Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 1.519 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2022
Banca:
FGV
Órgão:
SEFAZ-ES
Prova:
FGV - 2022 - SEFAZ-ES - Consultor do Tesouro Estadual - Ciências Econômicas e Ciências Contábeis - Manhã |
Q1956469
Estatística
Uma sociedade empresária produz pacotes de café moído e
torrado e afirma que os pesos dos pacotes seguem uma
distribuição normal com média µ = 700g e desvio-padrão σ = 10g.
A Secretaria da Fazenda recebeu uma denúncia de que há irregularidades no peso, principalmente em relação à variabilidade dos pesos em cada pacote. Em uma fiscalização, foram selecionados uma amostra aleatória simples de 10 pacotes de café para averiguar a denúncia.
A probabilidade de a variância amostral, s2 , dos pesos dos 10 pacotes selecionados ser maior do que 100g2 , é de, aproximadamente
A Secretaria da Fazenda recebeu uma denúncia de que há irregularidades no peso, principalmente em relação à variabilidade dos pesos em cada pacote. Em uma fiscalização, foram selecionados uma amostra aleatória simples de 10 pacotes de café para averiguar a denúncia.
A probabilidade de a variância amostral, s2 , dos pesos dos 10 pacotes selecionados ser maior do que 100g2 , é de, aproximadamente
Ano: 2022
Banca:
FGV
Órgão:
SEFAZ-ES
Prova:
FGV - 2022 - SEFAZ-ES - Consultor do Tesouro Estadual - Ciências Econômicas e Ciências Contábeis - Manhã |
Q1956468
Estatística
Um algoritmo está sendo desenvolvido para modelagem de séries
temporais e encontra-se em fase de testes. Nessa etapa, o
algoritmo funciona apenas para séries com média 60 e variância
100.
A série selecionada para o teste não atende à condição supra, pois possui média 66 e variância 144.
Para alterar linearmente a referida série, tornando-a apta a testar o algoritmo, é necessário que cada observação seja:
A série selecionada para o teste não atende à condição supra, pois possui média 66 e variância 144.
Para alterar linearmente a referida série, tornando-a apta a testar o algoritmo, é necessário que cada observação seja:
Ano: 2022
Banca:
FGV
Órgão:
SEFAZ-ES
Prova:
FGV - 2022 - SEFAZ-ES - Consultor do Tesouro Estadual - Ciências Econômicas e Ciências Contábeis - Manhã |
Q1956467
Estatística
Uma amostra aleatória simples de tamanho 4 de uma população
normalmente distribuída forneceu os seguintes dados:
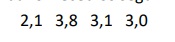
As estimativas de máxima verossimilhança da média e da variância populacionais são respectivamente
As estimativas de máxima verossimilhança da média e da variância populacionais são respectivamente
Ano: 2022
Banca:
FGV
Órgão:
SEFAZ-ES
Prova:
FGV - 2022 - SEFAZ-ES - Consultor do Tesouro Estadual - Ciências Econômicas e Ciências Contábeis - Manhã |
Q1956466
Estatística
Uma amostra aleatória simples X1, X2 ..., X225, de tamanho 225, de
uma população suposta normal com média e variância
desconhecidas forneceu os seguintes dados:
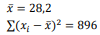
Lembre que se Z tem distribuição normal padrão então P[Z < 1,64] = 0,95, P[Z < 1,96] = 0,975.
Um intervalo de 95% de confiança para a média populacional será dado aproximadamente por
Lembre que se Z tem distribuição normal padrão então P[Z < 1,64] = 0,95, P[Z < 1,96] = 0,975.
Um intervalo de 95% de confiança para a média populacional será dado aproximadamente por
Ano: 2022
Banca:
FGV
Órgão:
SEFAZ-ES
Prova:
FGV - 2022 - SEFAZ-ES - Consultor do Tesouro Estadual - Ciências Econômicas e Ciências Contábeis - Manhã |
Q1956465
Estatística
Sabe-se que numa cidade muito populosa 60% das pessoas
adultas foram vacinadas contra a ação de um vírus.
Se uma amostra aleatória simples de 5 pessoas adultas dessa população for observada, a probabilidade de que mais de 3 tenham sido vacinadas é aproximadamente igual a
Se uma amostra aleatória simples de 5 pessoas adultas dessa população for observada, a probabilidade de que mais de 3 tenham sido vacinadas é aproximadamente igual a
Ano: 2022
Banca:
FGV
Órgão:
SEFAZ-ES
Prova:
FGV - 2022 - SEFAZ-ES - Consultor do Tesouro Estadual - Ciências Econômicas e Ciências Contábeis - Manhã |
Q1956464
Estatística
As notas de nove candidatos num certo exame foram:
54, 48, 46, 51, 38, 50, 44, 58, 32.
A mediana dessas notas é igual a
Ano: 2022
Banca:
FGV
Órgão:
SEFAZ-ES
Prova:
FGV - 2022 - SEFAZ-ES - Consultor do Tesouro Estadual - Ciências Econômicas e Ciências Contábeis - Manhã |
Q1956463
Estatística
As probabilidades de dois eventos A e B são P[A] = 0,5,
P[B] = 0,8. A probabilidade condicional de A ocorrer dado que B
ocorre é P[A|B] = 0,6.
Assim, a probabilidade de que A ou B ocorram é igual a
Assim, a probabilidade de que A ou B ocorram é igual a
Ano: 2022
Banca:
FGV
Órgão:
TJ-DFT
Prova:
FGV - 2022 - TJ-DFT - Analista Judiciário - Análise de Dados |
Q1936781
Estatística
Um analista é contratado para analisar dados de volume de suco
de laranja produzido em duas fábricas da mesma empresa.
Suponha que sejam medidos 16 lotes na fábrica A e 61 lotes na fábrica B, e que as médias amostrais tenham sido A_bar = 104 e B_bar = 112, com somas de desvios quadráticos em relação à média S^2_A = 40.000 e S^2_B = 100.000, respectivamente.
A chefia quer saber se uma fábrica tem menor variabilidade em relação à outra.
O teste a ser usado e o valor da sua estatística de teste são, respectivamente:
Suponha que sejam medidos 16 lotes na fábrica A e 61 lotes na fábrica B, e que as médias amostrais tenham sido A_bar = 104 e B_bar = 112, com somas de desvios quadráticos em relação à média S^2_A = 40.000 e S^2_B = 100.000, respectivamente.
A chefia quer saber se uma fábrica tem menor variabilidade em relação à outra.
O teste a ser usado e o valor da sua estatística de teste são, respectivamente:
Ano: 2022
Banca:
FGV
Órgão:
TJ-DFT
Prova:
FGV - 2022 - TJ-DFT - Analista Judiciário - Análise de Dados |
Q1936780
Estatística
Considere um conjunto de dados com n = 10 observações, cujas
nove primeiras observações são
7,6 4,1 8,8 4,2 5,1 7,4 8,8 5,9 3,1
Sabendo-se que a média amostral do conjunto completo é x_bar = 4,2, a amplitude dos dados é:
7,6 4,1 8,8 4,2 5,1 7,4 8,8 5,9 3,1
Sabendo-se que a média amostral do conjunto completo é x_bar = 4,2, a amplitude dos dados é:
Ano: 2022
Banca:
FGV
Órgão:
TJ-DFT
Prova:
FGV - 2022 - TJ-DFT - Analista Judiciário - Análise de Dados |
Q1936779
Estatística
A chance de um evento que ocorre com probabilidade p é
definida como c = p/(1-p).
Quando queremos entender a associação de um fator com um evento de interesse, em geral computamos a razão de chances, r = c_0/c_1, onde c_0 é a chance sem a exposição e c_1 é a chance com a exposição.
Suponha que um analista dispõe de um conjunto de dados binários Y = (Y_1,..., Y_n), com Y_i tomando valores em {0, 1} contendo o resultado de um teste de Covid-19 em n pacientes e que X = (X_1, ..., X_n) é um conjunto de covariáveis também binárias que indicam se o indivíduo foi (X_i = 1) ou não (X_i = 0) a uma festa nos últimos dez dias.
O analista quer determinar se a variável X está significativamente associada com o resultado do teste, Y.
Para tanto, ajusta um modelo de regressão logística utilizando Y como variável resposta, um termo de intercepto e X como covariável.
Ele obtém uma estimativa b0 para o intercepto, com erro padrão s0 e, para o coeficiente de X, uma estimativa b1 erro padrão s1.
O intervalo de confiança de 90% para a razão de chances é:
Quando queremos entender a associação de um fator com um evento de interesse, em geral computamos a razão de chances, r = c_0/c_1, onde c_0 é a chance sem a exposição e c_1 é a chance com a exposição.
Suponha que um analista dispõe de um conjunto de dados binários Y = (Y_1,..., Y_n), com Y_i tomando valores em {0, 1} contendo o resultado de um teste de Covid-19 em n pacientes e que X = (X_1, ..., X_n) é um conjunto de covariáveis também binárias que indicam se o indivíduo foi (X_i = 1) ou não (X_i = 0) a uma festa nos últimos dez dias.
O analista quer determinar se a variável X está significativamente associada com o resultado do teste, Y.
Para tanto, ajusta um modelo de regressão logística utilizando Y como variável resposta, um termo de intercepto e X como covariável.
Ele obtém uma estimativa b0 para o intercepto, com erro padrão s0 e, para o coeficiente de X, uma estimativa b1 erro padrão s1.
O intervalo de confiança de 90% para a razão de chances é:
Ano: 2022
Banca:
FGV
Órgão:
TJ-DFT
Prova:
FGV - 2022 - TJ-DFT - Analista Judiciário - Análise de Dados |
Q1936778
Estatística
Um analista obtém n = 10 estimativas
E = (E_1, E_2, ..., E_10) da quantidade X e deseja avaliar o estimador que as produziu.
Conhecendo o valor verdadeiro de X, ele computa o erro quadrático médio, cujo valor foi 64.
Já a soma das estimativas foi 1.000 e a soma de seus quadrados foi 5.100.
O valor absoluto do viés do estimador é:
E = (E_1, E_2, ..., E_10) da quantidade X e deseja avaliar o estimador que as produziu.
Conhecendo o valor verdadeiro de X, ele computa o erro quadrático médio, cujo valor foi 64.
Já a soma das estimativas foi 1.000 e a soma de seus quadrados foi 5.100.
O valor absoluto do viés do estimador é:
Ano: 2022
Banca:
FGV
Órgão:
SEFAZ-BA
Prova:
FGV - 2022 - SEFAZ-BA - Agente de Tributos Estaduais - Tecnologia da Informação |
Q1934395
Estatística
Considere as duas listas de números a seguir.
Lista 1: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
Lista 2: 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15
Sejam D1 e D2 os desvios padrão das Listas 1 e 2, respectivamente.
É correto concluir que
Q1933596
Estatística
No contexto da linguagem de programação R, analise as
afirmativas a seguir.
I. Vetores (vectors) são listas de itens que devem ter o mesmo tipo.
II. R trabalha com vários tipos de dados (data types), numéricos, lógicos e textuais, mas as variáveis podem mudar de tipo mesmo depois da instanciação.
III. Os itens de uma lista (list) não podem ser substituídos. São permitidas apenas a inserção e a remoção de itens.
Está correto somente o que se afirma em:
I. Vetores (vectors) são listas de itens que devem ter o mesmo tipo.
II. R trabalha com vários tipos de dados (data types), numéricos, lógicos e textuais, mas as variáveis podem mudar de tipo mesmo depois da instanciação.
III. Os itens de uma lista (list) não podem ser substituídos. São permitidas apenas a inserção e a remoção de itens.
Está correto somente o que se afirma em:
Q1933594
Estatística
No contexto da linguagem de programação R, analise o código a
seguir.
for (x in 1:10) { if (x >= 4) { print(x) next } if (x == 8) {break} }
O número de linhas exibidas pela execução desse código é:
for (x in 1:10) { if (x >= 4) { print(x) next } if (x == 8) {break} }
O número de linhas exibidas pela execução desse código é:
Q1933593
Estatística
Um problema comum no processamento de texto é o tratamento
de termos compostos por mais de um token, tais como
“Ministério Público”, tal que represente uma unidade linguística
distinta, em particular na construção de modelos de linguagem.
Considerando o problema acima descrito, a alternativa que apresenta uma técnica usada para sua resolução é:
Considerando o problema acima descrito, a alternativa que apresenta uma técnica usada para sua resolução é:
Q1933592
Estatística
O método Latent Dirichlet Allocation (LDA) é popularmente
utilizado para a construção de modelos de tópicos devido a sua
flexibilidade e robustez, particularmente em grandes quantidades
de texto. Ao mencionar a escolha do LDA em um projeto, um
analista foi questionado sobre que aspectos caracterizam a
flexibilidade do modelo, especialmente em comparação a um
modelo pLSA.
O analista respondeu corretamente:
O analista respondeu corretamente:
Q1933591
Estatística
Um modelo semântico vetorial foi criado com a seguinte
definição:
v(w)i = tf(w, di) ∙ idf(w, D)
onde v é o vetor correspondente à palavra w, di é o i-ésimo documento da coleção D de artigos da Wikipédia, ordenados alfabeticamente por título, e tf e idf são, respectivamente, as funções de frequência de termo e inverso da frequência em documentos.
A alternativa que classifica corretamente o modelo acima descrito e apresenta a razão correta para a classificação é:
v(w)i = tf(w, di) ∙ idf(w, D)
onde v é o vetor correspondente à palavra w, di é o i-ésimo documento da coleção D de artigos da Wikipédia, ordenados alfabeticamente por título, e tf e idf são, respectivamente, as funções de frequência de termo e inverso da frequência em documentos.
A alternativa que classifica corretamente o modelo acima descrito e apresenta a razão correta para a classificação é:
Q1933590
Estatística
A atividade de classificação de documentos envolve um grande
número de tarefas de processamento de linguagem natural, o
que pode levar a dúvidas quanto a sua aplicação.
A alternativa que contém apenas tarefas que sejam exemplos de classificação de documentos é:
A alternativa que contém apenas tarefas que sejam exemplos de classificação de documentos é:
Q1933589
Estatística
Para realizar o agrupamento de um conjunto de 4 observações
(A, B, C e D) foi decidido usar o método de agrupamento
hierárquico aglomerativo com ligação simples (single-linkage).
A matriz de distância inicial entre os elementos é apresentada a seguir.
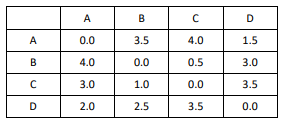
Considerando essas informações, a matriz de distância obtida após o primeiro passo do agrupamento é:
A matriz de distância inicial entre os elementos é apresentada a seguir.
Considerando essas informações, a matriz de distância obtida após o primeiro passo do agrupamento é:
Q1933586
Estatística
Uma biblioteca está classificando os seus frequentadores em
grupos literários para facilitar a aquisição e a organização dos
livros. Isso foi feito aplicando o algoritmo KNN ao banco de dados
de usuários da biblioteca, incluindo alguns dos campos de
informação como atributos, tais como idade e nível de formação
acadêmica. Em um experimento, uma segunda classificação foi
feita usando um conjunto maior de atributos, incluindo ambos de
maior ou menor relevância percebida com relação aos grupos
definidos.
A segunda classificação tende a ser:
A segunda classificação tende a ser: