Foram encontradas 1.519 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Sejam X e Y variáveis aleatórias do tipo Bernoulli, assumindo valores x1, x2, y1 e y2 respectivamente. Também é sabido que P(X = x1 / Y = y2 ) = 0,60 e P(Y =y1 )= 0,75.
Então:
Sejam X e Y duas variáveis aleatórias com variâncias iguais a 21 e 17, respectivamente. Além disso, sabe-se que a variável Z representada pela diferença entre as duas tem variância igual a 44.
Com base em tais informações, é correto deduzir que:
Para uma distribuição de frequências apenas parcialmente conhecida são fornecidas as seguintes estatísticas,
Mo(X)= 19 , E(X2) = 625 e Me(X) = 22
sendo Mo, a moda e Me, a mediana dos dados. Sabe-se ainda que a distribuição é unimodal.
Esse conjunto bem restrito de informações seria compatível apenas com:
Alguns economistas estão discutindo sobre a volatilidade dos preços em duas economias, relativamente parecidas, tendo como moedas peras (A) e maçãs (B). Sabe-se que as médias dos preços são 100 peras e 120 maçãs, respectivamente. É fornecido, ainda, o desvio-padrão dos preços em A, igual a 25 peras, e a variância em B, igual a 400 maçãs ao quadrado.
Considerando as principais medidas estatísticas de dispersão como medidas de volatilidade, é correto afirmar que:
A figura abaixo apresenta um diagrama do tipo Box-Plot de uma amostra que, além de estatísticas de referência próprias da sua construção, assinala quatro elementos X1, X2, X3 e X4.
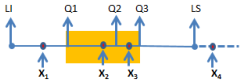
onde os Qi,s são os quartis e LI e LS são os limites inferior e superior do Box-Plot.
Sobre esses valores e/ou a sua distribuição, é correto afirmar
que:
A ideia de grupar as observações de uma população ou amostra constitui uma técnica bem antiga de condensar as informações e assim facilitar o seu tratamento. No passado essa técnica era empregada com sucesso, mas com a ressalva de que os resultados não eram tão precisos quanto aqueles obtidos com dados não grupados.
Considere a distribuição expressa em classes de frequências:
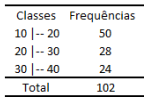
Mesmo sem dispor dos dados de forma desagregada, sobre as
estatísticas exatas, é correto afirmar que:
Uma vez concluída a etapa de críticas de dados, relativa a um conjunto de registros obtido através de uma pesquisa de campo, inicia-se o trabalho de tabulação e elaboração de gráficos. Durante as análises, algumas variáveis surgem com destaque.
(i) número de indivíduos por faixa etária; (ii) percentuais do nível de escolaridade; e (iii) pares de valores de consumo e renda.
Portanto, os tipos de gráficos considerados adequados a serem empregados em cada caso são, respectivamente:
Para a realização de uma pesquisa de campo, uma amostra por conglomerados deverá ser extraída. São considerados como unidades da população os 27 estados brasileiros que, para essa finalidade estão classificados como mais (11 UFs) ou menos (16 UFs) desenvolvidos.
Supondo que a amostra será de n = 5, a probabilidade de que sejam sorteados dois mais desenvolvidos e três menos desenvolvidos é de:
A população de um estudo é dividida em quatro estratos, sendo o menor com 10% dos indivíduos e os demais com tamanhos acrescidos de dez pontos percentuais, progressivamente. Os estratos se distinguem por classes de renda com amplitude constante, sendo maiores quanto menor a renda.
Sobre os estratos sabe-se que:
RdEstrato1 = 65 RdEstrato2 = 45 e RdEstrato4 = 5
onde os valores acima representam os limites inferiores da renda dos extratos, inclusive.
Portanto, é correto afirmar que:
Uma amostra aleatória simples de tamanho n de uma distribuição
normal com média μ e variância σ2 será obtida. Se ܺ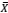 e S2 são a
média amostral e a variância amostral usuais, avalie se as
seguintes afirmativas estão corretas.
e S2 são a
média amostral e a variância amostral usuais, avalie se as
seguintes afirmativas estão corretas.
I. ܺ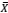 é um estimador não tendencioso de μ.
é um estimador não tendencioso de μ.
II. S2 é um estimador não tendencioso de σ2.
III. ܺ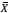 e S2 são independentes.
e S2 são independentes.
Está correto o que se afirma em
A probabilidade de que certo evento A ocorra é de 20%, a probabilidade de que o evento B ocorra é de 30% e a probabilidade de que A e B ocorram é de 10%.
Assim, a probabilidade de que nem A nem B ocorra é igual a
As amostras, quanto à forma de seleção, podem ser do tipo probabilístico ou não probabilístico. Como exemplos dessas últimas, podem ser citados os casos de amostras obtidas por cotas, por conveniência ou em bola de neve.
Sobre essas três modalidades, e nessa ordem, é correto afirmar que:
Um estatístico resolve realizar um levantamento de campo através de uma amostra por conglomerados, selecionando todos os indivíduos dos clusters previamente selecionados.
Sobre esse desenho amostral, é correto afirmar que:
Uma amostra deve ser selecionada de uma população com o objetivo de estimar a proporção de pessoas que apresentam uma determinada característica. Nas últimas três vezes que foi pesquisada, essa proporção ficou bem próxima de 40%, com intervalo de variação de 2%.
Nesses casos, para graus de confiança 68,26% (z = 1), 86,63% (z = 1,5) e 95,45% (z = 2), os tamanhos de amostras foram respectivamente:
A quantidade de dinheiro apreendido (DA) no combate à corrupção, pelo Ministério Público e a Polícia Federal, teve seu padrão de comportamento alterado com o início das operações Lava-Jato, Calicut, Ponto Final e outras. Um estatístico que vinha acompanhando essa variável através de um modelo teve que fazer alguns ajustes no seu trabalho, pensando até em incluir variáveis “dummies”, em especial depois de observar o seguinte gráfico de evolução:
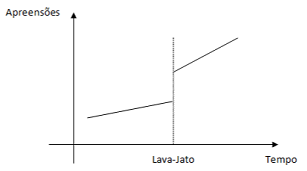
Considerando esse panorama, a nova formulação a ser adotada
pelo estatístico deve ser:
O volume de investigações conduzido pelo Ministério Público é uma variável de tempo que pode ser modelada como uma combinação de choques aleatórios. Essa série foi trabalhada por um estatístico, que chegou ao seguinte modelo estimado:
Zt = εt + 0,75 . εt -1 - 0,25.εt -2 + 30
onde Zt é o volume de investigações e εt é o termo de erro com as características usuais de média nula, normalidade, não correlacionados e variância constante (σ2 = 4).
De acordo com o padrão acima identificado, conclui-se que:
Em modelos de regressão múltipla, alguns pressupostos complementares são formulados para que os parâmetros possam ser estimados de forma satisfatória. Um deles trata da micronumerosidade e outro do tamanho da amostra.
Sobre essas duas adições, é correto afirmar que:
Sejam duas populações, cujas variáveis de interesse, X e Y, são distribuídas normalmente e independentes entre si. O objetivo é testar se há ou não diferença significativa entre as médias. As informações disponíveis são:
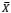 = 17, Ȳ= 25, σ 2/x= 160,σ 2/Y=225, nx = 16 e ny = 15
= 17, Ȳ= 25, σ 2/x= 160,σ 2/Y=225, nx = 16 e ny = 15
Ø(1,28) = 0,9 , Ø(1,64) = 0,95 e Ø(1,96) = 0,975
Onde Ø é a função distribuição acumulada da normal padrão.
Então: