Foram encontradas 1.880 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
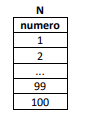
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
Walter, fiscal de rendas, está analisando os tributos municipais pagos por estabelecimentos comerciais e prestadores de serviço ao longo dos últimos cinco anos, utilizando a ferramenta Power Bl. Para refinar a sua análise, Walter precisa gerar um relatório que permita realizar operações como drili-down.
A visualização que Walter deve usar é:
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
• DW_Tributos, banco de dados analítico do tipo Data Warehouse que integra dados sobre os tributos arrecadados do Município do Rio de Janeiro.
• TP_EMPRESA, Caractere, 1, atributo que descreve o tipo da empresa contendo os seguintes valores: M - MEI ou S - Simples Nacional, e faz parte da tabela TB _EMPRESA.
• RL_Sit_Fiscal, relatório sobre a situação fiscal das empresas do Município do Rio de Janeiro.
O componente do ambiente de Data Warehousing, utilizado por Inácio, que foi desenvolvido para apoiar consultas sobre a descrição de cada artefato de dado, é:
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
Este é a resultado produzido por um determinado script SQL que utiliza a tabela N, anteriormente descrita.
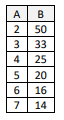
Abaixo, são apresentadas três versões para o referido script, não necessariamente corretas.

Sobre essas afirmativas, é correto afirmar que:
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
Analise o comando SQL a seguir, que faz referência à tabela N descrita anteriormente.
select n1.numero* n2.numero
from N n1, N n2
where n1.numero <> n2.numero
O número de linhas do resultado produzido pela execução desse comando, sem contar a linha de títulos, é:
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
Assinale o comando SQL que produz a lista de todos, e somente, os números primos presentes na tabela N, descrita anteriormente.
I. Data warehouses são uma coleção de dados orientada a assunto, volátil, variável no tempo para apoiar os processos de suporte à tomadas de decisões. II. O esquema floco de neve é uma variação do esquema estrela, em que as tabelas das dimensões são organizadas em uma hierarquia ao normalizá-las. III. Uma constelação de fatos é um conjunto de tabelas de fatos que compartilham algumas tabelas de dimensão.
Está correto apenas o que se afirma em
Considerando duas relações, R e S, analise as afirmativas a seguir:

Está correto o que se afirma em
Os hipercubos podem ser do tipo
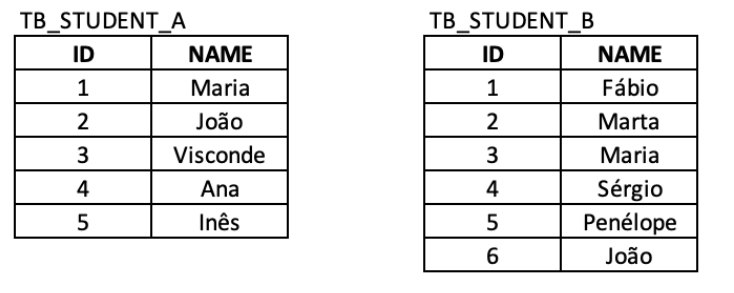
Analise a seguinte consulta em linguagem SQL: SELECT * FROM TB_STUDENT_A LEFT JOIN TB_STUDENT_B ON TB_STUDENT_A.NAME=TB_STUDENT_B.NAME.
O número de linhas do resultado produzido pela execução deste comando SQL sobre o banco de dados desta escola, excetuada a linha de títulos, é:
I. No Roll-up, os níveis cada vez menores de detalhes dos dados são revelados. II. No Drill-down, os dados são expandidos com generalizações cada vez maiores, por exemplo, de quinzenal para mensal para trimestral para semestral. III. No Slice-and-dice, as operações de projeção são realizadas nas dimensões do modelo multidimensional.
As afirmativas são, respectivamente,
I. Data warehouse de nível empresarial: oferecem múltiplas visões sobre bancos operacionais, as visões são materializadas para obter acessos mais seguros aos dados. II. Data mart: possuem um foco mais específico, são direcionados para um subconjunto de setores de uma organização, por exemplo, um departamento. III. Data mart virtuais: são imensos projetos complexos que demandam investimentos expressivos de tempo e de recursos computacionais e humanos.
Está correto o que se afirma em
Em relação ao tema, analise as afirmativas a seguir: I. Custo de acesso ao armazenamento secundário é aquele que considera os custos de transferência (leitura e escritas) de blocos de dados entre o armazenamento de disco secundário e os buffers da memória principal. II. Custo de operação é o custo de realização de operações na memória em registros dentro do buffer de dados durante a execução da consulta. III. Custo de uso da memória é o custo de envio de consulta e seus resultados do local do banco de dados até o local ou equipamento onde foi originada a consulta.
Está correto o que se afirma em
create table T ( codigo int not null, produto varchar (40) not null, preço float not null default 0 check (preço >= 0), imposto float not null default 0 check (imposto <=100))
Assinale o comando SQL de inserção de registro que provocaria um erro.
delete from T where not exists (select * from T tt where T.A > tt.A)
Dado que a tabela tem 100 linhas preenchidas, assinale a opção que indica o número de linhas que será deletado pela execução do referido comando.
Considere a estrutura de dados a seguir.
{
titulo: "Votação no Congresso",
corpo: "A votação foi realizada em São Paulo.",
categoria: "Notícias",
vistas: 200,
assuntos: ["lei", "impostos"],
data: 12/05/2023
}
Na categorização pertinente aos bancos de dados da classe NoSQL, esse tipo de arranjo das informações é considerado
Assinale a extensão de arquivo que é usualmente empregada em arquivos dessa natureza.