
ON m.codmovie = u.coduser
GROUP BY u.nome
ORDER BY 1 Desc ;
Um usuário de banco de dados executa a consulta acima e os valores contidos na coluna TOTAL que serão exibidos ao final da execução do código são:
Considere o seguinte código Python que implementa parte de um ETL sobre a tabela Financiamento.
import pandas as pd from sqlalchemy import create_engine from datetime import datetime
engine = create_engine(“postgresql:// postgres:postgres@localhost:5432/bd_pesquisa”) query = “SELECT * FROM Financiamento” df = pd.read_sql_query(con=engine.connect(), sql=sql_text(query)) df[‘data_inicio’] = pd.to_datetime(df[‘data_ inicio’]).dt.strftime(‘%d/%m/%Y’) df[‘data_fim’] = pd.to_datetime(df[‘data_ fim’]).dt.strftime(‘%d/%m/%Y’) df.to_csv(‘financiamentos_transformados.csv’, index=False)
Observe as afirmativas a seguir sobre a execução do código.
I. O código se conecta a um banco de dados PostgreSQL usando a biblioteca SQLAlchemy e extrai todos os dados da tabela Financiamento.
II. As colunas data_inicio e data_fim são transformadas para o formato DD/MM/AAAA, mas esses dados não são atualizados no banco de dados.
III. O dataframe resultante da transformação é salvo em um arquivo CSV chamado financiamentos_transformados.csv na máquina local, incluindo o índice do datadrame como uma coluna adicional.
Sobre as afirmativas acima, pode-se dizer que:
Seja o diagrama ER apresentado abaixo, desenhado na notação crow’s foot, para um sistema de gestão de pesquisa.
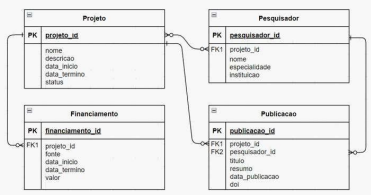
Entre as opções abaixo, a que apresenta corretamente uma consulta SQL para retornar o valor total de financiamento de um projeto chamado “Inovação em Saúde” é:
I. Seu objetivo é extrair conjuntos de itens frequentes de um banco de dados.
II. Um exemplo de padrão frequente são as regras de associação.
III. Dado um conjunto de itens X = {x1, x2,…,xm} e um conjunto de transações T = {t1, t2, …, tn}, um subconjunto de X, S, é chamado de conjunto de itens frequentes se S ocorre em uma porcentagem de todas as transações em T que excede um limite, denominado suporte.
IV. O suporte de um conjunto de itens Y, suporte(Y), é definido como o número de transações em T que contêm o conjunto de itens Y.
Das afirmativas acima, é correto afirmar que:
I. Não precisam ser entre duas entidades distintas, sendo possível a presença de um relacionamento entre apenas uma entidade.
II. Os relacionamentos podem ter atributos.
III. São representados por elipses no modelo entidade-relacionamento.
IV. A cardinalidade especifica o número mínimo e o máximo de instâncias que uma entidade pode participar.

O esquema de banco de dados representado acima contém, respectivamente, ______entidades e________relacionamentos.
A opção que preenche as lacunas da frase acima é: