Questões de Concurso Público Petrobras 2022 para Ciência de Dados
Foram encontradas 18 questões
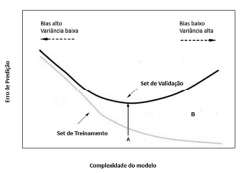
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
Quando se verifica um alto erro no treinamento com valor
próximo ao erro na validação, percebido na região à
esquerda do ponto A, tem-se um clássico problema de
underfitting, caracterizado pelo alto valor do bias.
As máquinas de vetores de suporte (SVMs) são originalmente utilizadas para a classificação de dados em duas classes, ou seja, na geração de dicotomias. Nas SVMs com margens rígidas, conjuntos de treinamento linearmente separáveis podem ser classificados. Acerca das características das SVMs com margens rígidas, julgue o item a seguir.
Um conjunto linearmente separável é composto por
exemplos que podem ser separados por pelo menos um
hiperplano. As SVMs lineares buscam o hiperplano
ótimo segundo a teoria do aprendizado estatístico, definido
como aquele em que a margem de separação entre as classes
presentes nos dados é minimizada.
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Se a matriz de variância-covariância referente a três variáveis for
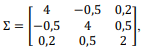
e se o menor autovalor dessa matriz for igual a 1,84, então as
duas primeiras componentes principais explicam 81,6% da
variação total referente a essas variáveis.
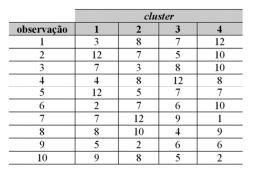
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Considere a tabela abaixo que mostra as distâncias entre cada observação de um conjunto de dados hipotético e os vetores médios (centroides) do cluster correspondente ao final da aplicação do algoritmo de agrupamento k-means. Com base nessa tabela, infere-se que o cluster 1 é constituído pelas observações 2, 5 e 10.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Uma RNA é formada por unidades que fazem operações a partir das entradas (sinais) recebidas pelas suas conexões; cada sinal é multiplicado por um peso e, após a soma ponderada dos sinais, caso o nível de atividade atinja o threshold, a unidade produz uma determinada resposta de saída.