Questões de Concurso
Sobre banco de dados para fgv
Foram encontradas 1.880 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
I. O programa mariadb-dump executa um backup lógico no MariaDB. É a maneira mais flexível de realizar backup e restore de dados, é uma boa opção quando o tamanho dos dados é relativamente pequeno. Para conjuntos de dados grandes, o arquivo de backup pode ser grande e o tempo de restauração demorado.
II. O programa mariadb-hotcopy é um fork do Percona XtraBackup com suporte adicional para compactação e criptografia de dados. O programa está disponível na versão MariaDB 10.1 ou posterior.
III. O programa mariadb-backup realiza um backup físico e funciona apenas para fazer backup de tabelas MyISAM e ARCHIVE. Ele só pode ser executado na mesma máquina que o local dos diretórios do banco de dados.
Está correto o que se afirma em
Em relação ao CAP, avalie se as afirmativas a seguir são verdadeiras (V) ou falsas (F).
( ) As três letras significam: Completeness, em português completude, Atomicity, em português atomicidade e Partition tolerance, em português, tolerância de partição.
( ) A atomicidade significa que cada solicitação de leitura ou gravação para um item de dados será processada com sucesso ou receber uma mensagem informando que a operação não pode ser concluída.
( ) A Tolerância de partição significa que o sistema não pode continuar operando com consistência se a rede que conecta os nós apresentar muitas falhas em duas ou mais partições, onde os nós em cada partição não podem se comunicar.
As afirmativas são, respectivamente,
Os três fatores mais importantes são
( ) A primeira fase, é denominada fase de reconhecimento do plano de execução de consultas (ou reconhecimento), novos bloqueios de itens podem ser adquiridos, mas nenhum pode ser liberado.
( ) A segunda fase, é denominada fase de demarcação do plano de execução de consultas (ou demarcação), durante a fase os bloqueios existentes devem ser liberados, mas nenhum novo bloqueio pode ser realizado.
( ) Se a conversão de bloqueio for permitida, então a atualização de bloqueios (de bloqueados para gravação para bloqueados para leitura) deve ser feita durante a fase de reconhecimento, e o downgrade dos bloqueios (de bloqueados para leitura para bloqueados para gravação) deve ser feito na fase de demarcação.
As afirmativas são, respectivamente,
Com relação aos índices do tipo cluster, avalie se as afirmativas a seguir são verdadeiras (V) ou falsas (F).
( ) Não são usados para acelerar a recuperação de todos os registros que possuem o mesmo valor para o campo de cluster.
( ) Um índice de clustering também é um arquivo ordenado com dois campos; o primeiro campo é do mesmo tipo que o campo de cluster do arquivo de dados, e o segundo campo é um bloco de disco ponteiro.
( ) Há uma entrada no índice de clustering para cada grupo de valor iguais do campo de clustering e contém o valor e um ponteiro para o primeiro bloco nos dados arquivo que possui um registro com esse valor para seu campo de cluster.
As afirmativas são, respectivamente,
Atualmente existem diversos tipos de bancos de dados NoSQL. Relacione cada tipo de banco NoSQL a seguir com sua descrição.
1. MongoDB
2. Neo4J
3. HBase
4. Redis
( ) Começou como um banco de dados orientados a grafos e evoluiu para um rico ecossistema com inúmeras ferramentas de apoio. Utiliza a Cypher como sua linguagem de consultas.
( ) Banco de dados multiplataforma orientado a documentos. Fornece alto desempenho, alta disponibilidade e fácil escalabilidade. Utiliza documentos semelhantes ao JSON como esquema. É publicado sob uma combinação da Licença Pública Geral GNU e Apache.
( ) Banco de código aberto com licença BSD, é capaz de armazenar estrutura de dados na memória. Fornece estruturas de dados como strings, hashes, listas, conjuntos, conjuntos classificados com consultas de intervalo, bitmaps, hiperlogs, índices geoespaciais e fluxos. Possui replicação integrada, script Lua, transações e diferentes níveis de persistência em disco, e fornece alta disponibilidade.
( ) Banco de dados do Hadoop. Capaz de hospedar tabelas muito grandes com bilhões de linhas e milhões de colunas. É um banco de dados não relacional de código aberto, distribuído e modelado a partir do Big Table do Google.
Assinale a opção que indica a relação correta, na ordem apresentada.
( ) O modelo conceitual pode ter a forma de um diagrama entidade-relacionamentos e captura as necessidades de uma organização em termos de armazenamento de dados independentemente da sua implementação.
( ) O projeto lógico tem como objetivo transformar o modelo conceitual obtido na primeira fase em um modelo lógico que definirá como o banco de dados será implementado em um SGBD.
( ) Na etapa do projeto físico, o modelo de banco d e dados é enriquecido com detalhes que influenciam no desempenho do banco mas interferem em suas funcionalidades.
As afirmativas são, respectivamente,
Sobre as características do Big Data, analise os itens a seguir.
I. Veracidade.
II. Valor.
III. Validade.
Está correto o que se afirma em
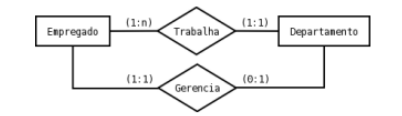
Considere as afirmativas acerca deste diagrama e do modelo Entidade-Relacionamento:
I. No diagrama acima os losangos denominados ‘Trabalha’ e ‘Gerencia’ são denominados de Entidades do modelo;
II. A notação das cardinalidades define seus valores na forma (mínima, máxima);
III. O Modelo Entidade-Relacionamento permite associar atributos tanto a entidades como a relacionamentos.
Está correto apenas o que se afirma em
( ) Existem diversas tecnologias para processamento e análise de Big Data, mas a maioria possui algumas características comuns. Ou seja, adotam técnicas de escalonamento e processamento paralelo; utilizam dados não relacionais, e aplicam análises avançadas e visualização de dados.
( ) Existem três tecnologias de Big Data que se destacam: MapReduce, Hadoop e NoSQL. O Hadoop é uma técnica popularizada pelo Google que distribui o processamento de dados em grandes arquivos de dados multiestruturados em um grande cluster que pode ser alcançado dividindo o processamento em pequenas unidades de trabalho que podem ser executadas em paralelo.
( ) O MapReduce é um modelo de programação e uma implementação associada para processar e gerar grandes conjuntos de dados. Os programas escritos neste estilo funcional são automaticamente paralelizados e executados em um grande cluster de máquinas de alto desempenho. O modelo que programadores sem qualquer experiência com sistemas paralelos e distribuídos utilizem facilmente os recursos.
As afirmativas são, respectivamente,
1. Orientados a Assunto.
2. Integração.
3. Não Volátil.
4. Variante no Tempo.
( ) O foco de um data warehouse na mudança ao longo do tempo é essencial para descobrir tendências e identificar padrões e relacionamentos ocultos nos negócios, para isso os analistas precisam de grandes quantidades de dados. Isso contrasta muito com o processamento de transações on-line onde os requisitos de desempenho exigem que os dados históricos sejam movidos para arquivos.
( ) Os data warehouses devem colocar dados de fontes diferentes em um formato consistente. Eles devem resolver problemas como nomear conflitos e inconsistências entre unidades de medida.
( ) Significa que, uma vez inseridos no data warehouse, os dados não devem mudar. Essa característica é lógica porque o propósito de um data warehouse é permitir que um analista analise o que ocorreu no passado.
( ) Os data warehousessão projetados para ajudar os profissionais a analisar grandes volumes de dados. Por exemplo, para saber mais sobre os dados de vendas de uma empresa, o analista pode construir um data warehouse que concentre a venda. Usando esse data warehouse, ele poderá responder perguntas como "Quem foi nosso melhor cliente para este item no ano passado?" ou "Quem provavelmente será nosso melhor cliente no próximo ano?"
A relação correta, na ordem dada, é:
( ) O operador LIKE é usado em uma cláusula WHERE para procurar um padrão especificado em uma coluna. Existem dois curingas frequentemente usados em conjunto com este operador; o sinal de % representa zero, um ou vários caracteres, já o sinal de - representa um único caractere.
( ) O operador IN permite especificar vários valores em uma cláusula WHERE. Ele é uma abreviação para múltiplas condições OR e AND sequenciais. Ao usar a palavra-chave NOT na frente do operador IN, haverá o retorno todos os registros que não são nenhum dos valores de uma lista.
( ) A palavra-chave RIGHT JOIN retorna todos os registros da tabela à direita em uma junção e os registros correspondentes da tabela à esquerda em uma junção. O resultado é zero registro do lado esquerdo, se não houver correspondência.
As afirmativas são, respectivamente,
O símbolo gráfico utilizado para representar uma entidade associativa no diagrama ER, considerando a notação Chen, é
Uma das atividades mais importantes na administração de dados é a manutenção de cópias de segurança (Backups). Em termos gerais, podemos dividir as cópias de segurança em duas categorias: cópia física ou cópia lógica.
Um gestor está preocupado, em primeiro lugar, com a velocidade de criação e recuperação das cópias de segurança, e, em segundo lugar, com a facilidade de operação das ferramentas, pois sua equipe está sobrecarregada. Ele recebeu os cinco conselhos a seguir de integrantes da equipe.
Assinale o conselho mais adequado para esse caso.
ATENÇÃO: Na questão a seguir, considere a tabela T,
com colunas A, B e C, descrita a seguir juntamente com a sua instância.
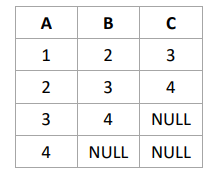
Considere, ainda, o comando SQL a seguir, que referencia a tabela T.

ATENÇÃO: Na questão a seguir, considere a tabela T,
com colunas A, B e C, descrita a seguir juntamente com a sua instância.
Considere, ainda, o comando SQL a seguir, que referencia a tabela T.
I. Tablespaces podem operar no modo read-only. II. Não é possível renomear uma tablespace. III. É possível colocar uma tablespace off-line, tornando-a temporariamente indisponível, mantendo a operação do banco de dados normal.
Está correto o que se afirma em