Questões de Concurso
Sobre banco de dados para fgv
Foram encontradas 1.880 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
O modelo a seguir apresenta a relação entre as entidades Arvore e Mata, assim como seus atributos e cardinalidades.
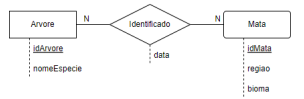
O usuário Kadu solicita ao DBA Caue uma visão das espécies de árvores, biomas e a data que foram identificadas. Como não é permitida a criação de VIEWs no esquema das tabelas do sistema, o DBA cria o objeto abaixo em seu próprio esquema:
CREATE OR REPLACE VIEW arvoreBioma AS
SELECT a.nomeEspecie, m.bioma FROM owner.arvore a, owner.mata m, owner.identificado i
WHERE a.idArvore = i.idArvore AND
m.idMata = i.idMata
Para que Kadu possa ter permissão de seleção na VIEW,
Considere que, no banco de dados do sistema financeiro da empresa XPTO, exista uma tabela chamada Fatura. Essa tabela possui bilhões de tuplas e não está particionada. O Analista de banco de dados propõe particionar a tabela Fatura utilizando a coluna Ano.
O SGBD utilizado para gerenciar o banco de dados do sistema é o SQL Server. Com relação aos itens que devem ser cumpridos para realizar o particionamento da tabela, analise as afirmativas a seguir:
I. Os componentes fundamentais para particionar a tabela são: elaborar uma função de partição, criar um esquema de partição, especificar novo grupo de arquivos no banco de dados, criar arquivos de dados para cada ano e criar índice clusterizado contendo a coluna utilizada para o particionamento.
II. A função de partição com RANGE RIGHT sobre uma coluna datetime ou datetime2 indica que as tuplas registradas meia noite ficaram em outra partição, ou seja, sendo o primeiro elemento da fragmentação seguinte.
III. A função de partição não permite parâmetro de input dos tipos de dados varchar ou nvarchar.
IV. Se não for especificado o método adotado para criar os intervalos de fragmentação na função de partição por padrão é adotado o RANGE LEFT.
Está correto o que se afirma em
Considere que o sistema de controle de pagamentos da metalúrgica Ferro Forte está no SGBD SQL Server, e vem apresentando perda de performance no processo de fechamento da folha de pagamento. O analista de banco de dados constata que o tipo de espera mais comum se refere ao paralelismo do plano de execução (CXPACKECT).
Visando a otimizar a performance da consulta em relação aos recursos de CPU e de memória do servidor, assinale a opção que lista os parâmetros que devem ser ajustados para melhorar o paralelismo.
Considere que no banco de dados do sistema financeiro da empresa XPTO exista uma tabela chamada Fatura. Essa tabela possui bilhões de tuplas e não está particionada. O Analista de banco de dados propõe particionar a tabela Fatura utilizando a coluna Ano.
O SGBD utilizado para gerenciar o banco de dados do sistema é o SQL Server. Com relação aos itens que devem ser cumpridos para realizar o particionamento da tabela, analise os itens a seguir:
I. Os componentes fundamentais para particionar a tabela são: elaborar uma função de partição, criar um esquema de partição, especificar novo grupo de arquivos no banco de dados, criar arquivos de dados para cada ano e criar índice clusterizado contendo a coluna utilizada para o particionamento.
II. A função de partição com RANGE RIGHT sobre uma coluna datetime ou datetime2 indica que as tuplas registradas meia noite ficaram em outra partição, ou seja, sendo o primeiro elemento da fragmentação seguinte.
III. A função de partição não permite parâmetro de input dos tipos de dados varchar ou nvarchar.
IV. Se não for especificado o método adotado para criar os intervalos de fragmentação na função de partição por padrão é adotado o RANGE LEFT.
Está correto o que se afirma em
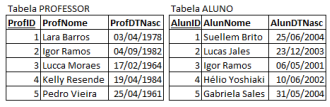
As tabelas PROFESSOR e ALUNO registram os identificadores únicos, nomes e datas de nascimento de professores e alunos de uma universidade.
Qual das alternativas irá produzir uma lista contendo um único
atributo com todos os nomes de alunos e professores de forma a
não repetir homônimos?
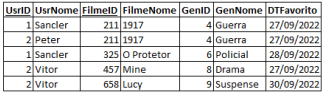
A tabela PUBSTREAM registra os usuários de uma plataforma de streaming de filmes escolhendo seus filmes favoritos. As colunas UsrID e FilmeID compõe a chave primária da tabela.
Cada usuário possui um identificador único UsrID e um nome UsrNome.
Cada filme possui um identificador único FilmeID e um nome FilmeNome. Cada gênero possui um identificador único GenID e um nome GenNome.
O dia em que o usuário "favorita" o filme é registrado na coluna DTFavorito.
A tabela apresentada está desnormalizada. Considerando as dependências funcionais, qual das alternativas descreve a passagem à terceira forma normal (3FN)?
CREATE TABLE T(A int not null UNIQUE, B int not null UNIQUE, C int)
Considere ainda as seguintes dependências funcionais acerca dos atributos A, B e C.
A → B B → A A → C B → C
As dependências necessárias para que o esquema relacional acima esteja normalizado até a Forma Normal Boyce-Codd são:
delete from T1 where exists(select * from T2 where T1.A1 = T2.A2)
Para testar seu comando e descobrir exatamente quais seriam as linhas deletadas, Caio pretende executar um comando sem alteração de dados que permita a identificação dessas linhas.
Para isso, basta que Caio substitua no comando original o termo:
REATE TABLE T1(A1 int not null UNIQUE,
B1 int not null)
CREATE TABLE T2(A2 int not null UNIQUE,
B2 int,
FOREIGN KEY (B2) references T1(A1))
Para n >= 1, está correto concluir que:
A segurança de dados implementada no eSAC foi:

No PowerBI, quando um visual tem uma hierarquia, para revelar detalhes adicionais de um dado agregado, deve-se executar a operação:

No PDI, para implementar tarefas, como Carrega Salário, Calcula Classe e Armazena Classe, deve-se usar:
Observe a seguinte modelagem dimensional.

A técnica utilizada para implementar a dimensão tempo e seus
diferentes relacionamentos com a tabela fato é:
A operação de limpeza da fase de preparação de dados para tratar os pontos extremos existentes em uma série temporal a ser executada por João é:
O PowerBI possui diversas visualizações, conforme ilustrado a seguir.

No PowerBI, o gráfico autônomo usado para filtrar os outros
visuais da página, restringindo a parte do conjunto de dados que
é mostrado nas outras visualizações do relatório, é:
SELECT * FROM T1 LEFT JOIN T2 ON T1.A=T2.A RIGHT JOIN T3 ON T1.A=T3.A
deverá produzir um resultado que contenha, além da linha de títulos, no mínimo e no máximo:
Analise o comando SQL a seguir.

Dado que as operações primitivas da Álgebra Relacional (A.R.) são
a Seleção, a Projeção, o Produto, a Diferença e a União, as
operações necessárias para construir por meio da A.R. uma
expressão equivalente ao comando acima são, apenas:
A operação analítica que se caracteriza por analisar dados em níveis de agregação progressivamente mais detalhados e de menor granularidade, é denominada
“A tarefa de detecção de anomalias é um caso particular de problema de _____, onde a quantidade de objetos da classe alvo (anomalia) é muito inferior à quantidade de objetos da classe normal e, adicionalmente, o custo da não detecção de uma anomalia (_____) é normalmente muito maior do que identificar um objeto normal como uma anomalia (_____)”
Assinale a opção cujos itens completam corretamente as lacunas do fragmento acima, na ordem apresentada.