Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 1.880 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
CGE-PB
Prova:
FGV - 2024 - CGE-PB - Auditor de Contas Públicas - Auditoria de Tecnologia da Informação |
Q2398333
Banco de Dados
João precisa criar um esquema normalizado para a tabela R, que
contém cinco colunas, que não admitem valores nulos, como
ilustrado no esquema abaixo.
R (A, B, C, D, E)
Sobre essas colunas (ou atributos), João levantou as dependências funcionais seguintes.
A -> B B -> C C -> D D -> E D -> A
Dentre os esquemas SQL esboçados por João, o que melhor representa a tabela R, com suas restrições, é:
R (A, B, C, D, E)
Sobre essas colunas (ou atributos), João levantou as dependências funcionais seguintes.
A -> B B -> C C -> D D -> E D -> A
Dentre os esquemas SQL esboçados por João, o que melhor representa a tabela R, com suas restrições, é:
Ano: 2024
Banca:
FGV
Órgão:
CGE-PB
Prova:
FGV - 2024 - CGE-PB - Auditor de Contas Públicas - Auditoria de Tecnologia da Informação |
Q2398332
Banco de Dados
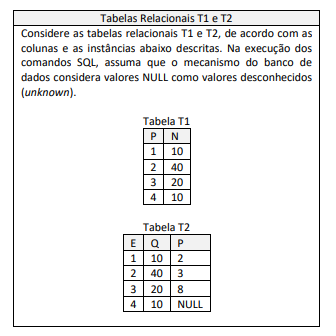
Tomando como base somente as instâncias das tabelas T1 e T2,
anteriormente apresentadas, considere o conjunto de
dependências funcionais que, possivelmente, poderiam ser
verificadas.
(1) P -> N (2) N -> P (3) E -> Q (4) E -> P (5) Q -> P (6) Q -> E (7) P -> E (8) P -> Q
Dessa lista enumerada, o conjunto completo das únicas dependências funcionais que poderiam ser corretamente depreendidas é:
(1) P -> N (2) N -> P (3) E -> Q (4) E -> P (5) Q -> P (6) Q -> E (7) P -> E (8) P -> Q
Dessa lista enumerada, o conjunto completo das únicas dependências funcionais que poderiam ser corretamente depreendidas é:
Ano: 2024
Banca:
FGV
Órgão:
CGE-PB
Prova:
FGV - 2024 - CGE-PB - Auditor de Contas Públicas - Auditoria de Tecnologia da Informação |
Q2398331
Banco de Dados
Considerando as tabelas T1 e T2, anteriormente apresentadas,
analise o comando SQL a seguir.
select * from T1 full outer join T2 on T1.P=T2.P
Além da linha de títulos, a execução desse comando produz um resultado com:
select * from T1 full outer join T2 on T1.P=T2.P
Além da linha de títulos, a execução desse comando produz um resultado com:
Ano: 2024
Banca:
FGV
Órgão:
CGE-PB
Prova:
FGV - 2024 - CGE-PB - Auditor de Contas Públicas - Auditoria de Tecnologia da Informação |
Q2398330
Banco de Dados
Considerando as tabelas T1 e T2, anteriormente apresentadas,
analise o comando SQL a seguir.
delete from T2 where P not in (select P from T2)
O número de linhas deletadas da tabela T2 pela execução desse comando é:
delete from T2 where P not in (select P from T2)
O número de linhas deletadas da tabela T2 pela execução desse comando é:
Ano: 2024
Banca:
FGV
Órgão:
CGE-PB
Prova:
FGV - 2024 - CGE-PB - Auditor de Contas Públicas - Auditoria de Tecnologia da Informação |
Q2398329
Banco de Dados
À luz das tabelas T1 e T2, anteriormente apresentadas, analise o
comando SQL exibido a seguir.
select case when exists (select * from T2 where T2.E = 2 and T2.P = 3 and exists (select * from T1 where T1.P in (2,3,4) and T2.E in (2,3))) then 1 else 0 end flag
Sobre uma eventual execução desse script, é correto afirmar que:
select case when exists (select * from T2 where T2.E = 2 and T2.P = 3 and exists (select * from T1 where T1.P in (2,3,4) and T2.E in (2,3))) then 1 else 0 end flag
Sobre uma eventual execução desse script, é correto afirmar que:
Ano: 2024
Banca:
FGV
Órgão:
CGE-PB
Prova:
FGV - 2024 - CGE-PB - Auditor de Contas Públicas - Auditoria de Tecnologia da Informação |
Q2398316
Banco de Dados
Maria está implementando o Audit-DataMart para apoiar análises sobre a quantidade de auditorias realizadas por cidade e por período. Para isso, Maria elaborou o modelo multidimensional de dados no qual a dimensão tempo se relaciona com a tabela fato duas vezes, uma representando a data de início da auditoria e a outra representando a data do fim da auditoria, conforme ilustrado a seguir.
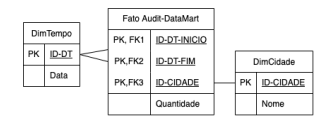
A técnica de modelagem multidimensional de dados utilizada por
Maria para referenciar múltiplas vezes uma única dimensão física
na tabela fato é:
Ano: 2024
Banca:
FGV
Órgão:
CGE-PB
Prova:
FGV - 2024 - CGE-PB - Auditor de Contas Públicas - Auditoria de Tecnologia da Informação |
Q2398315
Banco de Dados
No contexto de pré-processamento de dados, o auditor de contas
públicas João está trabalhando em um projeto de análise de
dados e percebe que as variáveis numéricas no conjunto de
dados têm escalas muito diferentes, como a escala dos preços
sendo maior do que a escala dos pesos, como demonstrado nos
produtos A e B:
• Produto A (Preço: R$ 50 e Peso: 300g) • Produto B (Preço: R$ 500 e Peso: 1000g)
Além disso, ele observa a presença de outliers nos dados. Nesse sentido, João deverá tratar os dados para garantir que as variáveis tenham uma distribuição normal, isto é, com média igual a zero e desvio padrão igual a um.
Para isso, a técnica de tratamento de dados que João deverá utilizar, levando em consideração a presença de outliers, é:
• Produto A (Preço: R$ 50 e Peso: 300g) • Produto B (Preço: R$ 500 e Peso: 1000g)
Além disso, ele observa a presença de outliers nos dados. Nesse sentido, João deverá tratar os dados para garantir que as variáveis tenham uma distribuição normal, isto é, com média igual a zero e desvio padrão igual a um.
Para isso, a técnica de tratamento de dados que João deverá utilizar, levando em consideração a presença de outliers, é:
Ano: 2024
Banca:
FGV
Órgão:
CGE-PB
Prova:
FGV - 2024 - CGE-PB - Auditor de Contas Públicas - Auditoria de Tecnologia da Informação |
Q2398311
Banco de Dados
No contexto de Qualidade de Dados, o auditor de contas públicas
João deverá analisar a consistência dos dados da base de dados
AUD_CONTAS identificando variações sobre os valores dos
atributos, como:
• 30% das entradas de dados na coluna CD_FUNCIONARIO estão marcadas com o caractere “espaço”
• existem 200 linhas na tabela TBL_PROCESSO contendo dados sobre processos sem nenhuma linha contendo os seus detalhes
Para isso, a técnica de diagnóstico sobre a qualidade de dados que João deverá utilizar é:
• 30% das entradas de dados na coluna CD_FUNCIONARIO estão marcadas com o caractere “espaço”
• existem 200 linhas na tabela TBL_PROCESSO contendo dados sobre processos sem nenhuma linha contendo os seus detalhes
Para isso, a técnica de diagnóstico sobre a qualidade de dados que João deverá utilizar é:
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387578
Banco de Dados
Considerando os conceitos principais de ciência de dados, analise
as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a
falsa.
( ) Em um sistema BigData, o pipeline de dados implementa as etapas necessárias para mover dados de sistemas de origem, transformar esses dados com base nos requisitos e armazenar os dados em um sistema de destino, incluindo todos os processos necessários para transformar dados brutos em dados preparados que os usuários podem consumir.
( ) Dentre os métodos de manipulação de valores ausentes, em processamento massivo e paralelo, consta a normalização numérica, que se refere ao processo de ajustar os dados para que estejam em uma escala comparável, geralmente entre 0 e 1.
( ) A demanda crescente por medidas de criptografia ponta a ponta (da produção ao backup) tornam menos eficazes e relevantes tecnologias legadas, como a deduplicação de dados (data deduplication), que busca ajudar a otimizar o armazenamento e melhorar o desempenho de um sistema ao estabelecer processo de identificar e eliminar dados duplicados em um sistema.
As afirmativas são, respectivamente,
( ) Em um sistema BigData, o pipeline de dados implementa as etapas necessárias para mover dados de sistemas de origem, transformar esses dados com base nos requisitos e armazenar os dados em um sistema de destino, incluindo todos os processos necessários para transformar dados brutos em dados preparados que os usuários podem consumir.
( ) Dentre os métodos de manipulação de valores ausentes, em processamento massivo e paralelo, consta a normalização numérica, que se refere ao processo de ajustar os dados para que estejam em uma escala comparável, geralmente entre 0 e 1.
( ) A demanda crescente por medidas de criptografia ponta a ponta (da produção ao backup) tornam menos eficazes e relevantes tecnologias legadas, como a deduplicação de dados (data deduplication), que busca ajudar a otimizar o armazenamento e melhorar o desempenho de um sistema ao estabelecer processo de identificar e eliminar dados duplicados em um sistema.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387577
Banco de Dados
Com relação às tecnologias relacionadas à ciência de dados,
analise as afirmativas a seguir e assinale (V) para a verdadeira e
(F) para a falsa.
( ) Os dashboards gerados no Power BI, da Microsoft, empregando scripts do R, são gerados empregando ‘tecnologia de área restrita’ para proteger os usuários e o serviço contra riscos de segurança.
( ) Na Ciência de Dados, os dados estruturados, semiestruturados e não estruturados podem ser digeridos por redes neurais recorrentes (RNN, Recurrent Neural Network), que processavam sequências inteiras em paralelo, ou por grandes modelos de linguagem (LLM, Large Language Models), que empregam processamento sequencial das entradas.
( ) No aprendizado de máquina é usual o emprego de Métodos de Reamostragem, como: k-fold (que fatia os dados em k pedaços iguais), repeated k-fold (que repete o método k-fold várias vezes), PCA (Principal Components Analysis, que reduz a quantidade de variáveis) e bootstrap (que reduz os desvios e realizar amostragem dos dados de treino com repetições).
As afirmativas são, respectivamente,
( ) Os dashboards gerados no Power BI, da Microsoft, empregando scripts do R, são gerados empregando ‘tecnologia de área restrita’ para proteger os usuários e o serviço contra riscos de segurança.
( ) Na Ciência de Dados, os dados estruturados, semiestruturados e não estruturados podem ser digeridos por redes neurais recorrentes (RNN, Recurrent Neural Network), que processavam sequências inteiras em paralelo, ou por grandes modelos de linguagem (LLM, Large Language Models), que empregam processamento sequencial das entradas.
( ) No aprendizado de máquina é usual o emprego de Métodos de Reamostragem, como: k-fold (que fatia os dados em k pedaços iguais), repeated k-fold (que repete o método k-fold várias vezes), PCA (Principal Components Analysis, que reduz a quantidade de variáveis) e bootstrap (que reduz os desvios e realizar amostragem dos dados de treino com repetições).
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387576
Banco de Dados
Com relação às tecnologias referentes a bancos de dados, analise
as afirmativas a seguir.
I. As consultas abaixo representam condições inconsistentes, pois sempre retornam resultados inválidos, independentemente do estado do banco, por apresentarem erros semânticos no esquema (SQL_01) e na consulta (SQL_02), respectivamente.

II. Dependendo da complexidade da consulta e do grau de normalização dos dados, o Banco de Dados NoSQL não deve substituir a escolha de um banco de dados relacionais, pois o BD NoSQL funciona adequadamente com consultas em uma única tabela e normalmente não oferece junções complexas, subconsultas e aninhamento de consultas em uma cláusula WHERE.
III. Análise de dados complexos podem ser realizados usando cubos de dados OLAP (On-line Analytical Processing) digerindo dados obtidos diretamente por ETL. (Extraction – Tranformation – Load), sendo o resultado do processamento armazenado no DW (Data Warehouse) ou DM (Data Mart).
Está correto o que se afirma em
I. As consultas abaixo representam condições inconsistentes, pois sempre retornam resultados inválidos, independentemente do estado do banco, por apresentarem erros semânticos no esquema (SQL_01) e na consulta (SQL_02), respectivamente.
II. Dependendo da complexidade da consulta e do grau de normalização dos dados, o Banco de Dados NoSQL não deve substituir a escolha de um banco de dados relacionais, pois o BD NoSQL funciona adequadamente com consultas em uma única tabela e normalmente não oferece junções complexas, subconsultas e aninhamento de consultas em uma cláusula WHERE.
III. Análise de dados complexos podem ser realizados usando cubos de dados OLAP (On-line Analytical Processing) digerindo dados obtidos diretamente por ETL. (Extraction – Tranformation – Load), sendo o resultado do processamento armazenado no DW (Data Warehouse) ou DM (Data Mart).
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387574
Banco de Dados
A lei de Benford, usada na área de qualidade de dados, descreve
a distribuição de frequência relativa para os dígitos iniciais de
números em grandes conjuntos de dados.
A distribuição P de Benford para d dígitos é descrita como
A distribuição P de Benford para d dígitos é descrita como
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387571
Banco de Dados
A arquitetura medalhão é um exemplo de data lakes. Ela é
multicamadas, sendo considerada uma ótima opção para data
warehouses, data marts e outros sistemas analíticos.
Sobre o tema, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Este padrão arquitetônico é composto por três camadas, Ouro, Platina e Diamante. A camada Ouro é onde estão armazenados os dados brutos, previamente ingeridos dos sistemas externos de origem. Os dados desta camada são normalmente são recebidos “no estado em que se encontram”, mas podem ser enriquecidos com metadados adicionais, como por exemplo, data de carregamento.
( ) Na camada Platina, os dados da camada anterior são filtrados, limpos, normalizados e mesclados com outros dados. Nesta camada há visão empresarial dos dados nas diferentes áreas temáticas e principais entidades de negócios, conceitos e transações.
( ) Os dados na camada Diamante são dados “prontos para consumo”. Esses dados enriquecidos e curados podem estar no formato de um esquema em estrela clássico, contendo dimensões e tabelas de fatos, ou podem estar em qualquer modelo de dados adequado ao caso de uso de consumo.
As afirmativas são, respectivamente,
Sobre o tema, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Este padrão arquitetônico é composto por três camadas, Ouro, Platina e Diamante. A camada Ouro é onde estão armazenados os dados brutos, previamente ingeridos dos sistemas externos de origem. Os dados desta camada são normalmente são recebidos “no estado em que se encontram”, mas podem ser enriquecidos com metadados adicionais, como por exemplo, data de carregamento.
( ) Na camada Platina, os dados da camada anterior são filtrados, limpos, normalizados e mesclados com outros dados. Nesta camada há visão empresarial dos dados nas diferentes áreas temáticas e principais entidades de negócios, conceitos e transações.
( ) Os dados na camada Diamante são dados “prontos para consumo”. Esses dados enriquecidos e curados podem estar no formato de um esquema em estrela clássico, contendo dimensões e tabelas de fatos, ou podem estar em qualquer modelo de dados adequado ao caso de uso de consumo.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387570
Banco de Dados
O modelo multidimensional é composto por diversos elementos,
por exemplo, dimensões, chaves, medidas e tabelas de fatos.
As tabelas de fatos podem ser do tipo
As tabelas de fatos podem ser do tipo
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387569
Banco de Dados
Considerando as propriedades dos bancos de dados NoSQL do
tipo orientados a documentos, analise as afirmativas a seguir.
I. No primeiro nível, os documentos possuem estrutura interna própria, porém o termo documento é totalmente apropriado uma vez que, explicitamente, não podem ser arquivos multimídia ou outros tipos não estruturados. No segundo nível, documentos são armazenados em uma espécie de chave-valor. Para cada chave (ID do documento), um registro pode ser armazenado como valor, sendo que esses registros são chamados de documentos.
II. Os documentos armazenados são completamente livres de esquemas, ou seja, não há necessidade de definir um esquema antes de inserir estruturas de dados. A responsabilidade é, portanto, transferida ao usuário ou ao aplicativo de processamento.
III. Os documentos contêm estruturas de dados na forma de pares atributo-valor recursivamente aninhados sem integridade referencial; essas estruturas de dados são livres de esquema, ou seja, atributos arbitrários podem ser usados em cada documento sem definir primeiro um esquema.
Está correto o que se afirma em
I. No primeiro nível, os documentos possuem estrutura interna própria, porém o termo documento é totalmente apropriado uma vez que, explicitamente, não podem ser arquivos multimídia ou outros tipos não estruturados. No segundo nível, documentos são armazenados em uma espécie de chave-valor. Para cada chave (ID do documento), um registro pode ser armazenado como valor, sendo que esses registros são chamados de documentos.
II. Os documentos armazenados são completamente livres de esquemas, ou seja, não há necessidade de definir um esquema antes de inserir estruturas de dados. A responsabilidade é, portanto, transferida ao usuário ou ao aplicativo de processamento.
III. Os documentos contêm estruturas de dados na forma de pares atributo-valor recursivamente aninhados sem integridade referencial; essas estruturas de dados são livres de esquema, ou seja, atributos arbitrários podem ser usados em cada documento sem definir primeiro um esquema.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387568
Banco de Dados
Atualmente, existem vários modelos arquiteturais de data
warehousing, comumente chamados de arquiteturas de
n camadas. As mais comuns são as arquiteturas de duas e três
camadas.
Com relação ao modelo arquitetural de três camadas, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) O servidor que executa o sistema operacional e o banco de dados é a terceira camada, que mantém os dados e demais softwares.
( ) O data warehouse é uma segunda camada; trata-se de um front-end cujo software de ETL computam os dados e metadados de sistemas legados e de fontes externas, consolidando, resumindo e carregando-os no servidor de banco de dados operacional.
( ) A primeira camada inclui todos os softwares do cliente, os mecanismos do business intelligence, sistemas de suporte a decisão e business analytics do back-end; ela permite que os analistas, por meio de processamento OLAP, analisem os dados históricos consolidados nos data warehouses ou data lakes.
As afirmativas são, respectivamente,
Com relação ao modelo arquitetural de três camadas, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) O servidor que executa o sistema operacional e o banco de dados é a terceira camada, que mantém os dados e demais softwares.
( ) O data warehouse é uma segunda camada; trata-se de um front-end cujo software de ETL computam os dados e metadados de sistemas legados e de fontes externas, consolidando, resumindo e carregando-os no servidor de banco de dados operacional.
( ) A primeira camada inclui todos os softwares do cliente, os mecanismos do business intelligence, sistemas de suporte a decisão e business analytics do back-end; ela permite que os analistas, por meio de processamento OLAP, analisem os dados históricos consolidados nos data warehouses ou data lakes.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387567
Banco de Dados
Considere as propriedades dos bancos de dados NoSQL do tipo
orientado a grafos, e assinale (V) para a afirmativa verdadeira e
(F) para a falsa.
( ) As manipulações de dados são expressas como transformações em grafos ou operações que abordam diretamente propriedades típicas de grafos (por exemplo, caminhos, adjacência, subgrafos e conexões).
( ) Este tipo de banco de dados não suporta a verificação de restrições de integridade para garantir a consistência dos dados. A definição de consistência está diretamente relacionada às estruturas do grafo (por exemplo, nós, tipos de arestas, domínios de atributos e integridade referencial das arestas).
( ) Diferentemente dos bancos de dados relacionais e dos NoSQL do tipo chave-valor, os bancos de dados orientados a grafos não precisam de índices para garantir um acesso rápido e direto aos nós e as arestas.
As afirmativas são, respectivamente,
( ) As manipulações de dados são expressas como transformações em grafos ou operações que abordam diretamente propriedades típicas de grafos (por exemplo, caminhos, adjacência, subgrafos e conexões).
( ) Este tipo de banco de dados não suporta a verificação de restrições de integridade para garantir a consistência dos dados. A definição de consistência está diretamente relacionada às estruturas do grafo (por exemplo, nós, tipos de arestas, domínios de atributos e integridade referencial das arestas).
( ) Diferentemente dos bancos de dados relacionais e dos NoSQL do tipo chave-valor, os bancos de dados orientados a grafos não precisam de índices para garantir um acesso rápido e direto aos nós e as arestas.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387565
Banco de Dados
Um trigger assemelha-se a um procedimento armazenado que é
invocado automaticamente, sempre que ocorre um evento
previamente especificado.
Sobre os diversos tipos de triggers no PL/SQL do SGBD Oracle, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Se o trigger for criado em uma tabela ou visão, o evento de gatilho será composto de instruções SQL do tipo DDL e será chamado de trigger de transição cruzada.
( ) Um trigger condicional pode ser um trigger do tipo DML ou de sistema que possui uma cláusula WHEN que especifica uma condição SQL que avalia para cada linha afetada pelas instruções presentes no trigger.
( ) Quando um trigger é acionado, as tabelas às quais ele faz referência podem estar passando por alterações feitas por instruções SQL nas transações iniciadas por outros usuários. As instruções SQL executadas com prioridade em relação as instruções SQL independentes.
As afirmativas são, respectivamente,
Sobre os diversos tipos de triggers no PL/SQL do SGBD Oracle, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Se o trigger for criado em uma tabela ou visão, o evento de gatilho será composto de instruções SQL do tipo DDL e será chamado de trigger de transição cruzada.
( ) Um trigger condicional pode ser um trigger do tipo DML ou de sistema que possui uma cláusula WHEN que especifica uma condição SQL que avalia para cada linha afetada pelas instruções presentes no trigger.
( ) Quando um trigger é acionado, as tabelas às quais ele faz referência podem estar passando por alterações feitas por instruções SQL nas transações iniciadas por outros usuários. As instruções SQL executadas com prioridade em relação as instruções SQL independentes.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387564
Banco de Dados
Uma junção é uma consulta SQL que combina linhas de duas ou
mais tabelas, visões ou visões materializadas.
Com relação aos tipos de junção suportadas pelo Oracle, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Uma semi-junção é uma junção de uma tabela a si mesma. Esta tabela aparece duas vezes na FROM cláusula e é seguida por aliases de tabela que qualificam os nomes das colunas na condição de junção. Para realizar uma semi-junção, o Oracle Database combina e retorna linhas da tabela que satisfazem a condição de junção.
( ) Uma junção interna estende o resultado de uma junção simples. Essa junção retorna todas as linhas que satisfazem a condição de junção e retorna algumas ou todas as linhas de uma tabela para as quais nenhuma linha da outra satisfaz a condição de junção.
( ) Uma anti-junção retorna linhas do lado esquerdo do predicado para as quais não há linhas correspondentes no lado direito do predicado. Ou seja, ele retorna linhas que não correspondem (NOT IN) à subconsulta do lado direito.
As afirmativas são, respectivamente,
Com relação aos tipos de junção suportadas pelo Oracle, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Uma semi-junção é uma junção de uma tabela a si mesma. Esta tabela aparece duas vezes na FROM cláusula e é seguida por aliases de tabela que qualificam os nomes das colunas na condição de junção. Para realizar uma semi-junção, o Oracle Database combina e retorna linhas da tabela que satisfazem a condição de junção.
( ) Uma junção interna estende o resultado de uma junção simples. Essa junção retorna todas as linhas que satisfazem a condição de junção e retorna algumas ou todas as linhas de uma tabela para as quais nenhuma linha da outra satisfaz a condição de junção.
( ) Uma anti-junção retorna linhas do lado esquerdo do predicado para as quais não há linhas correspondentes no lado direito do predicado. Ou seja, ele retorna linhas que não correspondem (NOT IN) à subconsulta do lado direito.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
CGM de Belo Horizonte - MG
Prova:
FGV - 2024 - CGM de Belo Horizonte - MG - Auditor Interno - Ciência da Computação - Manhã |
Q2387563
Banco de Dados
Analise o código abaixo descrito em PL/SQL do Oracle.

O conteúdo impresso é
O conteúdo impresso é