Foram encontradas 13.789 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
No contexto do PostgreSQL, analise o esquema de um comando a seguir.
CREATE ... nome
LOCATION 'path completo';
Especificados o nome e o path completo, o texto que pode completar o trecho pontilhado para que esse comando seja válido é
No contexto da administração de um ambiente PostgreSQL, analise o comando a seguir.
pg_dump XXXX > saida.sql
O efeito causado pela execução desse comando é
Num ambiente Oracle, no âmbito do Database Resource Manager, analise o comando a seguir.
EXEC
DBMS_RESOURCE_MANAGER_PRIVS.
GRANT_SYSTEM_PRIVILEGE - (GRANTEE_NAME => 'xxxxx', -
PRIVILEGE_NAME =>
'ADMINISTER_RESOURCE_MANAGER', -
ADMIN_OPTION => FALSE);
Assinale o efeito desse comando.
A otimização foca na determinação do modo mais eficiente para obter o resultado. Nesse contexto, o “estimator” é o componente que avalia o consumo de recursos num certo plano de execução.
De acordo com o que é preconizado pela Oracle, os fatores pelos quais o custo é estimado são:
Assinale o comando que produz corretamente essas informações.
I. tempdb é recriado sempre quando o SQL Server é iniciado.
II. model é criado opcionalmente, e pode ser utilizado apenas como read only.
III. master não permite operações de backup e/ou recuperação.
Está correto o que se afirma apenas em
Assinale o comando que retornaria o valor 1 no resultado.
C -> H
C -> P
C -> N
P -> C
O comando SQL utilizado na criação dessa tabela é exibido a seguir.
create table T (
C int not null unique,
H int null unique,
P int null unique,
N int not null )
Assinale a dependência funcional adicional necessária para que o esquema acima esteja de acordo com a forma normal Boyce-Codd.
Analise as alternativas SQL que foram consideradas para a remoção das linhas redundantes.
I. Utilizar o comando delete com a cláusula except one.
II. Utilizar o comando delete incluindo a cláusula exists, o que faria com que a última linha de cada grupo de repetições não seria removida uma vez que não mais existiria uma outra linha idêntica.
III. Introduzir, temporariamente, uma nova coluna na tabela, com valores gerados por meio de um mecanismo de auto increment, ou sequence, e utilizar o uso do comando delete incluindo a cláusula exists.
Em relação a essas alternativas, é correto afirmar que
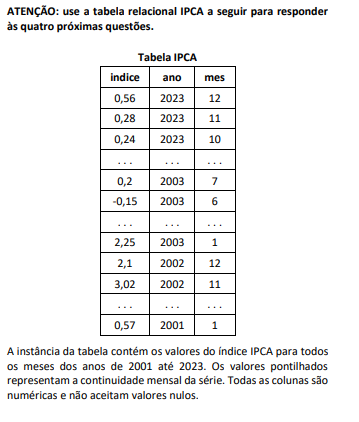
Assinale o comando SQL que produz as colunas ano, mes e indice,
da tabela IPCA apresentada, ordenadas por ano/mês e precedidas
por uma coluna com a numeração sequencial das linhas a partir de
1.
No contexto da tabela IPCA apresentada, analise o comando SQL a seguir.
select avg(indice)
from IPCA
group by mes
order by mes
A execução desse comando gera
No contexto da tabela IPCA apresentada, analise os dois comandos
SQL a seguir.

Sobre a execução desses comandos, assinale a afirmativa correta.
Assinale esses níveis, na ordem em que são usualmente empregados nessa estratégia.
I. Tipicamente, data warehouses armazenam dados em esquemas definidos, o que permite otimizar consultas em SQL.
II. Data lakes prestam-se a armazenar dados oriundos de fontes externas, tais como sensores e mídias sociais, dentre outras, com formatos diversificados e estruturas não completamente definidas.
III. Embora haja diferenças importantes, ambos são implementados e operados por meio de Sistemas Gerenciados de Bancos de Dados (SGBD) e coletam dados por meio de ferramentas de ETL.
Está correto somente o que se afirma em
No contexto da execução eficiente de uma consulta, assinale a definição correta para o conceito de Query Plan (Plano de Consulta).
Z = (x – µ) / σ
Na fórmula, “Z” é um fator (ou escore) que permite estabelecer se o valor numérico “x” deve ser considerado um outlier ou não.
Os símbolos “µ” e “σ” empregados na fórmula significam respectivamente: