Questões de Concurso
Sobre conceitos básicos e algoritmos em algoritmos e estrutura de dados
Foram encontradas 815 questões
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
SEBRAE-NACIONAL
Prova:
CESPE / CEBRASPE - 2024 - SEBRAE-NACIONAL - Analista Técnico II – Cientista de Dados |
Q3015573
Algoritmos e Estrutura de Dados
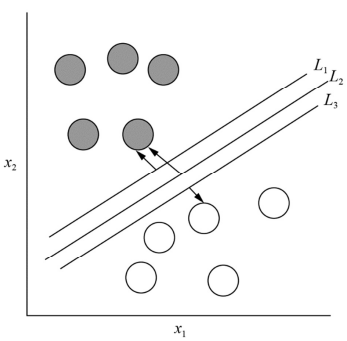
Considerando a figura precedente, assinale a opção correta em
relação ao algoritmo de SVM (support vector machine).
Ano: 2024
Banca:
FGV
Órgão:
EPE
Prova:
FGV - 2024 - EPE - Analista de Gestão Corporativa - Tecnologia da Informação (Ciência de Dados) |
Q2847414
Algoritmos e Estrutura de Dados
Algoritmos de agrupamento são fundamentais para a área de
aprendizado de máquina não supervisionado. Em geral, esses
algoritmos determinam clusters de instâncias de dados que
possuem algum traço de similaridade entre si.
Relacione os métodos de agrupamento hierárquico e o K-means às suas principais características.
1. Agrupamento Hierárquico 2. K-means
( ) Seus resultados são altamente sensíveis ao número de clusters que deve ser pré-definido pelo usuário do algoritmo.
( ) Baseia-se em abordagens top-down ou bottom-up, isto é, com a divisão ou com a união sucessiva de clusters.
( ) Seus resultados costumam ser graficamente visualizados por dendrogramas, que podem ser seccionados de acordo com o número de clusters determinado pelo usuário do algoritmo.
( ) Avalia distâncias entre as instâncias de dados e os centroides dos clusters e atualiza a posição dos centroides dos clusters sucessivamente, até a convergência.
Assinale a opção que indica a relação correta, na ordem apresentada.
Relacione os métodos de agrupamento hierárquico e o K-means às suas principais características.
1. Agrupamento Hierárquico 2. K-means
( ) Seus resultados são altamente sensíveis ao número de clusters que deve ser pré-definido pelo usuário do algoritmo.
( ) Baseia-se em abordagens top-down ou bottom-up, isto é, com a divisão ou com a união sucessiva de clusters.
( ) Seus resultados costumam ser graficamente visualizados por dendrogramas, que podem ser seccionados de acordo com o número de clusters determinado pelo usuário do algoritmo.
( ) Avalia distâncias entre as instâncias de dados e os centroides dos clusters e atualiza a posição dos centroides dos clusters sucessivamente, até a convergência.
Assinale a opção que indica a relação correta, na ordem apresentada.
Ano: 2024
Banca:
FUNDATEC
Órgão:
SIMAE - SC
Prova:
FUNDATEC - 2024 - SIMAE - SC - Oficial de Informática |
Q2657908
Algoritmos e Estrutura de Dados
Analise o algoritmo abaixo:

Qual forma de representação de algoritmos foi utilizada?
Qual forma de representação de algoritmos foi utilizada?
Ano: 2024
Banca:
VUNESP
Órgão:
Câmara de Campinas - SP
Prova:
VUNESP - 2024 - Câmara de Campinas - SP - Analista Legislativo - TI |
Q2566860
Algoritmos e Estrutura de Dados
O algoritmo a seguir está apresentado na forma de uma
pseudolinguagem (Português Estruturado). Analise-o e
responda ao que se pede.

Considerando que o valor lido para a variável Z, no início do algoritmo, tenha sido 7, então o valor impresso de Z, ao final da execução desse algoritmo, será:
Considerando que o valor lido para a variável Z, no início do algoritmo, tenha sido 7, então o valor impresso de Z, ao final da execução desse algoritmo, será:
Ano: 2024
Banca:
FUNDATEC
Órgão:
Prefeitura de Cidreira - RS
Prova:
FUNDATEC - 2024 - Prefeitura de Cidreira - RS - Técnico em Informática |
Q2561165
Algoritmos e Estrutura de Dados
São tipos de dados utilizados em algoritmos, EXCETO:
Ano: 2024
Banca:
FUNDATEC
Órgão:
Prefeitura de Panambi - RS
Prova:
FUNDATEC - 2024 - Prefeitura de Panambi - RS - Técnico em Informática - Monitor de Laboratório |
Q2547114
Algoritmos e Estrutura de Dados
Analise o algoritmo abaixo, escrito no software VisuAlg 3.0.

Ao ser executado no VisuAlg 3.0, o algoritmo apresentará um aviso de problema. O que precisará ser
modificado para que o problema seja corrigido?
Ano: 2024
Banca:
FUNDATEC
Órgão:
Prefeitura de Panambi - RS
Prova:
FUNDATEC - 2024 - Prefeitura de Panambi - RS - Técnico em Informática - Monitor de Laboratório |
Q2547113
Algoritmos e Estrutura de Dados
Abaixo está representada a declaração de uma variável em pseudocódigo (Portugol).
Notas: Vetor [1..10,1..3] de Real
Na declaração acima, quantas posições possui a variável Notas?
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
TJ-MA
Prova:
Instituto Consulplan - 2024 - TJ-MA - Analista Judiciário - Analista de Sistemas - Desenvolvimento |
Q2536533
Algoritmos e Estrutura de Dados
A representação de dados em binário é fundamental para o funcionamento de sistemas digitais e computadores. O sistema binário,
com base 2, utiliza apenas dois dígitos: 0 e 1. Converta o número binário (10112) em decimal e assinale a alternativa
correspondente.
Ano: 2024
Banca:
FUNDATEC
Órgão:
Prefeitura de Coqueiral - MG
Prova:
FUNDATEC - 2024 - Prefeitura de Coqueiral - MG - Técnico de Informática |
Q2529021
Algoritmos e Estrutura de Dados
Analise o algoritmo abaixo, escrito no software VisuAlg 3.0:

Ao final da execução do algoritmo acima, qual variável conterá o maior valor numérico?
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518310
Algoritmos e Estrutura de Dados
Algoritmos para assimilação de dados podem ser implementados de
maneira eficiente e otimizada por meio de paralelização de
processos.
O Parallel Data Assimilation Framework (PDAF) é um pacote de software que simplifica a implementação de métodos de assimilação, provendo versões totalmente paralelizadas de algoritmos, como por exemplo, diferentes versões dos Filtros de Kalman por conjunto (EnKF). Um dos requisitos de funcionamento do PDAF é o uso de um protocolo padronizado de comunicação para computação paralela.
O principal padrão de comunicação entre os processos paralelos executados em um sistema de memória distribuída, é denominado
O Parallel Data Assimilation Framework (PDAF) é um pacote de software que simplifica a implementação de métodos de assimilação, provendo versões totalmente paralelizadas de algoritmos, como por exemplo, diferentes versões dos Filtros de Kalman por conjunto (EnKF). Um dos requisitos de funcionamento do PDAF é o uso de um protocolo padronizado de comunicação para computação paralela.
O principal padrão de comunicação entre os processos paralelos executados em um sistema de memória distribuída, é denominado
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518302
Algoritmos e Estrutura de Dados
Métodos de assimilação de dados clássicos são tradicionalmente
classificados em sequenciais ou variacionais. Os métodos
variacionais guardam semelhanças com a teoria de controle ótimo,
por sua vez desenvolvida a partir do estabelecimento dos
fundamentos do cálculo variacional.
Com relação à formulação variacional de assimilação de dados, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Trata-se da busca por estados dos sistemas que minimizam um funcional de custo, em geral definido como um erro quadrático entre observações e predições correspondentes àqueles estados, calculadas por modelos matemáticos.
( ) Envolve a necessidade de aplicação de técnicas de localização e/ou inflação de covariâncias para eliminar correlações espurias entre possíveis soluções de problemas de otimização.
( ) Baseia-se em otimizações com restrições dinâmicas fortes, introduzidas no problema por uso de multiplicadores de Largrange; ou fracas, introduzidas no problema como termos ponderados de penalidades.
As afirmativas são, respectivamente,
Com relação à formulação variacional de assimilação de dados, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Trata-se da busca por estados dos sistemas que minimizam um funcional de custo, em geral definido como um erro quadrático entre observações e predições correspondentes àqueles estados, calculadas por modelos matemáticos.
( ) Envolve a necessidade de aplicação de técnicas de localização e/ou inflação de covariâncias para eliminar correlações espurias entre possíveis soluções de problemas de otimização.
( ) Baseia-se em otimizações com restrições dinâmicas fortes, introduzidas no problema por uso de multiplicadores de Largrange; ou fracas, introduzidas no problema como termos ponderados de penalidades.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518296
Algoritmos e Estrutura de Dados
Seja um modelo não linear dado por:
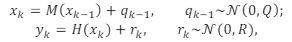
em que: xk é um vetor de estados de n dimensões em um dado instante de tempo K; M e H são mapeamentos não-lineares de Rn para Rn e de Rm para Rm, respectivamente; q e r são vetores aleatórios gaussianos de média nula e covariância Q e R, respectivamente.
Considere a implementação de um Filtro de Kalman por Conjunto (Ensemble Kalman Filter - EnKF) com 1000 pontos representando possíveis estados. Cada um dos 1000 pontos é denotado xt(i), onde i é inteiro e varia de 1 a 1000.
Considere, ainda, que a média dos pontos do conjunto no instante k pode ser representada por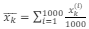 , e que o ganho de
Kalman no instante k é geralmente representado pelo produto de
uma matriz A pela inversa de uma matriz B (Kk = AB−1).
, e que o ganho de
Kalman no instante k é geralmente representado pelo produto de
uma matriz A pela inversa de uma matriz B (Kk = AB−1).
Considerando as condições enunciadas acima, para garantir estimativas de covariâncias não enviesadas, a matriz A pode ser calculada pela expressão:
em que: xk é um vetor de estados de n dimensões em um dado instante de tempo K; M e H são mapeamentos não-lineares de Rn para Rn e de Rm para Rm, respectivamente; q e r são vetores aleatórios gaussianos de média nula e covariância Q e R, respectivamente.
Considere a implementação de um Filtro de Kalman por Conjunto (Ensemble Kalman Filter - EnKF) com 1000 pontos representando possíveis estados. Cada um dos 1000 pontos é denotado xt(i), onde i é inteiro e varia de 1 a 1000.
Considere, ainda, que a média dos pontos do conjunto no instante k pode ser representada por
, e que o ganho de
Kalman no instante k é geralmente representado pelo produto de
uma matriz A pela inversa de uma matriz B (Kk = AB−1). Considerando as condições enunciadas acima, para garantir estimativas de covariâncias não enviesadas, a matriz A pode ser calculada pela expressão:
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518294
Algoritmos e Estrutura de Dados
A utilização de Filtros de Kalman clássicos (Kalman Filters - KF) ou
estendidos (Extended Kalman Filters - EKF) para a assimilação de
dados envolve dificuldades práticas.
Com relação a essas dificuldades, analise as afirmativas a seguir.
I. O EKF é o método otimizado para a assimilação de dados sequencial de um modelo dinâmico linear n-dimensional, sendo o KF apropriado apenas para sistemas unidimensionais.
II. O uso do KF e do EKF em modelos dinâmicos que contam com vetores de estados com muitas dimensões requer alta capacidade computacional e de armazenamento, tornando-os práticos apenas para modelos simplificados, de baixa dimensionalidade.
III. A linearização de modelos não lineares envolve a aproximação de funções matemáticas com o truncamento de séries, o que pode gerar erros de propagação de covariâncias, especialmente em modelos de alta dimensionalidade.
Está correto o que se afirma em
Com relação a essas dificuldades, analise as afirmativas a seguir.
I. O EKF é o método otimizado para a assimilação de dados sequencial de um modelo dinâmico linear n-dimensional, sendo o KF apropriado apenas para sistemas unidimensionais.
II. O uso do KF e do EKF em modelos dinâmicos que contam com vetores de estados com muitas dimensões requer alta capacidade computacional e de armazenamento, tornando-os práticos apenas para modelos simplificados, de baixa dimensionalidade.
III. A linearização de modelos não lineares envolve a aproximação de funções matemáticas com o truncamento de séries, o que pode gerar erros de propagação de covariâncias, especialmente em modelos de alta dimensionalidade.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518293
Algoritmos e Estrutura de Dados
Filtros Bayesianos são métodos usados para estimar o estado de um
sistema dinâmico que seja observado por meio de medidas com
incertezas. Entre os algoritmos utilizados para implementação de
filtros Bayesianos, pode-se citar o Filtro de Kalman clássico, aplicável
a sistemas de modelos lineares e com distribuições Gaussianas de
probabilidade.
Nesse contexto, assinale a opção que indica uma das características do Filtro de Kalman clássico.
Nesse contexto, assinale a opção que indica uma das características do Filtro de Kalman clássico.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518291
Algoritmos e Estrutura de Dados
Texto associado
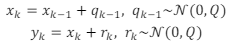
Seja um modelo dinâmico discreto unidimensional de caminhada
aleatória dado por:
Em que xk e yk são, respectivamente, o estado a ser estimado e a
medição no tempo k. As variáveis aleatórias qk e rk possuem
distribuição normal com média nula e variâncias Q e R,
respectivamente, ambas iguais a 1. Assuma, ainda, que a distribuição
de probabilidade do estado no tempo k independe da distribuição
de probabilidade dos estados anteriores (i.e., o sistema atende à
propriedade de Markov).
Em um determinado instante de tempo k − 1, o estado estimado
por um filtro de Kalman é dado por 2,5 e sua variância é estimada
em 1,0.
No instante de tempo k, obtém-se uma medição igual a 3,1.
Após agregar a informação proveniente da medição no tempo k, o
valor estimado do estado para esse mesmo instante k será
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518289
Algoritmos e Estrutura de Dados
Texto associado
Seja um modelo dinâmico discreto unidimensional de caminhada
aleatória dado por:
Em que xk e yk são, respectivamente, o estado a ser estimado e a
medição no tempo k. As variáveis aleatórias qk e rk possuem
distribuição normal com média nula e variâncias Q e R,
respectivamente, ambas iguais a 1. Assuma, ainda, que a distribuição
de probabilidade do estado no tempo k independe da distribuição
de probabilidade dos estados anteriores (i.e., o sistema atende à
propriedade de Markov).
Em um determinado instante de tempo k − 1, o estado estimado
por um filtro de Kalman é dado por 2,5 e sua variância é estimada
em 1,0.
No instante de tempo k, obtém-se uma medição igual a 3,1.
Nessas condições, antes de se agregar a informação proveniente da
medição no instante de tempo k, a predição do estado para esse
mesmo instante k será
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518288
Algoritmos e Estrutura de Dados
Os Filtros Bayesianos são assim chamados por basearem-se na
aplicação do Teorema de Bayes, que relaciona distribuições de
probabilidade a priori com distribuições de probabilidade a
posteriori.
Há dois passos fundamentais para a estimação de estados, onde o primeiro passo está associado ao modelo dinâmico do sistema ou processo, enquanto o segundo passo está associado ao modelo de observações ou sensoriamento.
Neste contexto, os passos são denominados, respectivamente,
Há dois passos fundamentais para a estimação de estados, onde o primeiro passo está associado ao modelo dinâmico do sistema ou processo, enquanto o segundo passo está associado ao modelo de observações ou sensoriamento.
Neste contexto, os passos são denominados, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518285
Algoritmos e Estrutura de Dados
Algoritmos de estimação aplicados a assimilação de dados requerem
a solução de um problema de otimização.
Assinale a opção que indica o método que pode ser considerado híbrido.
Assinale a opção que indica o método que pode ser considerado híbrido.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518283
Algoritmos e Estrutura de Dados
Uma pesquisa sobre a dispersão espacial do risco de ocorrência de
um determinado fenômeno utilizou a estimação Bayesiana como
método de estimação.
Sobre esse método de estimação, assinale a opção correta.
Sobre esse método de estimação, assinale a opção correta.
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517619
Algoritmos e Estrutura de Dados
O cientista de dados Pedro trabalha em um projeto que envolve a
previsão dos movimentos de um braço robótico em um ambiente
complexo. Pedro tem um fluxograma de um algoritmo de
aprendizado por reforço que é capaz de se adaptar
dinamicamente ao ambiente e ajustar suas ações com base nos
resultados de ações anteriores.
O algoritmo representado pelo referido fluxograma que deve ser empregado para a realização da tarefa de Pedro é o:
O algoritmo representado pelo referido fluxograma que deve ser empregado para a realização da tarefa de Pedro é o: