Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 13.780 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387563
Banco de Dados
Analise o código abaixo descrito em PL/SQL do Oracle.

O conteúdo impresso é
O conteúdo impresso é
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387562
Banco de Dados
Bancos de dados muito grandes (VLDB) apresentam desafios de
administração, porque exigem que os DBA adotem múltiplas
estratégias para mantê-los. O particionamento é componente
chave dessas estratégias.
Com relação às vantagens do particionamento no banco de dados Oracle v23c, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Permite que operações de gerenciamento de dados, como, por exemplo, carregamento de dados, criação e reconstrução de índices e operações de backup e restore, apenas no nível de tabela inteira. Isso resulta em tempos significativamente reduzidos para executar essas operações.
( ) Melhora o desempenho das consultas SQL. Muitas vezes, os resultados de uma consulta podem ser obtidos acessando um subconjunto de partições, em vez de acessar a tabela inteira. Para algumas consultas, técnica chamada de remoção de partição pode fornecer ganhos de ordem de magnitude no desempenho.
( ) Aumenta a disponibilidade de bancos de dados de missão crítica se tabelas e índices críticos forem divididos em partições para reduzir as janelas de manutenção. A execução paralela de consultas SQL oferece vantagens específicas para otimizar e minimizar os tempos de execução. A execução paralela é suportada exclusivamente para consultas SQL do tipo DDL.
As afirmativas são, respectivamente,
Com relação às vantagens do particionamento no banco de dados Oracle v23c, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Permite que operações de gerenciamento de dados, como, por exemplo, carregamento de dados, criação e reconstrução de índices e operações de backup e restore, apenas no nível de tabela inteira. Isso resulta em tempos significativamente reduzidos para executar essas operações.
( ) Melhora o desempenho das consultas SQL. Muitas vezes, os resultados de uma consulta podem ser obtidos acessando um subconjunto de partições, em vez de acessar a tabela inteira. Para algumas consultas, técnica chamada de remoção de partição pode fornecer ganhos de ordem de magnitude no desempenho.
( ) Aumenta a disponibilidade de bancos de dados de missão crítica se tabelas e índices críticos forem divididos em partições para reduzir as janelas de manutenção. A execução paralela de consultas SQL oferece vantagens específicas para otimizar e minimizar os tempos de execução. A execução paralela é suportada exclusivamente para consultas SQL do tipo DDL.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
IBFC
Órgão:
TRF - 5ª REGIÃO
Prova:
IBFC - 2024 - TRF - 5ª REGIÃO - Técnico Judiciário - Área de Apoio Especializado - Especialidade Desenvolvimento de Sistemas da Informação |
Q2386413
Banco de Dados
Sobre Conceitos de OLAP, assinale as
alternativas abaixo e dê valores Verdadeiro (V)
ou Falso (F).
( ) OLAP é otimizado para transações em tempo real e não é adequado para análises de grandes conjuntos de dados.
( ) Cubos OLAP são estruturas multidimensionais que armazenam dados de maneira organizada para facilitar análises multidimensionais.
( ) Os dados em um cubo OLAP são armazenados de forma linear e unidimensional para facilitar consultas mais rápidas.
Assinale a alternativa que apresenta a sequência correta de cima para baixo.
( ) OLAP é otimizado para transações em tempo real e não é adequado para análises de grandes conjuntos de dados.
( ) Cubos OLAP são estruturas multidimensionais que armazenam dados de maneira organizada para facilitar análises multidimensionais.
( ) Os dados em um cubo OLAP são armazenados de forma linear e unidimensional para facilitar consultas mais rápidas.
Assinale a alternativa que apresenta a sequência correta de cima para baixo.
Ano: 2024
Banca:
IBFC
Órgão:
TRF - 5ª REGIÃO
Prova:
IBFC - 2024 - TRF - 5ª REGIÃO - Técnico Judiciário - Área de Apoio Especializado - Especialidade Desenvolvimento de Sistemas da Informação |
Q2386412
Banco de Dados
Leia a frase abaixo.
O ______ é a assimilação e compreensão de informações adquiridas, enquanto a ______ envolve a capacidade de aplicar esse ______ de maneira adaptativa, analítica e inovadora para resolver problemas e tomar decisões eficazes em diferentes contextos.
Assinale a alternativa que preencha correta e respectivamente as lacunas.
O ______ é a assimilação e compreensão de informações adquiridas, enquanto a ______ envolve a capacidade de aplicar esse ______ de maneira adaptativa, analítica e inovadora para resolver problemas e tomar decisões eficazes em diferentes contextos.
Assinale a alternativa que preencha correta e respectivamente as lacunas.
Ano: 2024
Banca:
IBFC
Órgão:
TRF - 5ª REGIÃO
Prova:
IBFC - 2024 - TRF - 5ª REGIÃO - Técnico Judiciário - Área de Apoio Especializado - Especialidade Desenvolvimento de Sistemas da Informação |
Q2386411
Banco de Dados
Analise a afirmativa abaixo e assinale a
alternativa que apresenta a qual conceito ela se
refere.
É um repositório centralizado de dados que integra informações de várias fontes, transformando e armazenando esses dados de maneira otimizada para análise e geração de relatórios, possibilitando a tomada de decisões estratégicas fundamentadas dentro de uma organização.
É um repositório centralizado de dados que integra informações de várias fontes, transformando e armazenando esses dados de maneira otimizada para análise e geração de relatórios, possibilitando a tomada de decisões estratégicas fundamentadas dentro de uma organização.
Ano: 2024
Banca:
IBFC
Órgão:
TRF - 5ª REGIÃO
Prova:
IBFC - 2024 - TRF - 5ª REGIÃO - Técnico Judiciário - Área de Apoio Especializado - Especialidade Desenvolvimento de Sistemas da Informação |
Q2386410
Banco de Dados
A linguagem SQL dispõe de diversos
comandos. Assinale a alternativa que apresenta
qual comando SQL é usado para agrupar
registros com base em valores em uma ou mais
colunas:
Ano: 2024
Banca:
IBFC
Órgão:
TRF - 5ª REGIÃO
Prova:
IBFC - 2024 - TRF - 5ª REGIÃO - Técnico Judiciário - Área de Apoio Especializado - Especialidade Desenvolvimento de Sistemas da Informação |
Q2386409
Banco de Dados
De acordo com a linguagem de manipulação de
dados em SQL, para atualizar o valor da coluna
"quantidade" para 50 na tabela "estoque" para
todos os registros onde o produto é "Leite" é:
Ano: 2024
Banca:
IV - UFG
Órgão:
Prefeitura de Inhumas - GO
Prova:
CS-UFG - 2024 - Prefeitura de Inhumas - GO - Administrador de Rede e Segurança da Informação |
Q2383865
Banco de Dados
Observe a imagem a seguir.
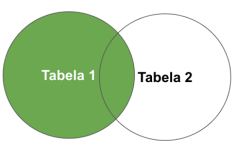
O comando SQL responsável por retornar todos os registros da tabela da esquerda e os registros correspondentes da tabela direita é
O comando SQL responsável por retornar todos os registros da tabela da esquerda e os registros correspondentes da tabela direita é
Ano: 2024
Banca:
IV - UFG
Órgão:
Prefeitura de Inhumas - GO
Prova:
CS-UFG - 2024 - Prefeitura de Inhumas - GO - Administrador de Rede e Segurança da Informação |
Q2383862
Banco de Dados
O comando utilizado para armazenar os valores padrões de
uma coluna no sistema de gerenciamento de banco de
dados PostgreSQL é
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Analista de Suporte |
Q2383489
Banco de Dados
Um sistema gerenciador de banco de dados relacional
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Analista de Sistemas |
Q2383464
Banco de Dados
Considerando o PostgreSQL como gerenciador de banco de
dados, assinale a opção que apresenta os tipos de índices com
melhor desempenho na aceleração de pesquisas de texto
completo.
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383274
Banco de Dados
No gráfico XY, são apresentados pontos que representam duas propriedades de elementos de duas classes, R e S. Os
pontos da classe R, representados como círculos, são [(3,5),(3,4),(2,3)], enquanto os pontos da classe S, representados
como quadrados, são [(4,3),(4,2),(4,1),(3,1),(2,2)]. É necessário classificar pontos novos, de acordo com o algoritmo K-NN,
com K=3, considerando a distância euclidiana.
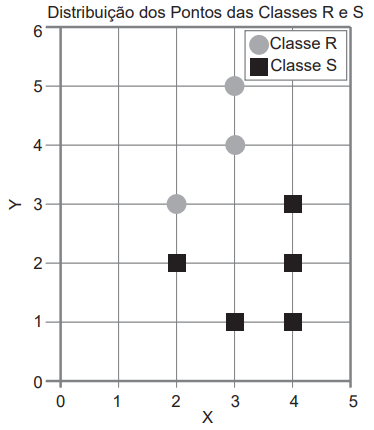
Nesse contexto, as classes dos pontos [(3,2),(3,3) e (4,4)] são, respectivamente:
Nesse contexto, as classes dos pontos [(3,2),(3,3) e (4,4)] são, respectivamente:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383243
Banco de Dados
A paralelização em rotinas de ciência de dados traz benefícios importantes, especialmente quando é necessário
tratar uma grande quantidade de dados.
O principal motivador para paralelizar uma rotina é
O principal motivador para paralelizar uma rotina é
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383239
Banco de Dados
Considere o seguinte texto sobre integração de dados.
Como viabilizar o compartilhamento efetivo de dados e informações das cadeias agropecuárias entre instituições de governo e dessas com a sociedade? Esta foi a principal questão que os participantes do 1º Painel de Cadeias Agropecuárias e Dados Abertos buscaram responder na tarde de quinta-feira (2/12), durante webinar realizado pelo Instituto de Pesquisa Econômica Aplicada (Ipea).
Disponível em: https://www.ipea.gov.br/portal/categorias/45-todas-as-noticias/noticias/11394-especialistas-debatem-abertura- -e-integracao-de-dados-de-cadeias-agropecuarias?highlight= WyJhYmFzdGVjaW1lbnRvIiwiYWd1YSIsIidcdTAwZTFndWEiLCJhZ3VhJywiXQ==. Acesso em: 5 jan. 2024.
Considerando-se o questionamento apresentado no texto e sabendo-se que, quando da integração de conjuntos de dados de múltiplas fontes, matching é uma questão relevante, o problema de identificação de entidades em múltiplas fontes de dados remete ao desafio de
Como viabilizar o compartilhamento efetivo de dados e informações das cadeias agropecuárias entre instituições de governo e dessas com a sociedade? Esta foi a principal questão que os participantes do 1º Painel de Cadeias Agropecuárias e Dados Abertos buscaram responder na tarde de quinta-feira (2/12), durante webinar realizado pelo Instituto de Pesquisa Econômica Aplicada (Ipea).
Disponível em: https://www.ipea.gov.br/portal/categorias/45-todas-as-noticias/noticias/11394-especialistas-debatem-abertura- -e-integracao-de-dados-de-cadeias-agropecuarias?highlight= WyJhYmFzdGVjaW1lbnRvIiwiYWd1YSIsIidcdTAwZTFndWEiLCJhZ3VhJywiXQ==. Acesso em: 5 jan. 2024.
Considerando-se o questionamento apresentado no texto e sabendo-se que, quando da integração de conjuntos de dados de múltiplas fontes, matching é uma questão relevante, o problema de identificação de entidades em múltiplas fontes de dados remete ao desafio de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383236
Banco de Dados
Considere um conjunto de dados que inclui as variáveis
idade, altura e peso. Os dados de idade estão entre 0 e
100 anos, os dados de altura estão entre 1,50 e 2,00 metros e os dados de peso estão entre 50 e 100 kg.
Qual das seguintes técnicas de normalização numérica é mais adequada para esse conjunto de dados?
Qual das seguintes técnicas de normalização numérica é mais adequada para esse conjunto de dados?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383235
Banco de Dados
A deduplicação de dados é uma técnica importante no gerenciamento de informações, especialmente em ambientes onde grandes volumes de dados são gerados e armazenados. Essa técnica é necessária em ambientes onde
grandes volumes de dados são gerados porque pode ajudar a reduzir o consumo de armazenamento e a aumentar
a eficiência dos processos de análise de dados.
A deduplicação de dados é útil, por exemplo, no domínio da medicina, em que há grandes conjuntos de dados genômicos que são analisados para identificar padrões e mutações associadas a doenças específicas. Nesse cenário, a deduplicação é vital para assegurar a precisão das análises, pois, se amostras de DNA de um mesmo paciente são coletadas e sequenciadas em diferentes momentos e locais, pode haver uma repetição inadvertida dessas amostras no banco de dados. Nesse contexto, a deduplicação de dados é crucial para a integridade da pesquisa, pois dados duplicados podem levar a interpretações errôneas, como a superestimação da prevalência de uma mutação genética rara.
A técnica de deduplicação de dados consiste em um processo de
A deduplicação de dados é útil, por exemplo, no domínio da medicina, em que há grandes conjuntos de dados genômicos que são analisados para identificar padrões e mutações associadas a doenças específicas. Nesse cenário, a deduplicação é vital para assegurar a precisão das análises, pois, se amostras de DNA de um mesmo paciente são coletadas e sequenciadas em diferentes momentos e locais, pode haver uma repetição inadvertida dessas amostras no banco de dados. Nesse contexto, a deduplicação de dados é crucial para a integridade da pesquisa, pois dados duplicados podem levar a interpretações errôneas, como a superestimação da prevalência de uma mutação genética rara.
A técnica de deduplicação de dados consiste em um processo de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383234
Banco de Dados
A partir de dados da pesquisa Perfil do Processado e
Produção de Provas nas Ações Criminais por Tráfico de
Drogas, realizada em dezembro de 2023 pelo Instituto de
Pesquisa Econômica Aplicada (Ipea), é possível levantar
informações sociodemográficas sobre os bairros em que
o direito à inviolabilidade domiciliar é relativizado. Os resultados revelam que os bairros mais ricos e aqueles de
população predominantemente branca são praticamente
imunes às entradas em domicílio, as quais se concentram
substancialmente nos bairros mais pobres e naqueles
com população predominantemente negra ou minoritariamente branca.
Qual técnica de desidentificação de dados sensíveis é a mais adequada para preservar a privacidade dos indivíduos processados, permitindo, ainda, a análise sociodemográfica dos bairros?
Qual técnica de desidentificação de dados sensíveis é a mais adequada para preservar a privacidade dos indivíduos processados, permitindo, ainda, a análise sociodemográfica dos bairros?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383232
Banco de Dados
A limpeza de dados, data cleansing, é uma tarefa importante que pode ser complexa e demorada, no entanto é
um investimento fundamental que pode melhorar a qualidade e a utilidade dos dados para futuras análises.
Seja um conjunto de dados com informações de saúde referentes a uma população. Pode-se limpar esses dados para identificar e tratar valores extremos, discrepantes, contraditórios ou inválidos. Com isso, há maior confiabilidade para estimar a prevalência, a incidência, a mortalidade e os fatores de risco de uma doença naquela população representada por aqueles dados.
Por exemplo, seja o conjunto de dados abaixo referente a uma amostra de 5 indivíduos em uma mesma cidade, na qual um analista percebeu a necessidade de limpeza de dados por conta de potenciais inconsistências.
Indivíduo 1: Sexo: Feminino; Idade: 8 anos; Altura: 1,15m; Peso: 40kg; Batimento Cardíaco em Repouso: 85 bpm
Indivíduo 2: Sexo: Masculino; Idade: 22 anos; Altura: 1,60m; Peso: 60kg; Batimento Cardíaco em Repouso: 72 bpm
Indivíduo 3: Sexo: Feminino; Idade: 40 anos; Altura: 1,60m; Peso: 55kg; Batimento Cardíaco em Repouso: 10 bpm
Indivíduo 4: Sexo: Masculino; Idade: 55 anos; Altura: 1,90m; Peso: 100kg; Batimento Cardíaco em Repouso: 70 bpm
Indivíduo 5: Sexo: Feminino; Idade: 70 anos; Altura: 1,50m; Peso: 60kg; Batimento Cardíaco em Repouso: 70 bpm
Qual ação é a única claramente necessária para realizar data cleansing neste conjunto de dados específico?
Seja um conjunto de dados com informações de saúde referentes a uma população. Pode-se limpar esses dados para identificar e tratar valores extremos, discrepantes, contraditórios ou inválidos. Com isso, há maior confiabilidade para estimar a prevalência, a incidência, a mortalidade e os fatores de risco de uma doença naquela população representada por aqueles dados.
Por exemplo, seja o conjunto de dados abaixo referente a uma amostra de 5 indivíduos em uma mesma cidade, na qual um analista percebeu a necessidade de limpeza de dados por conta de potenciais inconsistências.
Indivíduo 1: Sexo: Feminino; Idade: 8 anos; Altura: 1,15m; Peso: 40kg; Batimento Cardíaco em Repouso: 85 bpm
Indivíduo 2: Sexo: Masculino; Idade: 22 anos; Altura: 1,60m; Peso: 60kg; Batimento Cardíaco em Repouso: 72 bpm
Indivíduo 3: Sexo: Feminino; Idade: 40 anos; Altura: 1,60m; Peso: 55kg; Batimento Cardíaco em Repouso: 10 bpm
Indivíduo 4: Sexo: Masculino; Idade: 55 anos; Altura: 1,90m; Peso: 100kg; Batimento Cardíaco em Repouso: 70 bpm
Indivíduo 5: Sexo: Feminino; Idade: 70 anos; Altura: 1,50m; Peso: 60kg; Batimento Cardíaco em Repouso: 70 bpm
Qual ação é a única claramente necessária para realizar data cleansing neste conjunto de dados específico?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383231
Banco de Dados
Um cientista de dados precisa discretizar uma variável, representando distâncias entre cidades em quilômetros em
10 intervalos com, aproximadamente, o mesmo número
de observações.
Nesse contexto, a técnica mais adequada é a discretização
Nesse contexto, a técnica mais adequada é a discretização
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383230
Banco de Dados
Para a avaliação de políticas públicas na área de Segurança Alimentar e Nutricional, um município brasileiro utilizou dados
persistidos em três relações (tabelas) organizadas de acordo com o seguinte modelo relacional:
PRODUTO (cod-produto, nome-produto, grupo-alimentar) FORNECEDOR (CNPJ, nome-empresa, tipo) COMPRADO (CNPJ, cod-produto, data, quantidade, valor)
Os atributos que formam as chaves primárias de cada tabela estão sublinhados.
Nesse contexto, considere o comando SQL apresentado a seguir.
SELECT P.cod-produto, SUM (quantidade) FROM PRODUTO P, FORNECEDOR F, COMPRADO C WHERE P.cod-produto = C.cod-produto AND C.CNPJ = F.CNPJ AND F.tipo = 'agricultura familiar' GROUP BY P.cod-produto HAVING SUM (quantidade) > 10000
Os resultados produzidos pela execução desse comando apresentam o código do produto e a soma das quantidades compradas dos produtos de
PRODUTO (cod-produto, nome-produto, grupo-alimentar) FORNECEDOR (CNPJ, nome-empresa, tipo) COMPRADO (CNPJ, cod-produto, data, quantidade, valor)
Os atributos que formam as chaves primárias de cada tabela estão sublinhados.
Nesse contexto, considere o comando SQL apresentado a seguir.
SELECT P.cod-produto, SUM (quantidade) FROM PRODUTO P, FORNECEDOR F, COMPRADO C WHERE P.cod-produto = C.cod-produto AND C.CNPJ = F.CNPJ AND F.tipo = 'agricultura familiar' GROUP BY P.cod-produto HAVING SUM (quantidade) > 10000
Os resultados produzidos pela execução desse comando apresentam o código do produto e a soma das quantidades compradas dos produtos de