Questões de Concurso
Foram encontradas 13.789 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Considere que:
a. O campo id_inst é chave primária.
b. Não há outras tabelas no Banco de Dados.
c. Cada departamento possui um único valor de orçamento.
Na tabela descrita, estão cadastrados os seguintes dados:

- Um departamento concentra diversos instrutores.
- Cada instrutor pode estar relacionado a apenas um departamento.
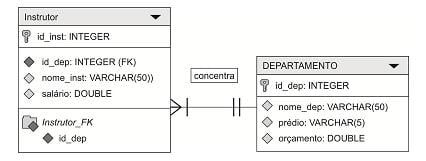
A integridade referencial está diretamente associada ao
Considere que:
a. O campo id_inst é chave primária.
b. Não há outras tabelas no Banco de Dados.
c. Cada departamento possui um único valor de orçamento.
Na tabela descrita, estão cadastrados os seguintes dados:
I. Um usuário pode alterar o orçamento do departamento de Ciências Exatas em uma tupla, mas não em todas, criando uma inconsistência.
II. As informações do departamento estão redundantes para instrutores diferentes do mesmo departamento.
III. Caso um novo departamento seja criado, seus dados só poderão ser registrados associados a um instrutor.
IV. No caso de associar o instrutor a mais de um departamento, o nome_inst e salario serão repetidos, além disso, nesse caso, será permitido manter o mesmo valor de id_inst.
Está correto o que consta APENAS em
Os componentes I, II, III e IV estão corretamente identificados em:
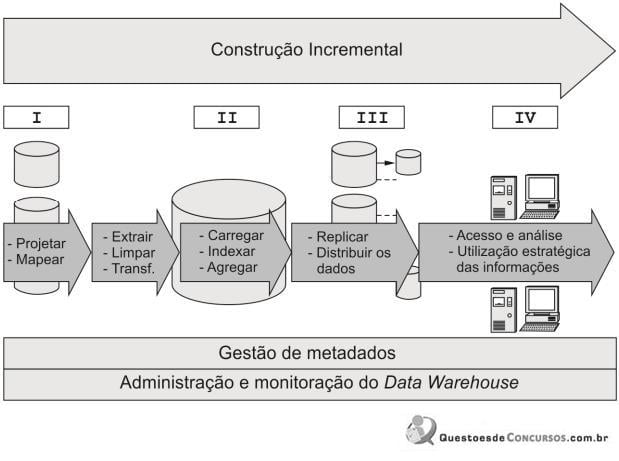
Em relação à tecnologia DW, é correto afirmar:
Sistemas e técnicas de recuperação da informação, incluindo motores de busca, são voltados para recuperação de informações relevantes. Para isso, utilizam algoritmos de lógica para organização, busca e recuperação da informação.
Sobre a recuperação da informação, assinale a alternativa CORRETA.
Os Sistemas de Recuperação de Informação (SRI) apresentam duas importantes variáveis a serem consideradas no resultado da busca: Revocação/Recall e Precisão/Precision.
Considerando as variáveis e os subsistemas de SRI, pode-se afirmar que
I. revocação/Recall é a razão do número de documentos atinentes recuperados sobre o total de documentos atinentes disponíveis na base de dados, mede a proporção de documentos relevantes retornados com o resultado da consulta do usuário.
II. revocação/Recall é a razão do número de documentos atinentes recuperados sobre o total de documentos recuperados, mede quantos documentos relevantes foram recuperados.
III. precisão/Precision é a razão do número de documentos atinentes recuperados sobre o total de documentos recuperados, mede quantos documentos relevantes foram recuperados.
A partir dessa análise, conclui-se que estão CORRETAS
Os Sistemas de Recuperação de Informação (SRI) incluem as etapas de representação, armazenamento e recuperação e é composto pelo subsistema de entrada e o de saída. Para isso, é necessário que haja uma interface na qual os usuários possam descrever suas necessidades e questões e, por meio da qual, possam também examinar os documentos atinentes recuperados e/ou suas representações.
Considerando as etapas e os subsistemas de SRI, pode-se afirmar que
I. os SRIs incluem etapa de representação das informações contidas nos documentos por meio dos processos automáticos de palavras-chave, etapa de indexação e descrição com a participação dos usuários para definir a necessidade de informação e a recuperação das informações representadas pelo armazenamento e gestão física e lógica desses documentos e de suas representações.
II. os subsistemas de entrada são compostos pelas etapas de seleção (processo intelectual de escolha dos documentos) e aquisição (procedimentos para formar a base de dados); descrição (identificar os documentos por meio de seus descritores) e representação (indexação); organização (representação) e armazenamento.
III. os subsistemas de saída são compostos de análise e negociação de questões (usuário coloca a demanda); estratégia de busca (transforma o problema de busca em necessidade de informação) e recuperação (combina os termos da busca com os termos do arquivo); disseminação e acesso (entregar o produto ao usuário); avaliação.
A partir dessa análise, conclui-se que são VERDADEIRAS
Analise as seguintes assertivas sobre representação do conhecimento na perspectiva da Ciência da Informação em tempos e espaços digitais e assinale com V as assertivas verdadeiras e com F as assertivas falsas.
( ) A representação do conhecimento para fins de classificação automática de documentos é independente da intervenção humana, não deve considerar aspectos cognitivos, a relação entre organização cognitiva imposta ao conhecimento pelo seu produtor (representação primária) e a organização conceitual imposta ao documento pelo especialista da informação (representação secundária).
( ) Na representação primária, os produtos finais são constituídos de conceitos sobre os seres, formando o conhecimento, conceitos, codificados por meio de uma linguagem simbólica.
( ) A representação é uma indicação do documento que não deve ser utilizada para a recuperação. A representação é a indexação do documento original a ser incluído no sistema, contemplando os metadados que referem ao documento sem fazer referência ao conteúdo.
( ) Na representação secundária, prática essencial nos sistemas de informações documentais, esses mesmos conceitos constantes dos registros primários são identificados em seus elementos constitutivos fundamentais que garantem a representação desse conhecimento (documento) para fins de futura recuperação.
A partir da análise das assertivas acima, assinale a sequência CORRETA.
Modelagem de recuperação da informação consiste, principalmente, na representação dos documentos para consulta. Os modelos clássicos de recuperação de informação são três: modelo Boolean, vetorial e probabilístico,
Sobre os modelos clássicos de recuperação da informação, assinale a alternativa CORRETA.
Quais propriedades mecânicas podem ser obtidas de um ensaio de tração?
A modelagem conceitual de dados é uma fase muito importante para o desenvolvimento de aplicações que utilizem bancos de dados. A modelagem utiliza entidades, relacionamentos e atributos.
O grau de um relacionamento indica o número de
Os sistemas gerenciadores de bancos de dados relacionais adotam uma arquitetura que envolve diversos esquemas com o objetivo de separar o usuário da aplicação do banco de dados físico.
A esse respeito, é correto afirmar que esses esquemas são
Com relação ao tema “Organização de arquivos”, analise as afirmativas a seguir.
I. Registros do tipo spanned não se fragmentam em mais de um bloco, são alocados de modo consecutivo no disco e utilizam a técnica do buffer duplo para otimizar as operações de leitura e escrita do bloco.
II. Registros do tipo clustered são úteis para armazenar somente as chaves primárias pesquisadas com mais frequência, os registros se fragmentam porém não são alocados de modo consecutivo no disco.
III. Registros do tipo unspanned não se fragmentam, e são armazenados integralmente dentro de um único bloco de disco.
Assinale:
Com relação ao tema “Estruturas de armazenamento e índices em bancos de dados”, analise as afirmativas a seguir.
I. Os arquivos do tipo Heap são bem simples, uma vez que os registros são posicionados segundo a ordem de inclusão, ao término do arquivo. O tempo médio de acesso para um registro é b/2, onde b é o número de blocos do arquivo.
II. Os arquivos do tipo Hash Externo fornecem acesso muito veloz aos registros em determinadas condições de pesquisa. Neste caso, é utilizado um campo hash cujo valor é calculado por uma função que gera números aleatórios. O tempo médio de acesso a um registro é b.log2b, onde b é o número de blocos do arquivo, pois se trata de uma pesquisa em árvore B+.
III. Os arquivos do tipo Sorted são bem simples, uma vez que os registros são posicionados segundo os valores de um determinado campo. O tempo médio de acesso a um dado registro é log2b, onde b é o número de blocos do arquivo, pois se trata de uma pesquisa binária.
Assinale:
Com relação ao tema “Processamento OLAP e Datawarehouse”, analise as afirmativas a seguir.
I. As operações de Roll‐Up em cubos OLAP permitem que o analista de negócios navegue entre dimensões hierárquicas, isto é de um nível mais geral para um nível mais específico.
II. As operações de Drill‐Down são o inverso das operações de Roll‐Up. O analista se move de um nível mais específico para níveis mais genéricos através de dimensões hierárquicas.
III. As operações de Pivot permitem que as dimensões de um cubo OLAP sejam reorganizadas, permitindo que os dados sejam apresentados da forma mais atraente possível.
Assinale:
Com relação ao tema “bancos de dados distribuídos”, analise as afirmativas a seguir.
I. Fragmentação horizontal de uma tabela pode ser de dois tipos: primária e derivada.
II. Fragmentação vertical de uma tabela é mais complicada que a fragmentação horizontal. Existem duas abordagens heurísticas para implementá‐la: agrupamento e divisão.
III. Fragmentação híbrida não é suportada em bancos de dados distribuídos.
Assinale:
O processo de otimização de consultas distribuídas utiliza o conceito de espaço de pesquisa.
Nesse contexto, assinale a alternativa que apresenta o conceito de espaço de pesquisa.
Com relação ao tema “Normalização”, analise as afirmativas a seguir.
I. Uma tabela está em primeira forma normal quando contém tabelas aninhadas.
II. Uma tabela está em segunda forma normal quando, além de estar em primeira forma normal, contém dependências parciais.
III. Uma tabela está em terceira forma normal quando, além de estar em segunda forma normal, não contém dependências transitivas.
Assinale: