Questões de Concurso
Sobre hashing em algoritmos e estrutura de dados
Foram encontradas 101 questões
No que se refere a vulnerabilidades e ataques a sistemas computacionais e criptografia, julgue o próximo item.
Projetado para velocidade, simplicidade e segurança, o
algoritmo MD (message digest) produz um valor de hash de
128 bites para um tamanho arbitrário da mensagem inserida.
Transformar informações em códigos únicos, acelerando o acesso a dados em estruturas como tabelas é a função da técnica chamada hashing. Ela é uma técnica fundamental na programação que permite armazenar e recuperar dados de forma eficiente. O entendimento do hashing é essencial para otimizar algoritmos e melhorar o desempenho de muitas aplicações.
Sobre essa técnica, analise as assertivas a seguir.
I. Hashing serve para comprimir dados para economizar espaço de armazenamento.
II. Acelerar o acesso a dados, tornando-o mais eficiente, é o principal objetivo da técnica hashing.
III. Transformar texto legível em código binário, entendível pelo computador, é um dos objetivos da técnica hashing.
É correto o que se afirma apenas em
Em relação à tabela de espalhamento, segundo Cormen (2012), analise os itens a seguir:
I. O tempo médio para pesquisar um elemento em uma tabela de espalhamento é O(1).
II. Quando temos mais de uma chave mapeada para a mesma posição, temos uma situação de colisão.
III. A técnica mais simples para resolução de colisões é por endereçamento aberto.
Está CORRETO o que se afirma em:
"Existem diversas Estruturas de Dados utilizadas na programação, quatro exemplos principais são: ______"
Assinale a alternativa que preencha corretamente a lacuna.
Considere os dados abaixo relativos a um método hashing.
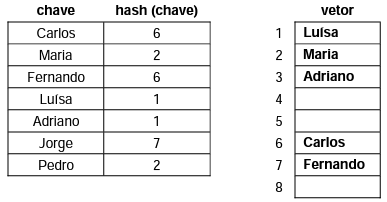
Com base no método apresentado acima e na sua continuação, é correto afirmar que
Em relação a classificação da informação, hash e controle de acesso, julgue o item a seguir.
Considere-se que a versão inicial de um documento digital
que tramitava numa organização tenha como hash MD5
calculado o valor 3466cf1f875183edb9dba67893f74667.
Considere-se, ainda, que o documento tenha sido revisado
por outros dois funcionários e tenha tido seu conteúdo
modificado somente em aspectos sutis de pontuação e
que, ao fim dessas revisões, o hash MD5 tenha sido
novamente calculado. Nesse caso, o valor final
do hash MD5 obtido terá sido o mesmo, ou seja,
3466cf1f875183edb9dba67893f74667.
Quanto às suas propriedades básicas, para que o algoritmo de hash seja considerado forte, é correto afirmar que:
A respeito de algoritmos de hash, julgue o item que se segue.
O uso de hashes na geração de assinaturas digitais garante a
autenticidade, a confidencialidade e a integridade de uma
informação.
A respeito de algoritmos de hash, julgue o item que se segue.
A ferramenta mais utilizada para reduzir a probabilidade de
acontecerem colisões em uma função de resumo (hash) é o
ajuste de distribuição, de maneira que, quanto mais
heterogênea e dispersa for a função resumo, menor será a sua
probabilidade de colisão.
A respeito de algoritmos de hash, julgue o item que se segue.
Hash é o resultado único e de tamanho fixo de um método
criptográfico aplicado sobre uma informação, conhecido
como função de resumo.
A respeito de algoritmos de hash, julgue o item que se segue.
Os algoritmos de hash MD5 e SHA-1 apresentam,
respectivamente, mensagem de resumo de 160 bits e de 128
bits.
A respeito de algoritmos de hash, julgue o item que se segue.
É possível utilizar uma função de resumo para verificar a
integridade de um arquivo ou mesmo para gerar assinaturas
digitais.
Considere o esquema com a distribuição das chaves (k) numéricas de uma tabela Hash a seguir.

Acerca do esquema, avalie se as afirmativas a seguir são falsas (F) ou verdadeiras (V).
I. A função Hash utilizada é h(k) = k mod 7.
II. Há colisão em duas das chaves.
III. A complexidade do algoritmo de busca é O(log n).
As afirmativas são, respectivamente,