Questões de Concurso Público Petrobras 2022 para Ciência de Dados
Foram encontradas 13 questões
Em um processo em que se utiliza a ciência de dados, o número de variáveis necessárias para a realização da investigação de um fenômeno é direta e simplesmente igual ao número de variáveis utilizadas para mensurar as respectivas características desejadas; entretanto, é diferente o procedimento para determinar o número de variáveis explicativas, cujos dados estejam em escalas qualitativas.
Considerando esse aspecto dos modelos de regressão, julgue o item a seguir.
Para evitar um erro de ponderação arbitrária, deve-se
recorrer ao artifício de uso de variáveis dummy, o que
permitirá a estratificação da amostra da maneira que for
definido um determinado critério, evento ou atributo, para
então serem inseridas no modelo em análise; isso permitirá o
estudo da relação entre o comportamento de determinada
variável explicativa qualitativa e o fenômeno em questão,
representado pela variável dependente.
Uma árvore de decisão representa um determinado número de caminhos possíveis de decisão e os resultados de cada um deles, apresentando muitos pontos positivos, ou seja, são fáceis de entender e interpretar. Elas têm processo de previsão completamente transparente e lidam facilmente com diversos atributos numéricos, assim como atributos categóricos, podendo até mesmo classificar dados sem atributos definidos.
De acordo com os aspectos construtivos de uma árvore de decisão, julgue o item a seguir.
Se o processo adotado para a construção de árvores de
decisão for determinístico, uma forma de obtenção de
árvores aleatórias, que compõem as florestas aleatórias, pode
ser realizada por meio do bootstrap dos dados, em que cada
árvore é treinada com base no resultado de bootstrap_sample
(inputs).
O ensemble denominado bagging tem como foco principal a redução do viés e não da variância, treinando-se os modelos em sequência, tal que os erros dos primeiros modelos treinados são utilizados para o ajuste nos pesos matemáticos dos próximos modelos.
Os hiperparâmetros de um modelo são todos os parâmetros que podem ser definidos antes do inicio do treinamento, diferentemente dos parâmetros do modelo, que são aprendidos durante o treino do modelo. A busca por hiperparâmetros de determinado algoritmo de aprendizado de máquina que retorne o melhor desempenho medido em um conjunto de validação deu origem ao conceito de otimização de hiperparâmetros.
Acerca dos conceitos de otimização de hiperparâmetros de
modelos de aprendizado de máquinas, julgue o item que se segue.
A otimização bayesiana se utiliza do conceito de
probabilidade para encontrar o valor de entrada de uma
função que possa retornar o menor valor de saída possível.
Nesse método, o número de iterações de pesquisa pode ser
reduzido a partir da escolha dos valores de entrada, levando
em consideração os resultados anteriores, o que caracteriza
um processo iterativo.
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Considere que, em uma análise de agrupamentos por meio de
mistura de gaussianas, três distribuições normais com médias 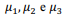 se referem, respectivamente, aos clusters 1, 2 e 3.
Nessa situação, pelo modelo de mistura de gaussianas, o
cluster 1 é constituído pelas observações mais próximas da
média
se referem, respectivamente, aos clusters 1, 2 e 3.
Nessa situação, pelo modelo de mistura de gaussianas, o
cluster 1 é constituído pelas observações mais próximas da
média 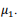
Com respeito a métodos para imputação de dados, julgue o seguinte item.
O método de imputação K-NN (k-nearest neighbours) leva
em consideração os padrões de similaridade presentes no
conjunto de dados para predizer os valores faltantes. No
entanto, a escolha da função de distância para a aplicação
desse método, como, por exemplo, HEOM (heterogeneous
euclidean-overlap metric) ou HVDM (heterogeneous value
difference metric), pode influenciar significativamente nos
resultados da imputação.
Com respeito a métodos para imputação de dados, julgue o seguinte item.
Um dos passos para tratar com dados faltantes é avaliar o
tipo de dado perdido; assim, por exemplo, o método MICE
(multivariate imputation by chained equations) não seria
aplicável para dados perdidos do tipo MAR (missing at
random).

Com base no modelo entidade-relacionamento (MER) precedente, que apresenta a representação das regras de uma instituição de pesquisa, existe um Pesquisador cadastrado com o nome Pedro. Todos os atributos do MER são do tipo caractere e um dos comandos SQL usados para a construção do modelo é mostrado a seguir.

A partir das informações constantes no modelo e dos dados sobre o conteúdo dos atributos, julgue o item subsecutivo.
Após a criação da tabela Projeto, a criação das chaves estrangeiras (FK) do relacionamento Orienta pode ser feita corretamente conforme a seguir.

Com base no modelo entidade-relacionamento (MER) precedente, que apresenta a representação das regras de uma instituição de pesquisa, existe um Pesquisador cadastrado com o nome Pedro. Todos os atributos do MER são do tipo caractere e um dos comandos SQL usados para a construção do modelo é mostrado a seguir.
A partir das informações constantes no modelo e dos dados sobre o conteúdo dos atributos, julgue o item subsecutivo.
Projeto é uma entidade fraca em relação à entidade
Pesquisador, considerando o relacionamento
identificado como Responsavel e os atributos do MER.
Com base no modelo entidade-relacionamento (MER) precedente, que apresenta a representação das regras de uma instituição de pesquisa, existe um Pesquisador cadastrado com o nome Pedro. Todos os atributos do MER são do tipo caractere e um dos comandos SQL usados para a construção do modelo é mostrado a seguir.
A partir das informações constantes no modelo e dos dados sobre o conteúdo dos atributos, julgue o item subsecutivo.
Por meio do comando SQL a seguir, é possível recuperar o nome dos pesquisadores responsáveis por projetos, seguido pelo nome de seu orientador, mas apenas os projetos orientados por Pedro.

Com referência aos conceitos de banco de dados e data warehouse, julgue o item seguinte.
Em sistemas NoSQL baseados em armazenamento de chave-valor, a chave é multidimensional e composta pela
combinação do nome de tabela com a chave linha-coluna e
com o rótulo de data e hora.
O Hadoop Distributed File System (HDFS) é construído usando a linguagem Java, o que permite que sua arquitetura mestre/escravo seja implementada em uma ampla variedade de máquinas

Considerando que a figura anterior mostra o layout de um container, julgue o próximo item.
O método CI/CD refere-se a um processo de automação para
os usuários de um sistema que enviam, de forma contínua,
feedbacks para os desenvolvedores desse sistema.