Questões de Concurso
Foram encontradas 13.789 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Uma empresa que comercializa álbuns de figurinhas (cromos) possui um banco de dados para controlar a fabricação de cromos. O modelo conceitual desse banco de dados é exibido na Figura a seguir.
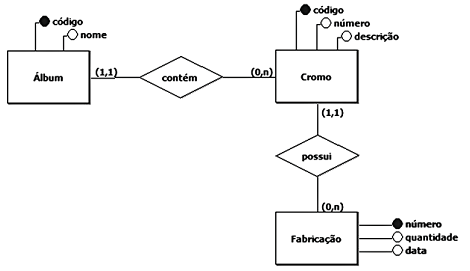
O modelo conceitual acima deu origem às seguintes Tabelas:

O gerente de produção dessa empresa deseja obter um relatório que exiba, para cada álbum comercializado, o nome do álbum, o número de cada um de seus cromos e o somatório da quantidade fabricada de cada um deles.
Qual consulta irá fornecer o relatório que o gerente de produção deseja?
Considere o conjunto de dados a seguir, obtido a partir de uma base de dados de transações ocorridas em uma padaria, em uma determinada faixa de tempo. Nesse conjunto, indica-se a ocorrência de um determinado produto em cada transação.
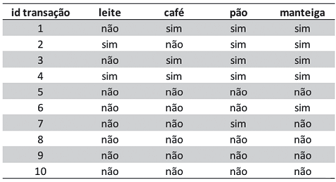
Em mineração de dados, a partir desse conjunto de dados, podem ser geradas regras de associação, as quais buscam conjuntos de itens frequentes que guardam entre si uma relação de causa e efeito. Essas regras são da forma X→Y, onde X é o antecedente da regra, e Y, seu consequente. A menção X,Y indica referência aos dois itens frequentes X e Y. Dois indicadores utilizados para averiguar a eficácia de regras de associação são o suporte e a confiança.
Qual das regras a seguir possui confiança mínima de
80%, dado um suporte mínimo de 30%?
Um gerente de TI recém-promovido ficou responsável por gerenciar todos os projetos de Sistemas de Informações Gerenciais de uma empresa. Na primeira reunião de equipe, ele deverá preparar um relatório inicial sobre o status de cada sistema sob sua responsabilidade.
A lista correta de sistemas que ele deverá apresentar na reunião é a seguinte:
Ao construir um modelo de dados para um data warehouse de sua empresa, um desenvolvedor viu-se às voltas com três tabelas relacionais: venda, cliente e vendedor.
Ao fazer uma transformação para o modelo estrela, ele deve organizar:
Em relação ao uso de modelos de dados em data warehouses, Inmon (2005) declara que o modelo de dados por trás do modelo relacional é em um nível razoavelmente alto de abstração, enquanto o modelo de processo por trás do modelo multidimensional não é de nenhuma forma abstrato.
Nesse contexto, o modelo
A principal definição de Big Data parte de três características, conhecidas como 3 V do Big Data, a saber: velocidade, variedade e volume.
O termo velocidade refere-se, principalmente, à
Dois funcionários de uma empresa de crédito discutiam sobre quais algoritmos deveriam usar para ajudar a classificar seus clientes como bons ou maus pagadores. A empresa possui, para todos os empréstimos feitos no passado, um registro formado pelo conjunto de informações pessoais sobre o cliente e de como era composta a dívida inicial. Todos esses registros tinham classificações de bons ou maus pagadores, de acordo com o perfil de pagamento dos clientes. A partir desses dados, os funcionários querem construir um modelo, por meio de aprendizado de máquina, que classifique os novos clientes, que serão descritos por registros com o mesmo formato.
A melhor opção, nesse caso, é usar um algoritmo
• Os formatos básicos são “(XX)YYYYY-YYYY” ou “(XX) YYYY-YYYY”, onde X corresponde a algarismos do código de área, e Y, a algarismos do número de assinantes; • o código de área é opcional; • os caracteres da máscara devem ser armazenados no campo; • a máscara deve ser preenchida da esquerda para a direita.
Qual a máscara de entrada mais adequada para atender ao desejo do programador?
O termo Big Data é bastante conhecido pelos profissionais de tecnologia da informação, especialmente aqueles envolvidos com bancos de dados, inteligência de negócios, sistemas de informações e sistemas de apoio à decisão.
Uma característica inerente a esse conceito é a da
O número de registros alterados pela execução do comando update TT set b = b + 1 where TT.a in (select b FROM TT) seria:
O número de registros removidos pela execução do comando delete from TTT where exists (select * FROM TTT t2 where TTT.a = t2.a and TTT.b = t2.b) seria:
III. select r.* FROM R where r.a in (select c FROM S)
IV. select r.* FROM R where exists (select 1 FROM S where r.a = s.c)
V. select distinct r.* FROM R, S where r.a = s.c
Sabe-se que quatro desses comandos sempre produzem resultados com conteúdos idênticos, mesmo considerando-se diferentes instâncias de R e S.
O comando que NÃO faz parte desse grupo é:
CREATE TRIGGER xpto BEFORE INSERT ON T FOR EACH ROW SET @s = @s + NEW.quant;
A presença do termo NEW refere-se:
CREATE TABLE T ( chave serial NOT NULL PRIMARY KEY, dados json NOT NULL ); INSERT INTO T (dados) VALUES ('{ "nome": "Maria", "notas": {"disciplina":"Fisica","nota": 10}}'), ('{ "nome": "Pedro", "notas": {"disciplina":"Calculo","nota": 9}}');
O comando SQL que produz corretamente uma lista dos alunos, com a matrícula, nome e respectivas disciplinas e notas é:
As opções que complementam essas cláusulas são:
create table X(a int identity, b int) insert into X select top 10000 NULL from T t1, T t2 alter table X drop column b select * from X
Dado que existe uma tabela T, com três colunas e 53 registros, a execução desse script gera um resultado contendo:
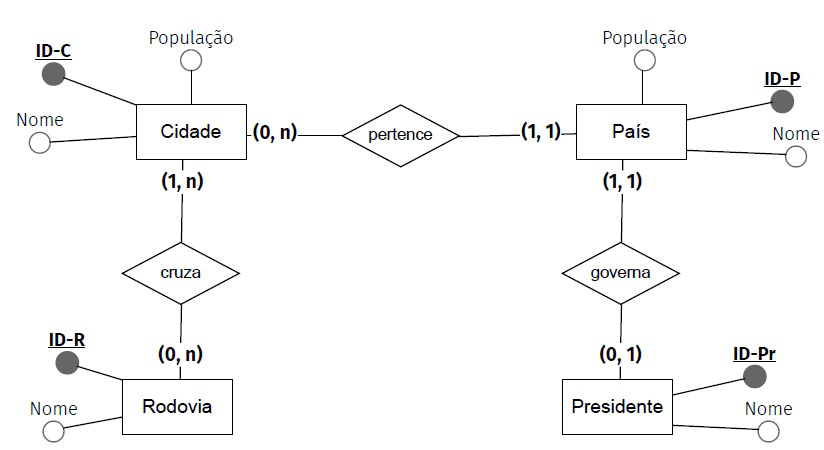
Com relação ao mapeamento desta modelagem MER para uma modelagem lógica relacional, é correto afirmar que: