Questões de Concurso
Comentadas sobre estatística descritiva (análise exploratória de dados) em estatística
Foram encontradas 869 questões
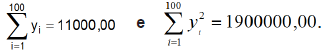 e .
Assuma que a variável gastos semanais
com alimentação na cidade pesquisada
tem distribuição de frequências em forma
de sino (simétrica em torno da média)
e assinale a alternativa que apresenta
o desvio-padrão e a porcentagem das
residências que se espera que seus
gastos estejam nos intervalos
e .
Assuma que a variável gastos semanais
com alimentação na cidade pesquisada
tem distribuição de frequências em forma
de sino (simétrica em torno da média)
e assinale a alternativa que apresenta
o desvio-padrão e a porcentagem das
residências que se espera que seus
gastos estejam nos intervalos 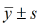 ,
,
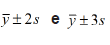 (aproximadamente)
(aproximadamente)
Para um estudo com o objetivo de previsão, optou-se pela utilização do modelo de regressão linear múltipla Yi = α + β1 X1i + β2 X2i + … + βk Xki + ui, i = 1, 2, …, n.
Tem-se que:
I. Y é a variável dependente,
II. X1 , X2 , …, Xk são as variáveis explicativas,
III. α, β1 , β2 , …, βK são os parâmetros desconhecidos do modelo com as respectivas estimativas obtidas pelo método dos mínimos quadrados,
IV. u é o erro aleatório,
V. i corresponde a i-ésima observação, n é o número de observações e k o número de variáveis explicativas.
Se foi detectado neste modelo um problema de multicolinearidade, então
Uma população é formada pelo número de peças vendidas de um produto por uma indústria durante os 10 primeiros meses de um determinado ano e pode ser visualizada pela tabela a seguir. Esta tabela também fornece as informações dos respectivos valores do número de peças vendidas elevados ao quadrado.
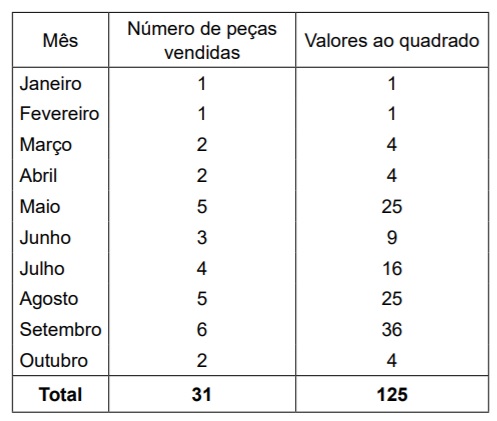
Com relação aos dados desta tabela, o valor da soma da média aritmética (número de peças vendidas por mês) com a moda e com a mediana supera o valor do respectivo desvio padrão em
Considere a tabela-1 e o enunciado seguintes para responder à questão.

A tabela-1 de distribuição de frequência mostra a organização e síntese de 18 dados xi
colhidos como amostra para um
estudo estatístico, onde a coluna ƒi
é a que registra os valores das frequências, enquanto a coluna  contém os
valores dos quadrados dos desvios.
contém os
valores dos quadrados dos desvios.
Considere a tabela-1 e o enunciado seguintes para responder à questão.
A tabela-1 de distribuição de frequência mostra a organização e síntese de 18 dados xi
colhidos como amostra para um
estudo estatístico, onde a coluna ƒi
é a que registra os valores das frequências, enquanto a coluna contém os
valores dos quadrados dos desvios.
Os seguintes dados amostrais foram obtidos de uma pesquisa que buscou saber o comportamento de determinada ação cotada em bolsa de valores no decorrer de nove pregões.

Considerando apenas os dados amostrais apresentados, é correto afirmar que:
- Estimador obliquidade (ou assimetria, distorção, skewness): definido pelo terceiro momento central normalizado pelo estimador do desvio padrão ao cubo; - Coeficientes de assimetria de Pearson: calculados através da diferença entre os valores de média e moda (primeiro coeficiente), ou média e mediana (segundo coeficiente), ambas normalizadas pelo estimador do desvio padrão.
Considere os histogramas de frequência obtidos abaixo:
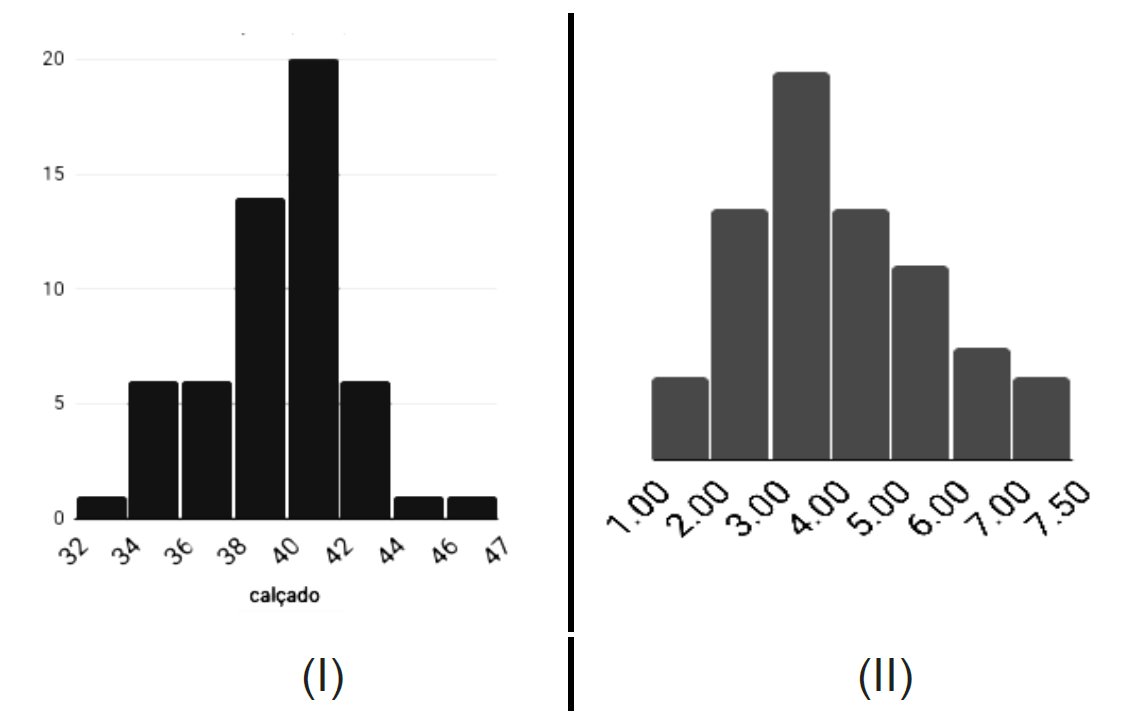
Sobre a análise de assimetria nos histogramas de frequência acima, analise as afirmativas abaixo e dê valores Verdadeiro (V) ou Falso (F).
( ) Os coeficientes de assimetria de Pearson serão negativos para I e positivos para II. ( ) Os coeficientes de assimetria de Pearson irão diferir no sinal no caso II, levando à uma situação inconclusiva. ( ) A análise por meio do coeficiente de obliquidade indicará assimetria positiva para I e negativa para II.
Assinale a alternativa que apresenta a sequência correta de cima para baixo.
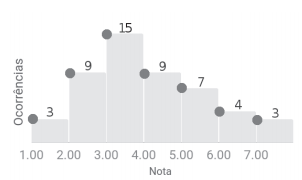
Assinale a alternativa que corretamente apresenta os valores da média, mediana e moda que descrevem esses dados.
A sequência a seguir é crescente e corresponde ao tempo em minutos que 8 alunos levaram para fazer uma prova de matemática:
22, 23, 27, x, y, 36, 39, 41, sendo x e y inteiros.
Sabe-se que a moda é 36 min e que a mediana é 32 min. É correto concluir que
Para avaliar a satisfação dos servidores públicos de certo tribunal no ambiente de trabalho, realizou-se uma pesquisa. Os servidores foram classificados em três grupos, de acordo com o nível do cargo ocupado. Na tabela seguinte, k é um índice que se refere ao grupo de servidores, e Nk denota o tamanho populacional de servidores pertencentes ao grupo k.
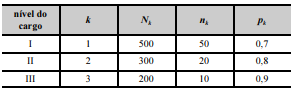
De cada grupo k foi retirada uma amostra aleatória simples sem reposição de tamanho nk; pk representa a proporção de servidores amostrados do grupo k que se mostraram satisfeitos no ambiente de trabalho.
A partir das informações e da tabela apresentadas, julgue o próximo item.
Com relação ao grupo k = 2, o erro padrão da estimativa da
proporção dos servidores satisfeitos no ambiente de trabalho
foi inferior a 0,1.
Em uma fila para atendimento, encontram-se 1.000 pessoas. Em ordem cronológica, cada pessoa recebe uma senha para atendimento numerada de 1 a 1.000. Para a estimação do tempo médio de espera na fila, registram-se os tempos de espera das pessoas cujas senhas são números múltiplos de 10, ou seja, 10, 20, 30, 40, ..., 1.000.
Considerando que o coeficiente de correlação dos tempos de espera entre uma pessoa e outra nessa fila seja igual a 0,1, e que o desvio padrão populacional dos tempos de espera seja igual a 10 minutos, julgue o item que se segue.
Para a estimação do tempo médio de espera, a fração amostral
adotada na referida situação será superior a 0,12.
Em uma fila para atendimento, encontram-se 1.000 pessoas. Em ordem cronológica, cada pessoa recebe uma senha para atendimento numerada de 1 a 1.000. Para a estimação do tempo médio de espera na fila, registram-se os tempos de espera das pessoas cujas senhas são números múltiplos de 10, ou seja, 10, 20, 30, 40, ..., 1.000.
Considerando que o coeficiente de correlação dos tempos de espera entre uma pessoa e outra nessa fila seja igual a 0,1, e que o desvio padrão populacional dos tempos de espera seja igual a 10 minutos, julgue o item que se segue.
A situação em tela descreve uma amostragem sistemática.