Questões de Concurso Público TRE-MG 2013 para Analista Judiciário - Estatística
Foram encontradas 6 questões
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452928
Estatística
Considere que a variável aleatória X tenha distribuição Normal com média igual a 60 e variância igual a 9. Seja Z a variável aleatória Normal Padrão (Padronizada). É correto afirmar que
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452937
Estatística
Uma indústria mineradora produz minério de ferro e tem um contrato com uma siderúrgica, especificando que o teor médio de ferro nos lotes de minério entregue a ela deve ser de, no mínimo, 60%. Caso contrário, os lotes são devolvidos e a mineradora deve pagar uma multa. Para certificar-se de que está enviando minério de ferro dentro do que foi especificado no contrato, a mineradora toma amostras de minério de cada lote a ser embarcado. Em seguida, determina o teor médio de ferro do minério de cada lote. A mineradora gostaria que a probabilidade de concluir o lote a ser enviado cumprisse as especificações estabelecidas pela siderúrgica quando, na verdade, não as cumpre, seja, no máximo, 0,025. Considere as quatro hipóteses a seguir:
Hipótese 1: o teor médio de minério de ferro do lote é maior do que 60%.
Hipótese 2: o teor médio de minério de ferro do lote é maior ou igual a 60%.
Hipótese 3: o teor médio de minério de ferro do lote é menor do que 60%.
Hipótese 4: o teor médio de minério de ferro do lote é menor ou igual a 60%.
Considerando as informações apresentadas, as hipóteses nulas e a alternativa do teste a ser realizada antes do embarque do lote são, respectivamente, as hipóteses
Hipótese 1: o teor médio de minério de ferro do lote é maior do que 60%.
Hipótese 2: o teor médio de minério de ferro do lote é maior ou igual a 60%.
Hipótese 3: o teor médio de minério de ferro do lote é menor do que 60%.
Hipótese 4: o teor médio de minério de ferro do lote é menor ou igual a 60%.
Considerando as informações apresentadas, as hipóteses nulas e a alternativa do teste a ser realizada antes do embarque do lote são, respectivamente, as hipóteses
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452947
Estatística
Marque V para as afirmativas verdadeiras e F para as falsas.
( ) Para ajustar um modelo ARIMA, é necessário considerar os estágios de identificação e estimação.
( ) Um processo autorregressivo de ordem p tem a função de autocovariância decrescente, na forma de exponenciais ou senoides amortecidas, finitas em extensão.
( ) Um processo de médias móveis de ordem q tem função de autocovariância finita, apresentando um corte após o “lag” q.
( ) Um processo autorregressivo e de médias móveis de ordem (p, q) tem função de autocovariância infinita em extensão, que decai de acordo com exponenciais e/ou senoides amortecidas após o “lag” q-p.
( ) Após a identificação provisória de um modelo de séries temporais, pode-se usar os métodos de mínimos quadrados ou de máxima verossimilhança, entre outros, para estimação dos parâmetros. Os estimadores obtidos pelo método dos momentos não têm propriedades boas quando comparadas com os dois já mencionados. Entretanto, podem ser utilizados para gerar os valores iniciais nos processos iterativos.
A sequência está correta em
( ) Para ajustar um modelo ARIMA, é necessário considerar os estágios de identificação e estimação.
( ) Um processo autorregressivo de ordem p tem a função de autocovariância decrescente, na forma de exponenciais ou senoides amortecidas, finitas em extensão.
( ) Um processo de médias móveis de ordem q tem função de autocovariância finita, apresentando um corte após o “lag” q.
( ) Um processo autorregressivo e de médias móveis de ordem (p, q) tem função de autocovariância infinita em extensão, que decai de acordo com exponenciais e/ou senoides amortecidas após o “lag” q-p.
( ) Após a identificação provisória de um modelo de séries temporais, pode-se usar os métodos de mínimos quadrados ou de máxima verossimilhança, entre outros, para estimação dos parâmetros. Os estimadores obtidos pelo método dos momentos não têm propriedades boas quando comparadas com os dois já mencionados. Entretanto, podem ser utilizados para gerar os valores iniciais nos processos iterativos.
A sequência está correta em
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452953
Estatística
Os Modelos Lineares Generalizados (MLG) são definidos a partir de três características: o componente aleatório, que estabelece a distribuição da variável resposta; o componente sistemático, que determina as variáveis explicativas a serem utilizadas como preditoras no modelo e estabelece a equação de predição como linear; e, a função de ligação, que estabelece a relação entre o componente sistemático e a esperança matemática da variável resposta. Diante do exposto, analise.
I. O componente aleatório permite que a distribuição seja da família exponencial ou de suas generalizações, contemplando, entre outras, as distribuições: normal, Bernoulli, Poisson, Gama, Normal, Inversa, Exponencial, Binomial.
II. A função de ligação deve transformar o domínio da variável aleatória de forma a permitir que qualquer valor do componente sistemático seja admissível. As funções mais utilizadas são: identidade, inversa, inversa ao quadrado, logarítmica, logito, probito, complemento log-log, potência, Box-Cox e Aranda-Ordaz.
III. O ajuste de um MLG pode ser feito pelo método de máxima verossimilhança. As equações normais produzidas, em geral, precisam ser resolvidas por processos iterativos. Os mais utilizados são o método de Newton- Raphson e o de escore de Fisher. Eles são distintos, qualquer que seja a função de ligação.
IV. Para dados de contagem com distribuição de Poisson, o MLG corresponde ao modelo de regressão de Poisson. A função de ligação mais utilizada é a logarítmica. Quando existe superdispersão nos dados, adota-se uma generalização de MLG que admite o parâmetro de dispersão.
V. Vários tipos de resíduo podem ser utilizados para avaliar a qualidade do ajuste de um MLG, entre eles, resíduos ordinários, resíduos de Pearson, resíduos de Pearson padronizados e componente do desvio.
Estão corretas apenas as afirmativas
I. O componente aleatório permite que a distribuição seja da família exponencial ou de suas generalizações, contemplando, entre outras, as distribuições: normal, Bernoulli, Poisson, Gama, Normal, Inversa, Exponencial, Binomial.
II. A função de ligação deve transformar o domínio da variável aleatória de forma a permitir que qualquer valor do componente sistemático seja admissível. As funções mais utilizadas são: identidade, inversa, inversa ao quadrado, logarítmica, logito, probito, complemento log-log, potência, Box-Cox e Aranda-Ordaz.
III. O ajuste de um MLG pode ser feito pelo método de máxima verossimilhança. As equações normais produzidas, em geral, precisam ser resolvidas por processos iterativos. Os mais utilizados são o método de Newton- Raphson e o de escore de Fisher. Eles são distintos, qualquer que seja a função de ligação.
IV. Para dados de contagem com distribuição de Poisson, o MLG corresponde ao modelo de regressão de Poisson. A função de ligação mais utilizada é a logarítmica. Quando existe superdispersão nos dados, adota-se uma generalização de MLG que admite o parâmetro de dispersão.
V. Vários tipos de resíduo podem ser utilizados para avaliar a qualidade do ajuste de um MLG, entre eles, resíduos ordinários, resíduos de Pearson, resíduos de Pearson padronizados e componente do desvio.
Estão corretas apenas as afirmativas
Ano: 2013
Banca:
CONSULPLAN
Órgão:
TRE-MG
Prova:
CONSULPLAN - 2013 - TRE-MG - Analista Judiciário - Estatística |
Q452954
Estatística
O modelo de regressão logística é um caso particular de um modelo linear generalizado em que o componente aleatório tem distribuição Bernoulli e a função de ligação é a logito. Diante do exposto, marque V para as afirmativas verdadeiras e F para as falsas.
( ) Para uma variável explicativa numérica, o modelo logístico tem uma forma linear para o logito da probabilidade: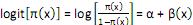 , ou seja, p(x) aumenta ou diminui como uma função linear de x.
, ou seja, p(x) aumenta ou diminui como uma função linear de x.
( ) A chance ou odds é a razão entre as probabilidades de sucesso e fracasso e pode ser expressa como eα (eß ) x . Quando a variável explicativa aumenta em uma unidade, a chance é aumentada multiplicativamente por ß.
( ) Para a avaliação do modelo de regressão com variáveis explicativas numéricas pode-se utilizar a estatística X2 de Pearson ou a estatística G2 do teste da razão de verossimilhança dadas, respectivamente, por:

( ) Para a análise de resíduos de um modelo de regressão logística com variáveis explicativas numéricas pode-se utilizar o resíduo de Pearson ou o resíduo ajustado de Pearson, dados, respectivamente, por:
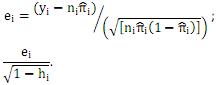
( ) O modelo de regressão logística multicategorizada é uma generalização do modelo de regressão logística, onde a variável resposta assume mais de duas categorias. Quando as categorias são nominais, escolhe-se uma como sendo a base para se construir as chances e fazer as análises necessárias. No caso de categorias ordinais, a ordenação pode ser incorporada ao modelo na forma de probabilidades acumuladas, obtendo-se, então, o modelo logito acumulativo.
A sequência está correta em
( ) Para uma variável explicativa numérica, o modelo logístico tem uma forma linear para o logito da probabilidade:
, ou seja, p(x) aumenta ou diminui como uma função linear de x. ( ) A chance ou odds é a razão entre as probabilidades de sucesso e fracasso e pode ser expressa como eα (eß ) x . Quando a variável explicativa aumenta em uma unidade, a chance é aumentada multiplicativamente por ß.
( ) Para a avaliação do modelo de regressão com variáveis explicativas numéricas pode-se utilizar a estatística X2 de Pearson ou a estatística G2 do teste da razão de verossimilhança dadas, respectivamente, por:
( ) Para a análise de resíduos de um modelo de regressão logística com variáveis explicativas numéricas pode-se utilizar o resíduo de Pearson ou o resíduo ajustado de Pearson, dados, respectivamente, por:
( ) O modelo de regressão logística multicategorizada é uma generalização do modelo de regressão logística, onde a variável resposta assume mais de duas categorias. Quando as categorias são nominais, escolhe-se uma como sendo a base para se construir as chances e fazer as análises necessárias. No caso de categorias ordinais, a ordenação pode ser incorporada ao modelo na forma de probabilidades acumuladas, obtendo-se, então, o modelo logito acumulativo.
A sequência está correta em