Questões de Concurso
Sobre postgresql em banco de dados
Foram encontradas 650 questões
1. criar o esquema processos; e
2. atribuir ao perfil ad1 o direito de apagar os registros das tabelas do esquema processos, criados por dadosadm, podendo usar alguma condição.
No PostgreSQL, para implementar os passos definidos, Juca deve executar os comandos:
Observe a inserção dos registros pelo seguinte script SQL.
INSERT INTO Parte (ParteID, idade)
VALUES (1 ,17);
INSERT INTO Parte (ParteID, idade)
VALUES (2 ,16);
INSERT INTO Processo (processoID, data_audiencia,
valor_causa)
VALUES (1 ,'2025-02-05',1000);
INSERT INTO Processo (processoID, data_audiencia,
valor_causa)
VALUES (2 ,'2025-10-05',2000);
INSERT INTO ProcessoParte (processoID, parteid)
VALUES (1 ,1);
INSERT INTO ProcessoParte (processoID, parteid)
VALUES (2 ,2);
No PostgreSQL, para consultar os Processos (Processos) que envolvem partes menores que 18 anos, por ordem de maior Valor de Causa (valor_causa), cuja Audiência (data_audiencia) está agendada para os próximos 30 dias, deve-se executar o comando SQL:
Observe a transação SQL a seguir.

No PostgreSQL, após a execução da transação SQL, o(s) registro(s) da tabela Parte é(são):
O administrador de banco de dados Pedro criou o papel dadosadm para cadastrar os funcionários do MPU que desempenham a função de Administrador de Dados usando o seguinte comando SQL no PostgreSQL:
CREATE ROLE dadosadm WITH LOGIN PASSWORD 'admin';
Para que o papel dadosadm possa alterar a estrutura, bem como adicionar e remover linhas e colunas da tabela processo com controle total, Pedro deve usar o seguinte comando SQL:
Observe o modelo de dados, que utiliza a Notação Crow's Foot (Pé de Galinha), onde PK representa a Chave Primária:
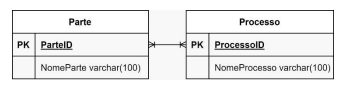
Após a normalização, no PostgreSQL, para implementar o modelo de dados físico com as integridades referenciais, deve-se executar o seguinte script SQL:

Em condições ideais, esta função seria corretamente chamada utilizando-se o comando:
Quanto às ferramentas OLAP, à álgebra relacional e aos bancos de dados relacionais em plataforma baixa, julgue o item a seguir.
O parâmetro shared_buffers do PostgreSQL especifica a quantidade de memória que cada operação de consulta pode utilizar para realizar tarefas, como, por exemplo, ordenação e agrupamento.
O PostgreSQL possui a ferramenta PITR (point-in-time recovery), que permite restaurar o banco de dados para um momento específico no tempo.
Considerando as necessidades da startup, que precisa de um SGBD robusto, escalável e com bom custo-benefício, qual seria a melhor escolha e porquê?
I. Os bancos de dados relacionais organizam os dados em tabelas, onde as relações entre os dados são baseadas em chaves primárias e estrangeiras. Exemplos incluem PostgreSQL, MySQL, Oracle Database e Microsoft SQL Server.
II. O MongoDB é um banco de dados NoSQL amplamente utilizado, que armazena dados no formato de documentos JSON ou BSON, sendo indicado para aplicações que exigem flexibilidade no esquema dos dados.
III. Bancos de dados NoSQL não possuem suporte a transações ACID, sendo sempre uma escolha inadequada para aplicações críticas que exigem integridade de dados.
IV. Ao contrário de bancos de dados relacionais, bancos NoSQL não oferecem mecanismos de consulta eficientes, sendo projetados exclusivamente para leitura rápida e consultas básicas.
Alternativas:
A cada atualização do banco de dados do servidor primário, um WAL é encaminhado diretamente para os dois servidores em standby. O processo de replicação se encerra após o recebimento de respostas de todos os servidores em standby.
Com relação ao sistema de banco de dados em questão, é correto afirmar que
Para manter um registro de todas as atualizações realizadas no banco de dados e de usuários em particular que aplicaram cada atualização, é utilizado o log do sistema. O log do sistema inclui uma entrada para cada operação aplicada ao banco de dados.
Sistemas de banco de dados baseados em PostgreSQL possuem a função trigger para a criação de logs. Essa função é muito utilizada para atualizar o log do sistema toda vez que uma determinada operação no banco de dados é realizada.
Mais especificamente, quando o trigger está associado a tabelas de dados, ele somente pode ser executado
A seguir, os seguintes comandos foram executados pelo usuário tce_rr que possui perfil de administrador:
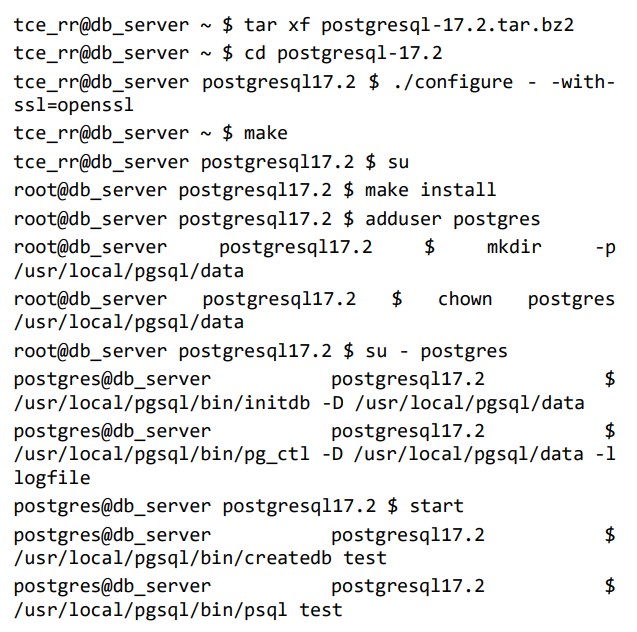
Com relação a essa rotina de instalação, é correto afirmar que
A respeito de PostgreSQL, de SQL Server e de MySQL, julgue o item a seguir.
O parallel scan do PostgreSQL permite a divisão de uma operação de leitura e escrita de tabela entre vários processos, distribuindo a carga de trabalho e aproveitando o paralelismo do hardware para melhorar o desempenho de consultas em tabelas extensas.
Julgue o próximo item, relativo a PostgreSQL e H2 Database.
SELECT 'trf minas gerais'::tsvector @@ 'trf'::tsquery as resultado;
O resultado apresentado após a execução do código precedente, desenvolvido em PostgreSQL 17, será o seguinte.
resultado
-----------
t
(1 row)
Julgue o próximo item, relativo a PostgreSQL e H2 Database.
WITH RECURSIVE t(n) AS (
SELECT 1
UNION
SELECT n*2 FROM t
)
SELECT n FROM t LIMIT 5;
A execução do código precedente, desenvolvido em PostgreSQL 17, apresentará o seguinte resultado.
n
----
1
2
4
8
16
(5 rows)
A respeito de administração de banco de dados, julgue o item a seguir.
No PostgreSQL, o mecanismo TOAST é essencial para armazenar eficientemente dados de grande tamanho, permitindo que o banco de dados gerencie colunas com valores extensos, como TEXT e BYTEA, sem ultrapassar o limite de 16 KB por linha.
• id_venda (INT): identificador da venda
• data_venda (DATE): data em que a venda foi realizada
• id_produto (INT): identificador do produto vendido
• quantidade (INT): quantidade de itens vendidos
• valor_total (DECIMAL): valor total da venda
Qual das consultas abaixo retorna o número do mês, número total de vendas e o valor médio dasvendas do mês indepentende do ano da venda, considerando o uso da linguagem SQL no banco dedados PostgreSQL?