Questões de Concurso
Sobre sql em banco de dados
Foram encontradas 4.618 questões
v_ID TIPONUTRICIONISTA.ID%type := 2; v_DESCRICAO TIPONUTRICIONISTA.DESCRICAO%type := ‘Esportiva’; BEGIN
INSERT INTO TIPONUTRICIONISTA (ID, DESCRICAO) VALUES (v_ID, upper(v_DESCRICAO)); COMMIT;
END;
O script acima, no Sistema de Gerenciamento de Banco de Dados (SGBD) Oracle, tem a finalidade de
Você é um técnico em informática da Sanepar e recebeu a tarefa de gerar um relatório que lista os nomes dos funcionários que ganham mais de R$ 4.000, possuem dependentes e que esses dependentes sejam estudantes. Para isso, você precisa realizar uma consulta SQL (Structured Query Language) utilizando as tabelas Funcionarios e Dependentes do banco de dados da organização.
Descrição das tabelas:
• Funcionarios: contém informações sobre os funcionários, incluindo colunas como FuncionarioID, Nome, Salario e outras.
• Dependentes: contém informações sobre os dependentes dos funcionários, incluindo colunas como DependenteID, FuncionarioID (chave estrangeira), Status (que pode ser ‘Estudante’ ou não) e outras.
Sabendo disso, assinale a alternativa que apresenta a consulta SQL correta para você realizar essa tarefa.
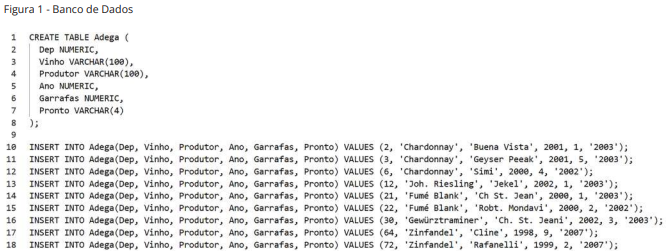
Considere a execução do comando:
SELECT COUNT(Garrafas) FROM Adega WHERE Ano = ‘2000’;
É CORRETO afirmar que:
Considere a execução do comando:
SELECT * FROM Adega WHERE Produtor = ‘Ch St. Jean’;
É CORRETO afirmar que:
(PUGA, Sandra Gavioli; FRANÇA, Edson Tarcísio; GOYA, Milton Roberto. Banco de dados: implementação em SQL, PL/SQL e Oracle 11g. São Paulo: Pearson, 2013.)
CREATE TABLE aluno (
idAluno integer primary key,
nome varchar(40),
nota number,
frequencia number
)
Considere que o estudante obtém aprovação quando atinge a nota 7 e possui frequência mínima de 75. Assinale a opção que contém o comando SQL que retorna apenas a chave primária e o nome do aluno que obteve nota para aprovação, mas que reprovou por frequência, mostrando o resultado em ordem crescente de nota:
Assinale a alternativa que apresenta o código SQL (Structured Query Language) que deverá ser usado para remover do banco de dados todos os farmacêuticos que residem em Copacabana.
I - O comando CREATE é utilizado para criar uma nova coluna no banco de dados. Com esse comando, é possível definir as colunas da tabela, seus tipos de dados, restrições e outros atributos.
II - O comando READ, também conhecido como SELECT, é utilizado para realizar consultas e obter dados de uma ou mais tabelas do banco de dados. É possível fazer uso de cláusulas ROLLBACK para filtrar os resultados e obter apenas as informações desejadas.
III - O comando UPDATE é utilizado para realizar atualizações em registros existentes em uma tabela do banco de dados. Com esse comando, é possível modificar os valores de uma ou mais colunas em um ou mais registros.
IV - O comando DELETE é utilizado para excluir registros de uma tabela do banco de dados. Com esse comando, é possível remover um ou mais registros de forma permanente.
As alternativas CORRETAS são:
Analise a consulta SQL a seguir.
SELECT nome, sobrenome FROM Funcionarios
WHERE (nome LIKE ‘A%’ OR nome LIKE ‘O%’)
AND LENGTH(sobrenome) >= 6;
Assinale a alternativa que apresenta, correta e respectivamente, o nome e o sobrenome de um funcionário selecionado pela consulta.