Questões de Concurso
Sobre banco de dados paralelos e distribuídos em banco de dados
Foram encontradas 245 questões
No MapReduce, modelo de processamento de dados paralelo para processamento e análise de grandes volumes de dados, os programas são escritos em um estilo de programação funcional, no qual as funções Map e Reduce devem ser criadas.
No Hadoop MapReduce, o JobTracker é o processo-escravo responsável por aceitar submissões de tarefas e disponibilizar funções administrativas.
Em sistemas de bancos de dados distribuídos, o controle de concorrência baseado em bloqueio de duas fases determina que, após a liberação de um de seus bloqueios, as transações não solicitem um novo bloqueio.

vara1

vara2

Considerando a fragmentação realizada, é correto afirmar:
processo1
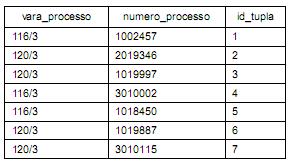
processo2
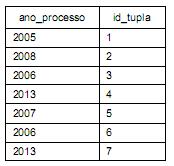
Dado o novo projeto acima, é correto afirmar:
Com relação ao tema “bancos de dados distribuídos”, analise as afirmativas a seguir.
I. Fragmentação horizontal de uma tabela pode ser de dois tipos: primária e derivada.
II. Fragmentação vertical de uma tabela é mais complicada que a fragmentação horizontal. Existem duas abordagens heurísticas para implementá‐la: agrupamento e divisão.
III. Fragmentação híbrida não é suportada em bancos de dados distribuídos.
Assinale:
O processo de otimização de consultas distribuídas utiliza o conceito de espaço de pesquisa.
Nesse contexto, assinale a alternativa que apresenta o conceito de espaço de pesquisa.
Julgue o item a seguir, acerca dos tópicos avançados em desenvolvimento de sistemas.
Em bancos de dados distribuídos, um comando utilizado para
executar uma tarefa independe da localização dos dados e do
sistema do qual o comando foi emitido.
No sistema de banco de dados distribuídos, a fragmentação horizontal tem a função de distribuir atributos e métodos da classe entre os fragmentos, para dividir a estrutura de dados da árvore para melhorar o desempenho de consultas que acessem somente um subconjunto dos elementos dessa coleção.