Questões de Concurso Público IPEA 2024 para Técnico de Planejamento e Pesquisa -Ciência de Dados
Foram encontradas 13 questões
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383233
Engenharia de Software
Algoritmos fuzzy matching em processamento de linguagem natural são métodos que permitem encontrar correspondências aproximadas entre strings, ou seja, sequências
de caracteres, como palavras ou frases. Esses algoritmos
são úteis para lidar com situações, tais como erros de digitação, variações ortográficas, sinônimos, abreviações.
Eles também podem ser aplicados para comparar textos,
extrair informações, classificar sentimentos, entre outras
finalidades. Existem diferentes tipos de algoritmos fuzzy
matching, como a Similaridade de Jaccard, que mede a
proporção de elementos comuns entre dois conjuntos de
strings.
Qual das palavras a seguir apresenta o maior valor da similaridade de Jaccard, quando comparada com a palavra “computador”?
Qual das palavras a seguir apresenta o maior valor da similaridade de Jaccard, quando comparada com a palavra “computador”?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383238
Engenharia de Software
Outliers são pontos ou observações em um conjunto de
dados que diferem significativamente da maioria dos demais outros pontos. Eles podem ser resultados de variações na medição, erros de entrada de dados ou, ainda,
podem indicar uma variação genuína da fonte de coleta.
Em preparação para análise de um conjunto de dados, o tratamento de outliers
Em preparação para análise de um conjunto de dados, o tratamento de outliers
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383271
Engenharia de Software
Na avaliação de um modelo criado por aprendizado de
máquina em um experimento que buscava identificar textos de opinião sobre o desempenho da economia, separando-os dos que não forneciam opinião alguma, só fatos
e dados, foi encontrada a seguinte matriz de confusão:
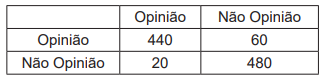
Considerando-se que, nessa matriz, as linhas indicam a resposta correta e as colunas indicam a previsão, a acurácia é de
Considerando-se que, nessa matriz, as linhas indicam a resposta correta e as colunas indicam a previsão, a acurácia é de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383272
Engenharia de Software
Um pesquisador iniciante em aprendizado de máquina
trabalhava com um modelo de classificação binário com
as duas classes equilibradas. Inicialmente, ele fez a avaliação de seu modelo, separando 20% dos dados disponíveis para a avaliação, e o treinou com 80% dos dados,
fazendo o processo apenas uma vez. Depois, a pedido
de seu chefe, ele trocou a forma de avaliação, separando o conjunto de dados em 10 partes e escolhendo, em
10 rodadas, uma parte diferente para avaliação e as outras para treinamento.
Essas duas formas de avaliar um modelo são conhecidas, respectivamente, como
Essas duas formas de avaliar um modelo são conhecidas, respectivamente, como
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383273
Engenharia de Software
Em processamento de linguagem natural, o modelo
Skip-Gram é uma técnica popular para treinar word
embeddings.
O treinamento do modelo Skip-Gram destaca-se de outras técnicas, como o Continuous Bag of Words (CBOW), por ter a seguinte característica:
O treinamento do modelo Skip-Gram destaca-se de outras técnicas, como o Continuous Bag of Words (CBOW), por ter a seguinte característica: