Questões de Concurso Público Petrobras 2022 para Ciência de Dados
Foram encontradas 23 questões
Acerca das características específicas dessas métricas, julgue o próximo item.
A matriz de confusão a seguir apresenta três rótulos de classe; os elementos diagonais representam o número de pontos para os quais o rótulo previsto é igual ao rotulo verdadeiro, enquanto qualquer coisa fora da diagonal teve um rótulo atribuído erroneamente pelo classificador. Quanto menores forem os valores diagonais da matriz de confusão, melhor o modelo adotado.
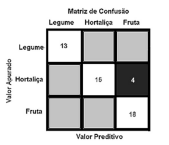
As métricas de avaliação de desempenho de um modelo de aprendizado de máquina, que é um componente integrante de qualquer projeto de ciência de dados, destinam-se a estimar a precisão da generalização de um modelo sobre os dados futuros (não vistos ou fora da amostra). Dentre as métricas mais conhecidas, estão a matriz de confusão, precisão, recall, pontuação, especificidade e a curva de características operacionais do receptor (ROC).
Acerca das características específicas dessas métricas, julgue o próximo item.
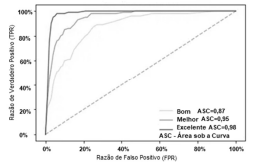
As curvas ROC a seguir mostram a taxa de especificidade
(verdadeiros positivos) versus a taxa de sensibilidade (falsos
positivos) do modelo adotado; a linha tracejada é a linha de
base da métrica de avaliação e define uma adivinhação
aleatória.
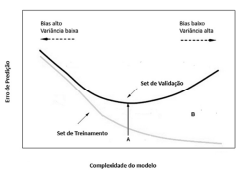
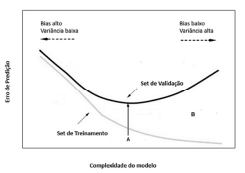
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
A região do gráfico entre as duas curvas, indicada pela letra
B, mostra a região de erro de generalização para o modelo de
aprendizado de máquina.
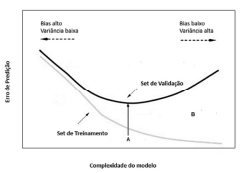
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
O Set de Treinamento é usado para qualificar o desempenho
do modelo, enquanto o Set de Validação é utilizado para
criar o modelo de aprendizado de máquina.
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
Considerando que a variância é um erro de sensibilidade para
pequenas flutuações no conjunto de treinamento, infere-se
que um baixo nível de variância pode fazer que o algoritmo
associado a um modelo de aprendizado de máquina perca as
relações relevantes entre os atributos de entrada e a variável
de saída, caracterizando o erro de overfitting, percebido na
região à direita do ponto A.
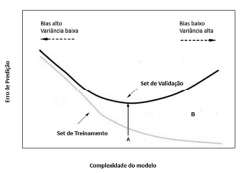
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
Quando se verifica um alto erro no treinamento com valor
próximo ao erro na validação, percebido na região à
esquerda do ponto A, tem-se um clássico problema de
underfitting, caracterizado pelo alto valor do bias.
As máquinas de vetores de suporte (SVMs) são originalmente utilizadas para a classificação de dados em duas classes, ou seja, na geração de dicotomias. Nas SVMs com margens rígidas, conjuntos de treinamento linearmente separáveis podem ser classificados. Acerca das características das SVMs com margens rígidas, julgue o item a seguir.
Um conjunto linearmente separável é composto por
exemplos que podem ser separados por pelo menos um
hiperplano. As SVMs lineares buscam o hiperplano
ótimo segundo a teoria do aprendizado estatístico, definido
como aquele em que a margem de separação entre as classes
presentes nos dados é minimizada.
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Se a matriz de variância-covariância referente a três variáveis for
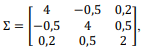
e se o menor autovalor dessa matriz for igual a 1,84, então as
duas primeiras componentes principais explicam 81,6% da
variação total referente a essas variáveis.
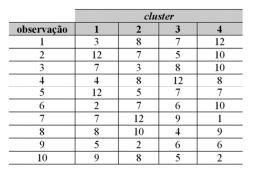
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Considere a tabela abaixo que mostra as distâncias entre cada observação de um conjunto de dados hipotético e os vetores médios (centroides) do cluster correspondente ao final da aplicação do algoritmo de agrupamento k-means. Com base nessa tabela, infere-se que o cluster 1 é constituído pelas observações 2, 5 e 10.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Uma RNA é formada por unidades que fazem operações a partir das entradas (sinais) recebidas pelas suas conexões; cada sinal é multiplicado por um peso e, após a soma ponderada dos sinais, caso o nível de atividade atinja o threshold, a unidade produz uma determinada resposta de saída.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Em RNA formada unicamente de perceptron, uma pequena
alteração nos pesos de um único perceptron na rede pode
ocasionar grandes mudanças na saída desse perceptron;
mesmo com a inserção das funções de ativação, não é
possível controlar o nível da mudança, por isso, essas redes
são voltadas para a resolução de problemas específicos, tais
como regressão e previsão de séries temporais.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
As funções de ativação são elementos importantes nas redes
neurais artificiais; essas funções introduzem componente não
linear nas redes neurais, fazendo que elas possam aprender
mais do que relações lineares entre as variáveis dependentes
e independentes, tornando-as capazes de modelar também
relações não lineares.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
O algoritmo de backpropagation consiste das fases de
propagação e de retro propagação: na primeira, as entradas
são passadas através da rede e as previsões de saída são
obtidas; na segunda, se calcula o termo de correção dos
pesos e, por conseguinte, a atualização dos pesos.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Rede neural recorrente é uma arquitetura similar à
feedforward; a diferença é que a cada nova camada oculta
(hidden layer) é acrescentada outra camada recorrente à
arquitetura conectada à camada anterior, duplicando assim a
quantidade de camadas.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Em RNA, o uso de early stopping, ainda que não evite o
overfitting, permite calcular com mais precisão a
classificação nos dados de validação e, assim, melhorar a
acurácia do treinamento.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
As redes neurais convolucionais se utilizam de uma
arquitetura especial que é adaptada para classificar imagens
por meio de algoritmo de aprendizado profundo que pode
captar uma imagem de entrada, atribuir importância por meio
de pesos e ser capaz de diferenciar um do outro.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Uma rede neural convolucional é composta por camadas
convolucionais, unidades de processamento não linear e
camadas de subamostragem (pooling); ela possui como
característica a habilidade em explorar correlações temporais
e espaciais nos dados.
Com respeito a machine learning aplicado, julgue o próximo item.
Classificação de imagens é um método de aprendizado não
supervisionado no qual se aplica um modelo de treinamento
para o reconhecimento de padrões gráficos presentes em
amostras de imagens.
Com respeito a machine learning aplicado, julgue o próximo item.
Mask RCNN (region-based convolutional neural network) é
um método para segmentação de objetos e instâncias que se
baseia em detecção, enquanto o método SSAP (single-shot
instance segmentation) se baseia em pixels.
Com respeito a machine learning aplicado, julgue o próximo item.
Stop-words constituem um conjunto de palavras que
proporcionam pouca informação para o significado de uma
frase.