Questões de Concurso
Foram encontradas 13.789 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Processo (Código, Título, Local, Ano)
O comando SQL para excluir os processos cujo título possua a sequência ‘dados’, relativos ao período de 2020 a 2024, é:
Esse programa é o
Dessa forma, sobre a normalização das tabelas, é correto afirmar que um dos objetivos principais dessa tarefa é
Com relação ao SQL do PostgreSQL, analise as afirmativas a seguir.
I. A cláusula GROUP BY agrupa linhas com os mesmos valores em linhas de resumo, sendo frequentemente usada com funções de agregação como, por exemplo, COUNT( ), MAX( ), MIN( ), SUM( ) e AVG( ), para agrupar um conjunto de resultados de uma ou mais colunas.
II. O operador HAVING foi adicionado ao SQL porque o WHERE não pode ser usado com funções de agregação, as quais são frequentemente usadas com a cláusula GROUP BY. Ao adicionar o HAVING é possível escrever condições similares às das cláusulas WHERE.
III. A expressão CASE testa condições e retorna um valor quando a primeira condição é atendida (como uma instrução if-thenelse); quando a condição seja verdadeira, ele parará a leitura e retornará o resultado, mas, se nenhuma condição for verdadeira, ele retornará o valor da cláusula ELSE. Caso não houver nenhum ELSE e nenhuma condição for verdadeira, ele retornará o valor NULL.
Está correto o que se afirma em
Com relação aos índices desse SGBD, analise as afirmativas a seguir.
I. Índices podem ser exclusivos ou não exclusivos. Índices exclusivos garantem que nenhuma das duas linhas de uma tabela tenha valores duplicados na coluna ou mais colunaschave. Já Índices não exclusivos permitem valores duplicados na coluna ou nas colunas indexadas.
II. Índices de árvores B são o tipo de índice padrão do Oracle. Esse tipo possui diversos subtipos, por exemplo, índices de chave inversa, índices descendentes e índices de junção de clusteres de tabelas.
III. Existem índices que não usam estruturas de árvore B, por exemplo, índices de junção de bitmap e bitmap, índices baseados em funções e índices de domínio de aplicação.
Está correto o que se afirma em
Com relação aos modos de conexão do H2, analise as afirmativas a seguir.
I. No modo incorporado (embedded), um aplicativo abre um banco de dados dentro da mesma máquina virtual Java (JVM) usando JDBC. Este é o modo de conexão mais rápido e fácil. A desvantagem é que um banco de dados só pode ser aberto em uma máquina virtual por vez. Não há limite para o número de bancos de dados abertos simultaneamente ou para o número de conexões abertas.
II. O modo misto (mixed) é uma combinação dos modos incorporado e servidor. O primeiro aplicativo que se conecta ao banco usando o modo incorporado, mas também inicia um servidor para que outros aplicativos (executados em diferentes processos ou JVM) possam acessar simultaneamente os mesmos dados. As conexões locais são tão rápidas quanto se o banco fosse usado apenas no modo incorporado, mas as conexões remotas são um pouco mais lentas.
III. O modo em memória (in memory) é uma especialização do modo incorporado exclusivo para aplicações que usam o H2 em exclusivamente em memória. Todos os clientes que desejam se conectar (não importa se é uma conexão local ou remota) utilizam a mesmo URL do banco de dados. Além do desempenho a vantagem é o mecanismo de persistência de dados baseada em logs de transações.
Está correto o que se afirma em
Os tipos de modelos de índice disponíveis no Elasticsearch são
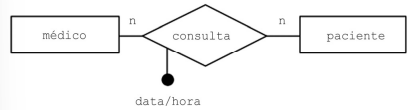
A figura precedente consiste em um DER, que representa a modelagem de uma clínica médica na qual um mesmo médico pode realizar consulta com vários pacientes, sendo possível que o mesmo paciente se consulte com o mesmo médico mais de uma vez.
A partir das informações apresentadas, é correto afirmar que, na transformação do diagrama para o modelo físico, CONSULTA
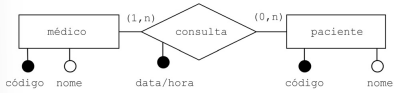
A figura precedente é um DER, que representa a modelagem de uma clínica médica na qual um mesmo médico pode realizar consulta com vários pacientes, sendo possível que o mesmo paciente se consulte com o mesmo médico mais de uma vez.
A partir das informações apresentadas, assinale a opção correta.
Ao analisar as etapas do algoritmo de otimização, Caio identificou um erro na etapa de:
A técnica de recuperação utilizada pela equipe foi o algoritmo:
Com intenção de melhoria da performance nas consultas executadas, Amanda tem trabalhado na fragmentação horizontal:
Como forma de evitar problemas de segurança com relação aos dados armazenados, o Departamento de Segurança do MPU, junto com os DBAs, precisarão:
Observe os seguintes conjuntos de dados e o comando executado no banco de dados processo do MongoDB.
Coleção:
{ "_id": 1, "descricao": "Processo trabalhista envolvendo
direitos do trabalhador" }
{ "_id": 2, "descricao": "Contrato de trabalho com
cláusulas trabalhistas" }
{ "_id": 3, "descricao": "Processo administrativo de
aposentadoria" }
Consulta:
db.processo.find({ $text: { $search: "trabalhista" } })
.sort({ score: { $meta: "textScore" } })
Resultado:
[
{ "_id": 1, "descricao": "Processo trabalhista
envolvendo direitos do trabalhador", "score": 1.2 },
{ "_id": 2, "descricao": "Contrato de trabalho com
cláusulas trabalhistas", "score": 0.9 }
]
No Mongosh, para criar um índice visando a otimizar a execução da consulta apresentada com palavra(s) específica(s) em um campo contendo strings, deve-se executar o comando:
Observe os conjuntos de dados do MongoDB a seguir.
Coleções:
Autor: { "_id": 1, "nome": "João", "email": "joao@
www.mpu.mp.br" }
Endereco: { "_id": 101, "usuario_id": 1, "quadra": "202",
"cidade": "Brasília", "cep": "70000-000" }
Resultado da junção:
{ "_id": 1, "nome": "João", "email": " joao@
www.mpu.mp.br ", "detalhes_endereco": [ { "_id": 101,
"usuario_id": 1, "quadra": "202", "cidade": " Brasília",
"cep": "70000-000" } ] }
No MongoDB, para realizar operações de junção entre as coleções combinando os dados de Autor e seu respectivo Endereco, deve-se utilizar a operação:
Para não comprometer o uso dessas chaves com a sobreposição de chaves oriundas de outras fontes, Pablo deve implementar uma chave artificial por meio de um(a):
Para otimizar o DMJus, melhorando seu desempenho, José deve criar um índice do tipo: